




- @cooldream2009
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
他为大家分享了参加创新赛的作品,封面新闻APP的开发过程,以及在开发中碰到的问题,如何解决的,后面还给大家分享了参赛中需要注意的问题,干货很多,也很实在。这就是我参加鸿蒙线下交流活动的整个过程,如果你对鸿蒙技术开发也有兴趣,不妨了解一下,如果能够参加类似的线下交流活动,也不错过机会,说不定一场活动,就让你对鸿蒙开发产生兴趣,开启一个不一样的技术大门。技术专家马老师分享的是元服务的开发实战,因为没有

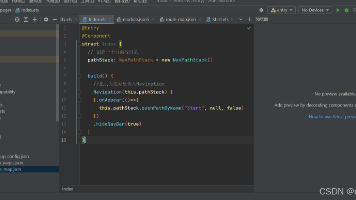
鸿蒙的 **NavPathStack** 提供了完整的页面栈管理能力,结合 **Navigation** 组件,可以轻松实现页面跳转、返回、替换、删除、参数传递以及路由拦截等功能。相比传统的直接引用页面文件方式,鸿蒙推荐使用 **系统路由表**,这不仅降低了页面间的耦合度,也使得应用的可维护性更强。本文将从基础概念入手,结合实际代码案例,对鸿蒙模块内页面路由的实现进行全面讲解,帮助开发者掌握从入门
在企业开发中,随着业务需求的不断增加,开发效率和代码质量成为开发者追求的核心目标。而自动化代码生成工具正是为了解决重复劳动、提升开发效率而设计的。若依(RuoYi)管理系统作为一款开源的快速开发框架,内置了功能强大的代码生成器,可以帮助开发者快速生成符合项目需求的前后端代码。本文将以课程管理模块为例,从环境准备到代码生成,再到项目集成,详细介绍如何利用若依代码生成器高效完成前后端开发。通过本文,你

InvalidArchiveError这个看似简单的报错,背后涉及 Conda 的缓存机制、Windows 文件系统、杀毒软件干扰以及包管理工具的实现差异。本文将围绕这一问题展开系统分析,从问题发现、原因拆解到完整解决流程,帮助你建立一套可复用的排错思维框架,而不仅仅是“照着命令操作”。
**Nginx 已成功部署,首页 HTML 正常返回,Vue 应用也已挂载,但 `#app-container` 内没有任何可见内容**。这种问题往往不会伴随明显的控制台报错,既不像 404 那样直观,也不像 JS 运行异常那样容易定位,排查成本较高。本文结合一次真实的排障过程,从**问题现象、原因分析、解决方案、配置要点与经验总结**几个维度,对该问题进行系统梳理,希望为后续类似问题提供一套可复
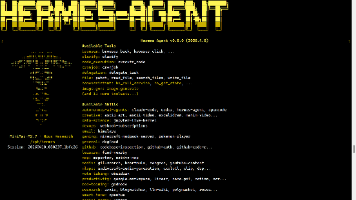
在 AI 技术快速发展的今天,将大模型能力接入企业办公系统已经成为一种趋势。无论是智能问答、自动化办公,还是企业知识库,AI 助手都能极大提升效率。而如何快速、稳定地部署一个可用的 AI 系统,是许多开发者面临的第一道门槛。本文将围绕开源项目 Hermes Agent,手把手带你完成从部署到接入飞书机器人的完整流程。相比零散教程,本文不仅提供详细步骤,还会补充关键原理说明与实践建议,帮助你真正掌握
我会用到的工具栈是 **Claude Code**(终端版 AI 编程助手)+ Next.js 16 + TypeScript + Prisma 5 + SQLite + TailwindCSS 4。文中涉及三个斜杠命令:`/plan`(让 AI 先出方案再动手)、`/init`(生成项目级 CLAUDE.md)、`/security-review`(让 AI 对项目做安全审查)。没用过 Clau
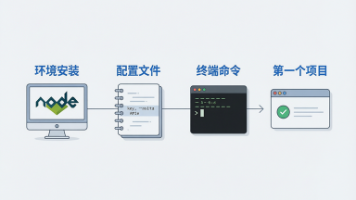
我会带你从零开始:装环境、配 API、敲命令、做出第一个能跑的小工具。全程不用"懂代码",你只需要会打字、会装软件。上一篇《国内访问 AI 编程工具完全指南》讲清了为什么国内用户必须用中转方案,本篇就顺着那条路走——把 Claude Code 真正装进你的电脑、连上国产模型、跑出第一个项目。
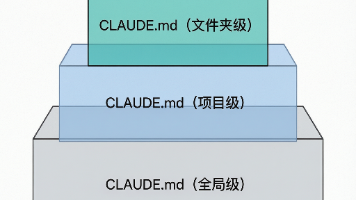
你有没有过这种经历:明明昨天才告诉 Claude Code "我们项目用 TypeScript 严格模式",今天开新会话它又问"用 JavaScript 还是 TypeScript"?明明上次你吐槽过"不要用 class 组件",它这次又写了一个?这不是 AI 记性差,而是你**没有给它一个记笔记的地方**。解决方案就是 **CLAUDE.md**——一个放在项目里的"记忆文件"。这一篇我会彻底讲
"我该选 Claude Code 还是 Cursor?""我们公司用 Qoder 还是 Codex?""学生党用什么最划算?"这三个问题是我被问得最多的。每个 AI 编程工具都有自己的粉丝群体,但**没有银弹**。这一篇我会先拆解 5 款主流工具各自的特点和适用人群,再给出按角色、按场景的选型建议,最后用一张决策图收尾。
