- @gs80140
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
部分内容参考https://blog.csdn.net/bbwangj/article/details/81087911下载helmhttps://get.helm.sh/helm-v2.14.1-linux-amd64.tar.gz上传至centos虚拟机解压mv helm-v2.14.1-linux-amd64.tar.gz移动至bin目录mv...
场景一有这样一个场景:系统中有大约100w的用户,每个用户平 均有3个邮箱账号,每隔5分钟,每个邮箱账需要收取100封邮件,最多3亿份邮件需要下载到服务器中(不含附件和正文)。用20台机器划分计算的压力,从 多个不同的网路出口进行访问外网,计算的压力得到缓解,那么每台机器的计算压力也不会很大了。 通过我们的讨论和以往的经验判断在这场景中可以实现并行计算,但我们还期望能
在网上没看到repo的部署啥的,说的都很简单helm serve就可以启一个,简单的说就是一个web那么nginx也是可以搞的使用k8s部署一个nginx,然后发些包上去进行初始化,记录一下操作过程复制一份mysql的配置文件到html目录向repo中增加软件包, 执行命令helm package mysql --save=false更新index.y...
参考安装文档,本机环境做相应调用https://www.kubernetes.org.cn/5462.html因为本地笔记本只启了一个虚拟机设置主机名hostnamectl set-hostname node0设置主机名解析cat <<EOF >>/etc/hosts192.168.220.128 node0...
参考文章https://www.cnblogs.com/benjamin77/p/9944268.htmlpv =PersistentVolume 存储的定义,生命周期独立于pod,是一块创建好的持久化空间,由管理员管理,应用无需关心,只需要提出申请使用即可pvc =PersistentVolumeClaim存储的声明经过个人的理解pv跟pvc是一一对应关系,pv...
先本地安装本地docker已经有了安装yum install docker-compose下载离线安装包https://github.com/goharbor/harbor/releases这种方式不支持helmchart,重新使用k8s安装helm charthttps://github.com/goharbor/harbor-helm添加源...
在使用go mod的过程中,发现不容易指定版本号尤其是没有打tag的,不知道怎么指定版本号, 不知道有哪版本号正常使用都没有问题,但是当引用的项目用了旧的代码, 这时候必须使用旧的版本,无法指定版本,不知道如何入手尤其是k8s.io不知道是什么鬼, 从哪里看它的代码,只知道github.com这个时候在 go.mod文件中 require 里面加上github.com/kuberne...
手工部署内容参考https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client/deploy下面写一下使用helm部署的方法helm charts在这里https://github.com/helm/charts/tree/master/stable/nfs-client-prov...
安装后, 发现很简单, 遇到的唯一问题就是config-sample.yaml文件的主机一栏,我写重复了,导致安装报错, 脚本找不到。唯一的问题就是在配置文件里我已经打开相关组件的安装了,但是都没有安装。换掉Centos 使用OpenEuler 版本 22.09。应该是我使用的命令不对吧?安装kubesphere 一开始还挺担心的。创建配置,然后使用配置文件创建集群。
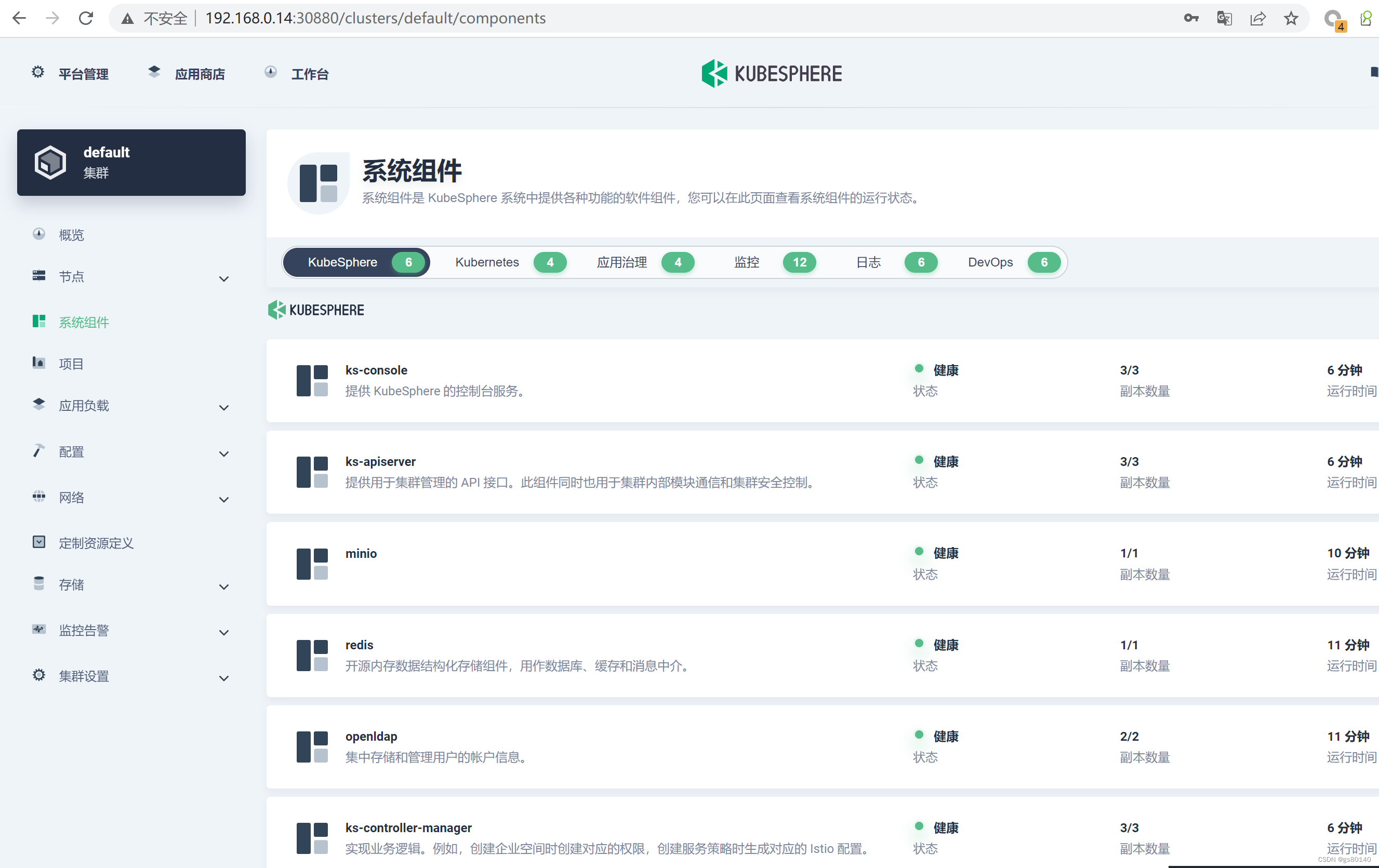
modprobe rbd 测试没有报 "not found"即可。遇到下载不了的情况,使用科学上网机器下载导出并导入。openEuler 版本号: 2209。lsblk 看到没有挂载的磁盘。前置条件 k8s集群版本。