




- @goodness_for_me
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文基于威斯康星乳腺癌数据集,使用随机森林构建乳腺肿瘤良恶性预测模型。实验采用569个样本的30项形态学特征,通过交叉验证得到准确率93.86%,ROC AUC达0.9931。特征分析显示"最严重凹点数量"最具判别力,且"最坏情况"特征比平均值更具预测价值。研究强调该模型不宜直接用于临床诊断,但可作为辅助筛查工具。项目提供完整代码与可视化结果(混淆矩阵、ROC曲线、特征重要性等),重点探讨了医疗场

本文基于scikit-learn Digits手写数字数据集,使用随机森林构建10分类模型,实现了96.67%的准确率。研究通过混淆矩阵分析发现数字8最难识别(Recall仅0.86),其易与1、7混淆。创新性地将Permutation Importance映射为8×8像素热力图,揭示模型主要关注图像中心区域(特别是第21号像素),该位置恰为数字笔画交汇点。实验提供了完整的可复现代码和可视化结果,

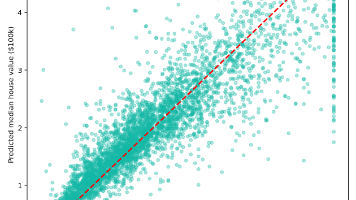
摘要:本项目基于加州房价数据集,使用随机森林回归模型预测房价中位数。实验涵盖数据探索、模型训练与评估等完整流程,最终模型R²达到0.793,RMSE为5.2万美元。特征重要性分析显示地区收入中位数(MedInc)是最强预测因子,重要性超其他特征两倍以上。虽然模型误差率约25%不适合直接交易决策,但可作为市场分析的baseline。项目提供完整可复现代码与可视化结果,包括预测散点图、残差分布和特征重
本文介绍了一个基于Wine Quality数据集的机器学习实验,使用随机森林模型预测高质量葡萄酒(quality≥7)。实验重点关注数据分布、模型选择和结果分析:原始数据呈现明显的类别不平衡(高质量酒仅占19.66%),通过class_weight参数处理不平衡问题;模型最终取得82%准确率,但对高质量酒的识别精度较低(precision=0.53),表现出"宁可错杀不可放过"的特点;特征重要性分
