




- @gaopursuit
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
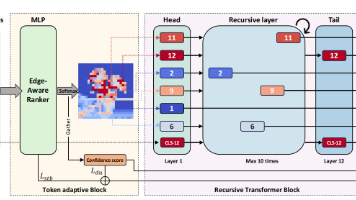
结构为MLP,输出为1~12的值,即每个 token 在 Transformer block 迭代次数。本模块精准识别边缘、纹理、轮廓等语义丰富的 token,进行多轮特征提取,分配更多迭代次数。模型整体框架如下图所示,输入图像划分为 patch,转化为 token,然后输入Edge-Aware Ranker。):全局参数共享,根据 EARR 分配的深度,令牌迭代对应次数;高信息边缘令牌迭代次数更
该论文提出一种针对恶劣天气图像复原的新方法,通过结合莫顿序遍历和状态空间模型,设计了双退化估计模块(DDEM)来解耦全局和局部退化特征。DDEM输出全局退化描述子和空间自适应核,动态调制MOS2D模块的特征处理,实现上下文感知和空间自适应的图像复原。模型通过多阶段下采样、MDSL层和上采样重建清晰图像。实验表明,该方法能有效处理雨、雾、雪等不同天气导致的图像退化问题。

将论文PDF做为附件上传,总结论文的研究动机和创新点。可以得到下面的界面,左边是AI分析结果,右边是论文原文。每一处分析结果后面都有引用(图中标红的部分)。不是参考文献,是论文中的原话,击点即可直接转到论文中对应的位置。
这个论文核心思想认为:多源融合目标检测方法忽略了频率上的互补特征,如可见光图像中丰富的高频细节和红外图像中有价值的低频热信息,从而限制了检测性能。作者的思路是(如下图中的II所示),分别对可见光和红外图像提取高频、低频特征,将二者重新耦合。为此,作者提出了Frequency-Driven Feature Decomposition Network (FD2Net),如下图所示,包括三个部分:特征分
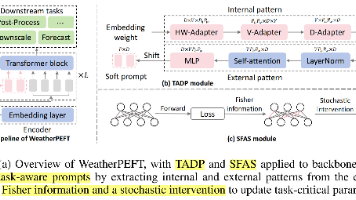
本文提出WeatherPEFT框架,针对天气基础模型(WFMs)参数高效微调问题,设计了任务自适应动态提示(TADP)和随机费雪引导自适应选择(SFAS)两大核心模块。TADP通过多维适配器和自注意力机制处理气象数据的变量异质性和分辨率多样性;SFAS则利用费雪信息矩阵和退火随机策略,动态筛选关键参数进行更新。实验表明,该方法在多个气象任务上仅需微调0.28%-4%参数即可达到或超越全微调性能,显
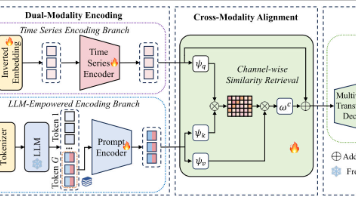
本文提出TimeCMA模型,通过跨模态对齐实现大语言模型(LLM)赋能的多元时间序列预测。针对现有方法直接将时序数据与文本特征拼接导致信息混杂的问题,作者创新性地设计LLM-Empowered编码模块,将时序数据转化为包含时间和数值信息的文本提示,经GPT-2处理提取最具代表性的最后一个token特征。模型采用双模态编码和跨模态注意力融合架构,有效提升了预测性能。实验结果表明该方法优于传统拼接方式
本文提出FuXi-Ocean,首个数据驱动的全球海洋预报模型,实现了6小时时间分辨率、1/12°空间分辨率和0-1500m深度覆盖。针对海洋变量的多尺度时间动态特性,模型创新性地设计了自适应多尺度时间建模架构和Mixture-of-Time模块,通过通道级自适应选择融合多个时间窗口预测结果,有效减轻误差累积。模型仅需9年训练数据,通过物理约束和空间连贯性利用实现高数据效率。实验表明,该模型能自适应
本文提出TimeCMA模型,通过跨模态对齐实现大语言模型(LLM)赋能的多元时间序列预测。针对现有方法直接将时序数据与文本特征拼接导致信息混杂的问题,作者创新性地设计LLM-Empowered编码模块,将时序数据转化为包含时间和数值信息的文本提示,经GPT-2处理提取最具代表性的最后一个token特征。模型采用双模态编码和跨模态注意力融合架构,有效提升了预测性能。实验结果表明该方法优于传统拼接方式
因此,作者考虑在 adaptor 中加入频率域信息,论文的主要工作为设计了一个频率引导的空间注意模块( frequency-guided spatial attention module),使预训练的基础模型从空间域适应,同时由自适应调整的频率分量引导,更多地关注伪装区域。核心思路是把FFT变换以后的频率特征,拆分为一个个独立的 patch,给各个 patch 添加注意力。从图中可以看出,FBNM

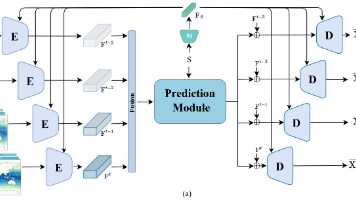
在这个论文中,作者提出了一个通用的时空预测学习框架,其中空间编码器和解码器捕获帧内特征,中间的时域模块捕获帧间相关性。为了并行化时域模块,作者提出了时间注意力单元(Temporal Attention Unit, TAU),它将时间注意力分解为帧内静态注意力和帧间动态注意力。TAU 使用注意力机制来并行化的处理时间演变,该模块将时空注意力分解为:帧内静态注意力和帧间动态注意力。帧间动态注意力本质是
