




- @hustyichi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一般情况下我们不需要进行开源项目的二次开发,因为开源项目往往会提供良好的封装,可以通过依赖包或 API 服务的形式引入项目中。如果开源项目存在一些问题,我们往往可以通过给开源项目提供 PR 来解决,这样就可以尽可能减少二次开发开源项目的问题。但是某些情况下可能会需要基于开源项目开发自己的服务,需要一个相对长周期二次开发。不需要开源项目后续的更新,这种情况比较简单,直接拉取代码进行开发就好,当然要注
自 2025 年下半年以来,AI 编程技术迎来了爆发式发展, AI 编程也逐渐从编程的补全演进化自主 Agent 编程。然而尽管大模型在代码生成能力上突飞猛进,它们在实际应用中依然呈现出一种现象:在小型项目或从零开始的新项目中表现优异,但在面对历史包袱重、逻辑复杂的大型代码库时,往往显得有些力不从心。这一困境的核心原因在于:大型项目通常存在庞大而复杂的上下文依赖。实际开发中需要考虑的代码约束、全局
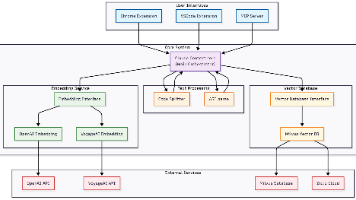
在上周梳理了基于 RAG 的大型代码库解决方案后,本周继续探索另一种方案——基于图谱(Graph)的大型代码库解决方案Graphify。历史似乎总在惊人地重复:几年前 RAG 遭遇规模瓶颈时,微软推出了GraphRAG,将传统的向量检索升级为知识图谱检索。如今在 AI 编程领域,同样的模式再度上演——为了解决大型代码库中的上下文记忆问题,RAG 与 GraphRAG 先后登场。Graphify 正

自 2025 年下半年以来,AI 编程技术迎来了爆发式发展, AI 编程也逐渐从编程的补全演进化自主 Agent 编程。然而尽管大模型在代码生成能力上突飞猛进,它们在实际应用中依然呈现出一种现象:在小型项目或从零开始的新项目中表现优异,但在面对历史包袱重、逻辑复杂的大型代码库时,往往显得有些力不从心。这一困境的核心原因在于:大型项目通常存在庞大而复杂的上下文依赖。实际开发中需要考虑的代码约束、全局
2025 年是大模型应用爆发的一年。从年初的 DeepSeek 吸引大量开发者部署大模型产品,到 Manus 和 MCP 等 Agent 方案持续引发关注,行业内掀起了一股打造爆款大模型应用的热潮。然而,在这股热潮中,大模型的安全性问题往往被忽视。事实上,AI 应用的安全性是实现完整大模型应用的关键环节。2024 年的一篇文章中,曾介绍过大模型应用的完整架构:其中,安全模块主要包括输入围栏(Inp

一般情况下我们不需要进行开源项目的二次开发,因为开源项目往往会提供良好的封装,可以通过依赖包或 API 服务的形式引入项目中。如果开源项目存在一些问题,我们往往可以通过给开源项目提供 PR 来解决,这样就可以尽可能减少二次开发开源项目的问题。但是某些情况下可能会需要基于开源项目开发自己的服务,需要一个相对长周期二次开发。不需要开源项目后续的更新,这种情况比较简单,直接拉取代码进行开发就好,当然要注
通过上面的内容,将 Flower 框架的动手实践以及对应的实现细节都介绍到了,主要涉及到 Flower 三大核心组件中的 Strategy 与 FL loop,而 ClientManager 目前没有过多展开,这部分主要用于管理客户端的连接,有兴趣的可以自行去探索下。从目前来看,Flower 基本上是一个最精简的横向联邦学习的实现方案了,通过必要的抽象简化,Flower 将横向联邦用简单易用的方式

之前在做大模型知识库 RAG 优化时,主要参考的都是学术界的论文。最近了解到有道 QAnything 开源了,在线试用之后,效果看起来还不错,燃起了探索其实现细节的兴趣。正好对于 RAG 各个环节的最佳实践存在一些疑问,因此深入查看了有道 QAnything 的完整实现流程,学习下来自工业界大厂有道的实践方案,在这边分享给大家。本文章基于的是 2024-5 月最新的版本v1.4.0,这个项目还在持
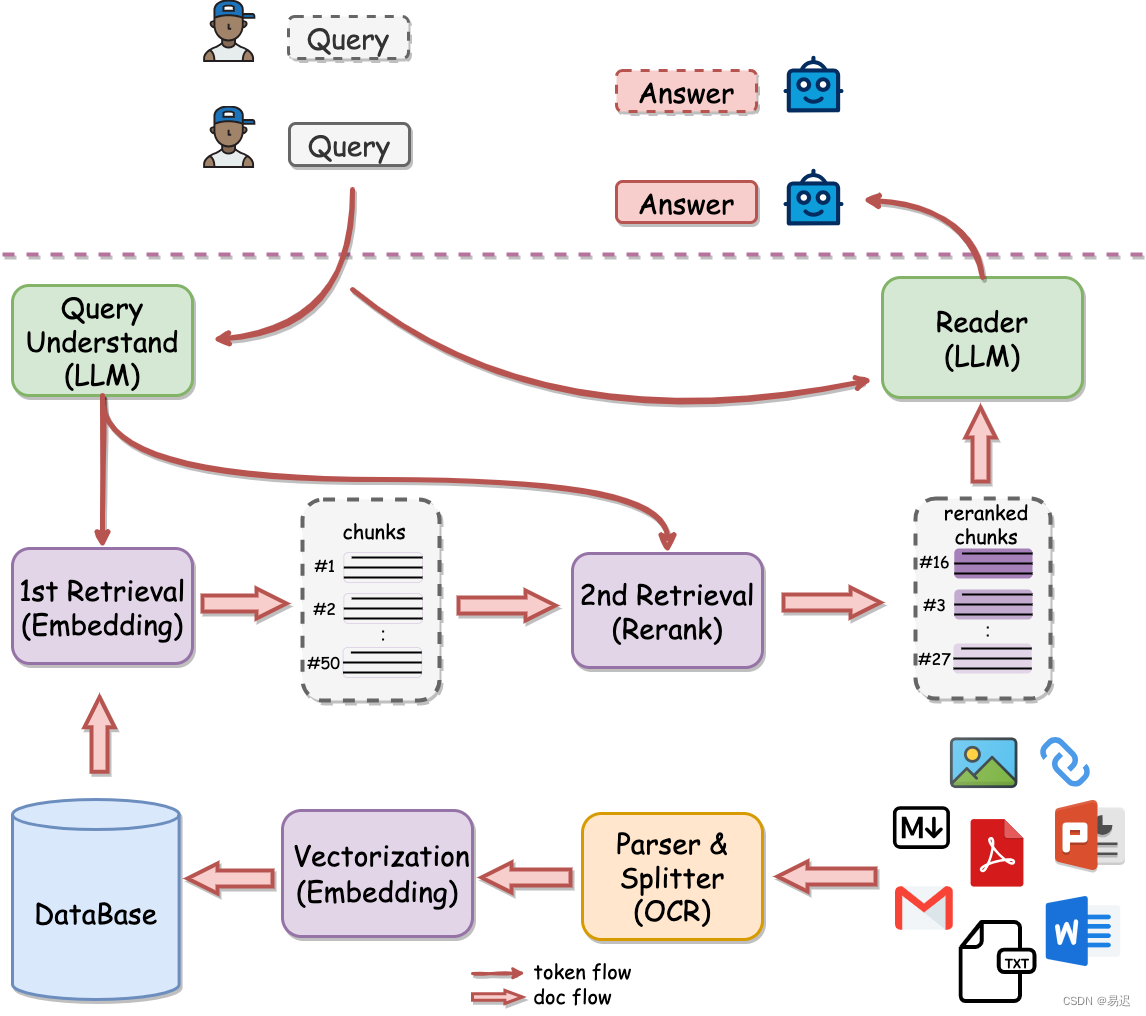
过去几年,持续在医疗领域的大模型应用进行实践探索,个人在大模型技术专栏中持续积累了近 60 篇相关技术博客。过往的实践中,尝试了RAG、Agent、模型微调、知识图谱等多种技术路线,医学通用场景下 RAG 的准确率已由最初的不足 50% 提升至 90% 左右。然而,医学作为高度严谨的应用场景,90% 的准确性依旧无法完全满足生产需求。2025 年以来,进一步聚焦医学细分场景,尝试了不同的场景化大模
最近各种新的大模型辅助科研工具持续出现,在之前的文章中就介绍过NVIDIA 的结构化报告生成方案,最近 OpenAI 也推出了类似的产品,叫做。Deep Research 可以根据需要进行深度的调研与信息整理,但是只有 Pro 用户才能享受到,$200 的价格直接劝退。在调研后发现了开源项目AutoSurvey,相对之前的 NVIDIA 的方案更加完整,不仅包含了完整的报告生成,还能自动生成文献列
