




- @hollow__world
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
参考: 【机器学习】判别模型vs生成模型、概率模型vs非概率模型(1)建立在计算机及其网络上的(2)研究对象是数据(3)目的是对数据进行预测与分析(4)以方法为中心,构建模型->应用模型(5)多学科的交叉,包括概率论,统计学,信息论,计算理论,最优化理论等多个领域。统计学习会将同类数据具有一定的统计规律性作为基本假设。例如一堆看似杂乱无章的数据但是假设其具有某种分布概率考虑学习什么样的模型和如何学
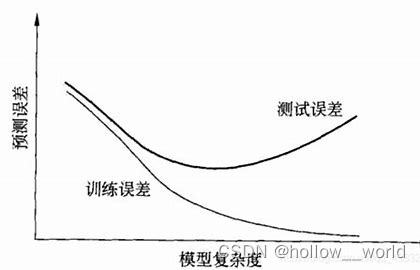
全连接特性:在 Dense 模型中,每一层的每个神经元都与下一层的所有神经元相连,形成一个完全互联的结构[5例如,在一个典型的 Dense 层中,输入数据的每个元素都会被传递到输出数据的每个元素[8全激活模式:对于每个输入数据点,网络中的所有参数(包括连接权重和偏置项)都会被激活并参与计算[5。

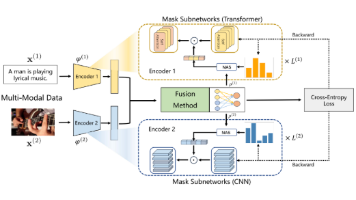
本文提出了一种创新的多模态学习方法AMSS(Adaptively Mask Subnetworks Considering Modal Significance),旨在解决多模态学习中普遍存在的模态不平衡问题。该方法通过细粒度的子网络更新机制,动态调整不同模态的参数更新策略,从而实现更均衡的多模态优化。
全连接特性:在 Dense 模型中,每一层的每个神经元都与下一层的所有神经元相连,形成一个完全互联的结构[5例如,在一个典型的 Dense 层中,输入数据的每个元素都会被传递到输出数据的每个元素[8全激活模式:对于每个输入数据点,网络中的所有参数(包括连接权重和偏置项)都会被激活并参与计算[5。
本文提出了一种创新的多模态学习方法AMSS(Adaptively Mask Subnetworks Considering Modal Significance),旨在解决多模态学习中普遍存在的模态不平衡问题。该方法通过细粒度的子网络更新机制,动态调整不同模态的参数更新策略,从而实现更均衡的多模态优化。
全连接特性:在 Dense 模型中,每一层的每个神经元都与下一层的所有神经元相连,形成一个完全互联的结构[5例如,在一个典型的 Dense 层中,输入数据的每个元素都会被传递到输出数据的每个元素[8全激活模式:对于每个输入数据点,网络中的所有参数(包括连接权重和偏置项)都会被激活并参与计算[5。