




- @dong123dddd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
该代码实现了一个基于腾讯云翻译API的文本翻译功能,主要包括数据库连接配置、腾讯云签名生成和翻译请求处理。核心功能是使用腾讯云机器翻译API将英文文本翻译为简体中文,支持并发请求和失败重试机制(最多3次)。代码详细实现了腾讯云API v3签名算法,包含规范请求串生成、签名字符串拼接和HMAC-SHA256签名计算。翻译结果会截取前200个字符返回,并提供了完善的错误处理机制,包括API错误响应解析
本文分享了高效利用AI编程的渐进式提问方法。核心原则是"由浅入深、信息闭环",分三个阶段:1)明确场景需求,获取整体思路;2)拆解具体实现步骤,获取代码示例;3)寻求优化方案和避坑指南。重点强调精准描述问题(包含技术栈、需求、约束条件)、分层提问(从框架到细节)和即时反馈(引导AI迭代答案)。通过实际案例演示了如何从问题描述到方案获取的完整流程,帮助开发者避免模糊提问和无效响应

AI代码生成能力被高估:Cursor一周生成300万行浏览器代码引热议,但实验显示AI仍无法完全替代人类开发。虽然GPT-5.2在标准化任务上表现优异,但在核心业务逻辑、创新功能等场景仍存在幻觉累积、错误放大等致命缺陷。研究指出,AI代码质量更多依赖人为设计的约束机制(如分层架构、测试驱动),而非自主创造能力。专家建议将AI用于重复性任务、内部工具等低风险场景,但需保持人类对核心业务逻辑的掌控。当
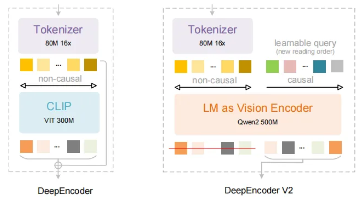
2025-2026年OCR领域迎来开源大模型的黄金时代。DeepSeek开源了基于视觉因果流(Visual Causal Flow)创新的3B参数DeepSeek-OCR-2模型,采用DeepEncoder V2视觉编码器,支持动态阅读顺序处理复杂版面。腾讯同期开源了1B参数的HunyuanOCR,采用端到端一体化设计和XD-RoPE位置编码技术,在轻量化部署方面表现突出。两款模型分别代表了OCR
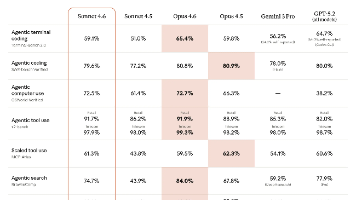
Anthropic推出的Claude 4.6系列包含旗舰级Opus和平衡型Sonnet两款模型。Opus 4.6在深度推理、代码代理能力和长上下文处理上表现卓越,适合高风险复杂任务;而Sonnet 4.6以仅Opus五分之一的价格提供接近旗舰的性能,在用户偏好度、日常开发任务和文档理解方面表现突出。关键差异在于Opus更适合多代理协调和关键系统重构,Sonnet则胜任80%日常场景。优化策略包括P
Anthropic三大AI工具选型指南:Chat、Code与Cowork的核心差异 Anthropic推出的三款Claude系列产品针对不同场景设计: Claude Chat:对话式AI助手,擅长思维碰撞、内容创作与研究分析,支持文档处理但无法直接访问本地文件 Claude Code:终端编程智能体,能自主完成代码编写、测试和版本管理,适合全周期开发但学习成本较高 Claude Cowork:桌面

企业AI应用转型指南:从知识管理到私有化部署 本文系统梳理了大语言模型在企业中的十大核心应用场景,涵盖知识管理、代码生成、营销创作、文档解析、跨语言沟通、教育辅导、数据分析、客服优化、创意策划等领域。重点突破传统效率瓶颈,通过RAG架构、多轮对话设计、长文档分析等技术方案,实现业务场景的智能化升级。针对企业关注的隐私问题,详细介绍了基于开源模型的低成本私有化部署路径,包括模型量化、容器化封装和效果
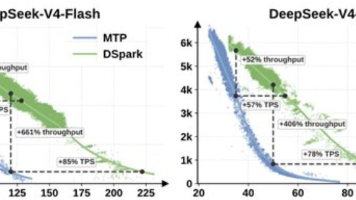
我们推出DeepSeek-V4系列的预览版,其中包括两个强大的混合专家 (MoE) 语言模型——DeepSeek -V4-Pro(1.6T 参数,已激活 49B)和DeepSeek-V4-Flash (284B 参数,已激活 13B)——两者均支持一百万个标记的上下文长度。混合注意力架构:我们设计了一种混合注意力机制,结合了压缩稀疏注意力(CSA)和高度压缩注意力(HCA),以显著提高长上下文效率
在 AI 快速发展的今天,选择变得重要。是选择一个封闭、昂贵但 polished 的产品,还是支持一个开放、免费但仍在成长的社区项目?OpenWork 提供了第二种选择。它证明了 AI 代理不必是黑盒,隐私和便利可以共存,开源社区可以构建商业级的产品。如果你重视数据控制、喜欢折腾、或者只是想探索 AI 代理的无限可能,OpenWork 值得一试。
我们推出DeepSeek-V4系列的预览版,其中包括两个强大的混合专家 (MoE) 语言模型——DeepSeek -V4-Pro(1.6T 参数,已激活 49B)和DeepSeek-V4-Flash (284B 参数,已激活 13B)——两者均支持一百万个标记的上下文长度。混合注意力架构:我们设计了一种混合注意力机制,结合了压缩稀疏注意力(CSA)和高度压缩注意力(HCA),以显著提高长上下文效率