




- @jimmyleeee
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
StrandsAgents是一个面向生产级多智能体AI系统的开发框架,支持快速构建安全可扩展的智能体应用。核心优势包括:模型无关性(支持主流LLM及本地Ollama模型)、AWS原生集成、简洁的多智能体协作模式(如任务交接/群体智能)。典型应用场景涵盖智能客服、安全自动化等领域,案例显示可显著提升效率(如Eightcap问题处理时间从30分钟降至45秒)。但存在成本控制、性能延迟等挑战,需注意生产

本文系统介绍了ClaudeAI的四种协作机制:Command(用户手动触发的快捷指令)、Skill(AI自动加载的专业知识包)、Sub-agent(独立运行的子任务处理器)和Hook(事件驱动的自动化流程保障)。这些机制各具特点:Command提供简洁操作入口,Skill实现知识按需注入,Sub-agent隔离复杂任务,Hook确保流程安全可靠。文章通过代码提交场景展示了四者的协同工作模式:用户输

MCP服务器就像一座桥梁,将AI模型(如Claude、Cursor)与你私有的、充满价值的数据源(尤其是数据库)安全地连接起来。但面对GitHub上数百个数据库MCP服务器,哪个才是“最好”的?答案并非唯一,因为“最好”取决于你的数据库类型、使用场景和技术偏好。本文将为你梳理出一套清晰的选型框架,并深入盘点2026年最值得关注的数据库MCP服务器,助你找到最适合自己的那一款。

随着自主AI智能体的发展,传统安全威胁建模方法难以应对其独特挑战。本文系统梳理了主流AgentAI威胁建模框架(如MAESTRO、AWS矩阵、ASTRIDE等),分析其核心理念、优势及适用场景。MAESTRO提供七层系统性架构,AWS矩阵明确责任边界,ASTRIDE实现自动化分析,NVIDIA框架侧重动态对抗测试,CBRA量化风险,OWASP工具则增强标准化评估。不同框架适用于开发者、安全团队或管

大模型量化技术:效率与性能的平衡艺术 大语言模型规模扩张带来了巨大的计算挑战,量化技术成为解决内存占用、推理速度和部署门槛三大痛点的关键手段。本文系统阐述了量化技术的核心原理与实践方法:1)区分训练后量化(PTQ)与量化感知训练(QAT)两种范式;2)详解FP32到INT8的转换机制与校准策略;3)对比均匀/非均匀量化方法及混合精度等精度恢复技术;4)提供主流工具生态与Llama3量化实战示例。研

本文针对Claude使用成本高的问题,从计费机制到实战技巧提出系统化解决方案。核心内容包括:1) 理解中英文token差异和双向计费模式,建议根据任务复杂度选择模型;2) 输入侧通过记忆协议、网页清洗、精准Prompt和文件精简降低冗余;3) 输出侧采用Caveman压缩技术和RTK工具过滤命令输出;4) 利用Prompt缓存、会话清理和模型切换优化长期成本。实测显示这些方法可减少60%-90%的

在原型聚类中,属于某一簇的数据与定义这一簇的原型的点具有更近的距离或更大的相似性,而与属于其他簇的原型点具有较远的距离或较小的相似性。数据点分布密集的区域,拥有较高的密度;在聚类树中,不同类别的原始数据点是树的最低层,树的中间结点是聚合的一些簇,树的根结点对应多数据点的聚类。对于原型聚类算法的实现,通常要先对原型进行初始化,确定每个簇的中心点,然后计算属于每个簇的数据点划分,最后根据新计算的簇,计
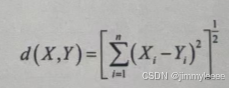
不论神经网络的层数有多少,任何线性函数的线性组合仍然是线性的,在一张纸上证明它是正确的并不难。使用非线性激活函数,可以将线性作用变成非线性作用,在输入输出之间生成非线性映射,使神经网络更加复杂,可以表示输人输出之间非线性的复杂的任意函数映射,可以描述复杂的表单数据,甚至可以具有学习复杂事物的能力。激活函数(Activation Function)又称激励函数,是在人工神经网络(Artifcial

在机器学习的领域里,损失函数(Loss Function)如同一位严苛的导师,既为模型指引优化方向,又严格衡量其预测能力。本文将从定义、常见类型、优缺点到适用场景,为您全面解析这一核心概念。
随机变量的分布研究的是随机变量在某些离散点或某个区间取值时的概率,即概率分布或分布律,主要包括正态分布、二项分布、泊松分布、均匀分布、卡方分布、Beta 分布等。