




- @eagleofstar
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2025年6月6日-7日,将以线上+线下联动的形式召开,4位图灵奖获得者演讲,30余位AI企业创始人&CEO分享,100余位全球青年科学家报告,两天会议将密集开展180余场人工智能主题演讲,在思辨与实证的交织中,为 AI 的未来绘制航图。报名通道已开启。

RoboBrain 是智源研究院推出的面向真实物理环境的“通用具身大脑”系统,集感知、推理与规划于一体,构建了从大脑认知到小脑控制的完整技术体系,包括具身大脑基座模型RoboBrain 2.0、面向3D轨迹生成的RoboBrain-SpatialTrace、用于强化学习稠密奖励生成的RoboBrain-Dopamine、通用小脑VLA模型RoboBrain-X0 Pro,以及灵巧手基座模型Robo
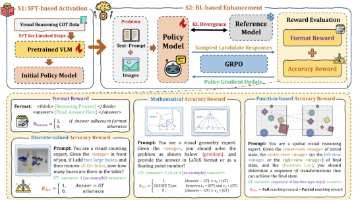
RoboBrain 2.0以卓越的多模态感知、精细的空间推理及强大的长时规划能力,赋能机器人在具身环境中进行交互推理、多智能体协作及高效任务规划,助力复杂物理场景的智能感知与决策。通过这一阶段的训练,模型能够生成推理链,支持复杂任务的逐步推理和决策,从而在具身情境中实现更高效、更准确的推理和规划能力。:整合标准视觉问答、区域级查询、OCR视觉问答及多轮视觉对话,优化语言表达的多样性与语义一致性,通

我们使用 Whisper-large-v2 对每条视频做自动语音识别,获取逐词时间戳的文本,并通过 spaCy 进行停顿切分与句法整理,使视频语言更自然、结构化。长视频蕴含的是更深层次的世界规律,是时空延展的多模态经验(long-horizon multimodal experiences)。这些挑战,本质上也是未来方向:更大规模数据、更先进模型结构、更系统评估方法、更高效 tokenizer,将
此次与乐聚机器人共建联合实验室,将进一步促进具身智能创新生态以及产学研协同发展,支撑具身智能技术产业化。2025年1月13日,北京智源人工智能研究院(简称“智源研究院”)和乐聚(深圳)机器人技术有限公司(简称“乐聚机器人”)正式达成合作,双方将成立具身智能联合实验室,集中优势资源,共同研发面向导览导购、家居康养和工业等应用场景的高性能多模态大模型。未来,智源研究院与乐聚机器人将充分发挥互补优势,共
BGE系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型BGE-VL,进一步扩充了原有生态体系。BGE-VL在图文检索、组合图像检索等主要多模态检索任务中均取得了最佳效果。BGE-VL借助大规模合成数据MegaPairs训练而成。MegaPairs 结合多模态表征模型、多模态大模型和大语言模型,在海量图文语料库中高效挖掘多模态三元组数据。。本次发布的版本涵盖 2600
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。针对这一需求,近日,智源研究院联合多所高校研发了三款向量模型,包括代码向量模型BGE-Code-v1,多模态向量模型BGE-VL-v1.5以及视觉化文档向量模型BGE-VL-Screenshot。这些模型取得了代码及多模态检索的最佳效果,并以较大优势登顶CoIR、Code-RAG、MMEB、MVRB等领域内
秉持“开源开放”精神,智源研究院联合一批全国重点的人工智能芯片企业共建“AI开放生态实验室”,围绕AI芯片进行底层技术联合创新,验证各种AI芯片对超大规模模型训练任务的支持力度,推动AI芯片构建完整的上下游软件生态,为AI芯片的生态发展和创新打造开放合作的平台。截至目前,FlagPerf 已完成来自9家芯片厂商的15款芯片的综合评测。芯片厂商C:“Flagperf 时效性强,紧跟社区动态,添加了

近期,昇腾 AI 与 AI 芯片一体化评测引擎 FlagPerf 完成阶段性适配,共同推进 AI 硬件评测体系建立,赋能大模型技术创新能力提升,加速我国 AI 生态繁荣发展。

2026年1月,北京智源人工智能研究院联合20余家机构推出开源系统软件栈FlagOS 1.6版本,旨在解决AI芯片生态割裂问题。
