- @hh051020
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了自查询检索器在RAG应用开发中的应用,重点探讨了如何根据用户提问自动构建元数据过滤器以提升检索准确性。文章以LangChain中的SelfQueryRetriever为例,展示了如何通过自然语言自动生成查询条件并转换为向量数据库的过滤器。该方法不仅适用于向量数据库,也可类比应用于关系型数据库和图数据库。文章还分析了自查询检索器的运行逻辑,包括提示模板设计、查询语句生成和参数转换过程
2010 年代末以来,人工智能(AI)技术突飞猛进,在 2023-2025 年间更是出现了里程碑式的发展。尤其是通用人工智能(AGI)和AI 自动化方面,全球顶尖研究机构和科技公司投入巨资与精力,推动了一系列前沿突破。本报告将梳理这些年份中 AGI 的最新进展、AI 在自动化领域的演进,以及面临的关键挑战和瓶颈。报告内容基于 OpenAI、DeepMind、Google AI、Anthropic、

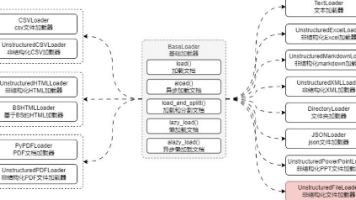
本文介绍了LangChain中的Document类和文档加载器功能。Document类作为核心组件,包含文本内容和元数据,是文档处理流程中的基础数据结构。文档加载器(如TextLoader)负责从不同来源(文本文件、PDF等)提取数据并转换为标准Document格式,屏蔽了文件类型的差异。BaseLoader作为所有加载器的基类,提供了load、aload等统一方法。TextLoader通过ope
本文介绍了如何在LangChain中对接自定义向量数据库。由于向量数据库发展迅速且各具特点,LangChain无法全部集成,因此需要自定义实现。实现方式有两种:继承现有数据库类进行扩展,或继承VectorStore基类对接新数据库。后者需实现三个核心方法:add_texts(添加数据)、similarity_search(相似性搜索)和from_texts(构建数据库)。文章提供了一个基于内存的欧
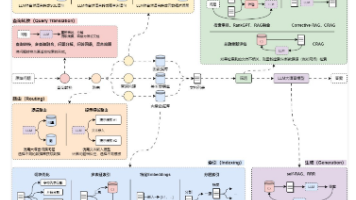
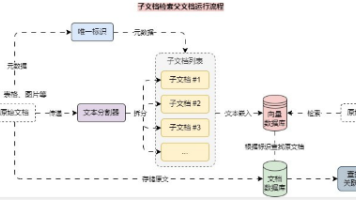
摘要:文章介绍了RAG应用中解决文档拆分与检索冲突的方法。通过"子文档检索父文档"策略,使用小文档块提高嵌入准确性,同时保留大文档块的上下文。LangChain提供的ParentDocumentRetriever工具可实现该功能,支持两种使用场景:1)直接检索原始文档;2)检索中间大小的文档块(非原始文档)。文中给出了具体代码实现,包括文档加载、分割器设置、向量数据库连接和检索
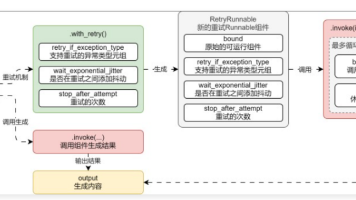
摘要:LangChain提供了Runnable组件的异常处理机制。with_retry()支持对指定异常进行重试,可配置重试次数(默认3次)和指数退避间隔。with_fallback()则实现回退方案,当主组件失败时自动切换到备用组件(如OpenAI失败转文心一言)。两种机制都支持自定义异常类型处理,前者通过循环重试解决临时故障,后者则实现服务降级,确保系统可用性。示例代码展示了如何配置重试次数和
'answer': '根据背景知识,藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫', metadata={'source': './藜.txt'}), Document(page_content='中期管理\n在藜麦8叶龄时,将行中杂
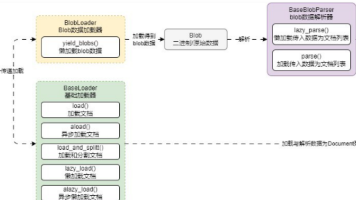
摘要:LangChain引入了Blob方案来处理文档加载和解析,该方案包含Blob、BlobLoader和BaseBlobParser三个核心类。Blob类封装原始数据,BlobLoader负责加载数据,BaseBlobParser则用于将数据解析为文档。通过自定义解析器实现lazy_parse()方法,可以灵活处理不同格式的文件内容。目前该方案仅支持FileSystemBlobLoader,并提
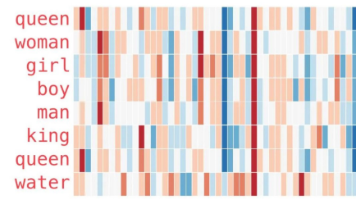
Embedding是一种将高维非结构化数据(如文本、图片、视频)转换为低维向量表示的技术。主流Embedding模型包括Word2Vec、GloVe、FastText和大模型嵌入(如text-embedding-ada-002)。其核心价值在于:降维处理高维数据;捕捉语义信息使相似概念在向量空间相近;支持向量运算(如"女王=国王-男人+女人"的经典示例)。通过可视化向量分布可发
本文介绍了LangChain框架中各类文档加载器的使用技巧。框架内置了上百种文档加载器,包括CSV、HTML、PDF、Office等格式,使用流程均为实例化加载器后调用load()函数。重点讲解了Markdown文档加载器UnstructuredMarkdownLoader的使用方法,包括安装依赖、基础加载和元素分割模式。同时介绍了Office文档(Excel/PPT/Word)加载器的安装配置和