




- @kingsoftcloud
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在于它并没有PRM,不对中间的生成步骤做任何干预(MCTS也没用)就是让模型自己的生成COT,然后因为模型被教育要一直思考,就不停的生成,生成多了,突然就到了一个“Aha”时刻,问题就被解答了,其实简单讲就式这个意思,不断的循环RL,对你要做的police,这个policy在这里就指带最初的V3,因为它是个在线的RL,不断的优化策略逼近 output reward最高的标准(它连reward模型都

vscode claude 3.7 支持了,agent支持了,MCP也支持了,感觉以后cursor啥的有点难了,codebase其实做的都差不多。我本身是Mac版本1.99居然没更新agent,所以我就直接用1.100版本的vscode inside了来掩饰一下了。测试连通性就问问它一些普通问题,例如有没有什么通知之类的,就可以了。把我的邮箱和个人信息都传上去了,吓得我赶紧删了,我的代码里是没有。

它的意义为,一个状态-行动对 (s, a) 的最优价值,等于所有可能的下一个状态 s' 的最优价值的期望值,而下一个状态的最优价值,是通过在下一个状态选择 最优行动 来达成的。一个状态-行动对 (s, a) 的价值,等于所有可能的下一个状态 s' 的价值的期望值,而下一个状态的价值又取决于策略 π 在该状态下选择不同行动的概率以及这些行动对应的动作价值。贝尔曼方程通过期望处理这种不确定性。这个方程
例如,如果代理选择“上 (UP)”,则向上移动的概率为 0.8,而向左移动的概率为 0.1,向右移动的概率为 0.1(因为左和右与上是直角方向)。然而,在某些上下文中,奖励函数也可以定义为R(s, a, s’),表示从状态s通过动作a转移到s’后的奖励,这取决于具体问题设置。A是动作空间,可能在每个状态s下有不同的可用动作集合A_s。状态S(States):系统可能处于的所有情况或配置,例如在一个
该分支在输入序列中维护一个固定大小的窗口,对窗口内的 token 进行常规的注意力计算,确保模型能敏感地捕捉到近邻之间的细节和依赖关系,从而防止在全局稀疏化处理时局部信息被遗漏,这个就没什么特别可讲得了。在传统的注意力机制中,随机的内存访问会造成较大的延迟,而 NSA 的选择分支通过对连续块的选择,有效避免了这种问题,确保了硬件的高速缓存(cache)和带宽能得到最优利用,从而进一步提高计算速度(
那什么是粗暴的控制LLM的幻觉的方法呢?正常你们大家学到的应该是top_k=1top_p=0.1类似这种的但是这种是不是能解决幻觉呢?很显然在做的各位试过,应该是没什么效果的为什么呢?正常来讲,我们不是把生成next token的概率放到最大的那个token上了吗?今天先回忆个概念LLM是靠什么来决定next_token生成的就是Logit,就是softmax你的前向计算的最后一层(这么表达不精确
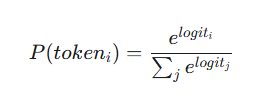
做算力的人天又塌了!!!(这个正月,塌好几次了)https://arxiv.org/pdf/2501.19393李飞飞团队刚刚发布的论文,仅仅用了 1000 个样本,用了 16 块 H100,在 26 分钟就训练完成了可以匹敌 o1-preview 的模型。但是具体的情况?本着本 blog 一贯认真负责的追求事实真相的原则,我抽丝剥茧展开说一下。S1 这个模型的训练方法基础模型性能很好 Qwen2
vscode claude 3.7 支持了,agent支持了,MCP也支持了,感觉以后cursor啥的有点难了,codebase其实做的都差不多。我本身是Mac版本1.99居然没更新agent,所以我就直接用1.100版本的vscode inside了来掩饰一下了。测试连通性就问问它一些普通问题,例如有没有什么通知之类的,就可以了。把我的邮箱和个人信息都传上去了,吓得我赶紧删了,我的代码里是没有。
2- Deepseek 有非常好的文学造诣和情商,用它来进行创作简直无敌,在deepseek这么火的今天,大家使用的很多endpoint其实服务的并不是完整的600B,而是其他蒸馏版本,在这里你可以使用到原生的deepseek的古灵精怪能力。我刚才的mate就默认开启了 高级visualization强化的能力,让AI给你的答案不光是答案,还会以具像化的图标来呈现,有更强的表现能力。WC,这个悲伤
这几周比较忙,也没看啥也没写啥(主要在打街霸6的天梯),但是这个论文我扫了一眼还是有价值的,所以给大家解读一下这个论文:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/其实对于这个解决了什么问题,没那么抽象比如让gpu算一个浮点数,基本算几次可能结果都不一样。浮点数最后影响了概率,概率分布和采样影