




- @cclovezbf
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因为是分布式计算,累加器在多台机器++,然后最后会聚合一次。或者我们需要的累加值,其实这里和spark的累加器好像是一个意思。所以还是用个tuple,上面也说了uv用set ,pv用int 所以 tuple注意来一个event 就要累加一次,我们既要存uv的信息也要存pv的信息。out 用个tuple。案例-同时计算uv 和pv为, uv是用户访问量,pv是页面点击量。每来一条记录 数据+1 所以
功能上来看都还行,感觉reduce这种在大数据量的情况下更占优势,而process逻辑处理更清楚,因为数据都到齐了我想怎么算怎么算。前面学习了reduceFunction 和aggregateFunction。现在来学习processFunction。后者是窗口内的数据全部到齐了之后一起处理。前者是窗口内的数据来一条处理一条。
差不多就是如下 a join bjoin c join djoin e join f 一长串。说实话我也难搞,每次就是一长串sql让我找问题 让我优化,我看完sql理解下都要十几分钟。。。
以execution_jobs表为例 input_params 和out_params字段类型都是blob那么如何把blob转化为我们需要的类型主要是看mybatis中自带的typehandler这些处理器在检查数据库字段类型的时候,会自动分配合适的typehandler以NStringTypeHandler为例,如果我们数据库是string,javabean也是string@Overridepu
众所周知 hive是字段类型不敏感的,比如date 2022-01-01 和string 2022-01-01 在大多数情况下都是可以呼唤的。而且经过我的测试 oracle的date 和timestamp类型 对应的都是 93也就是timestamp,所以datax在对oracle取数的时候,这两个类型是区分不了的。所以我们一般来说看到这个date 数值就是年月日,但是因为工具看到的也不同 我用d

最近工作需要将oracle的存储过程转化为hive的sql脚本。遇到很多不一样的地方,例如oracle连接中有(+)号的用法。借鉴这篇文章,但是这个排版比较烂。。。先建表和插入数据首先说明(+)代表什么?代表这一侧的数据可以为空!a.id=b.id(+) 代表b表和a表关联的时候以a表作为主表。
用了一个加密算法 反正就是给个key+secret 加密成另外一段文字 不关心加密过程,但是之前都能加密成功,今天加密直接就报错了。感觉最近也没动过这个类,看了git也是原样。灵机一动,因为idea有时候会自己有个默认的jdk版本,是不是我换到其他工程的时候改过这些设置呢?当然上面文章的解决办法也是可以的替换本地的和服务器的这个policy.jar。服务器上的jdk版本是特供的呀。大多数都和这个说
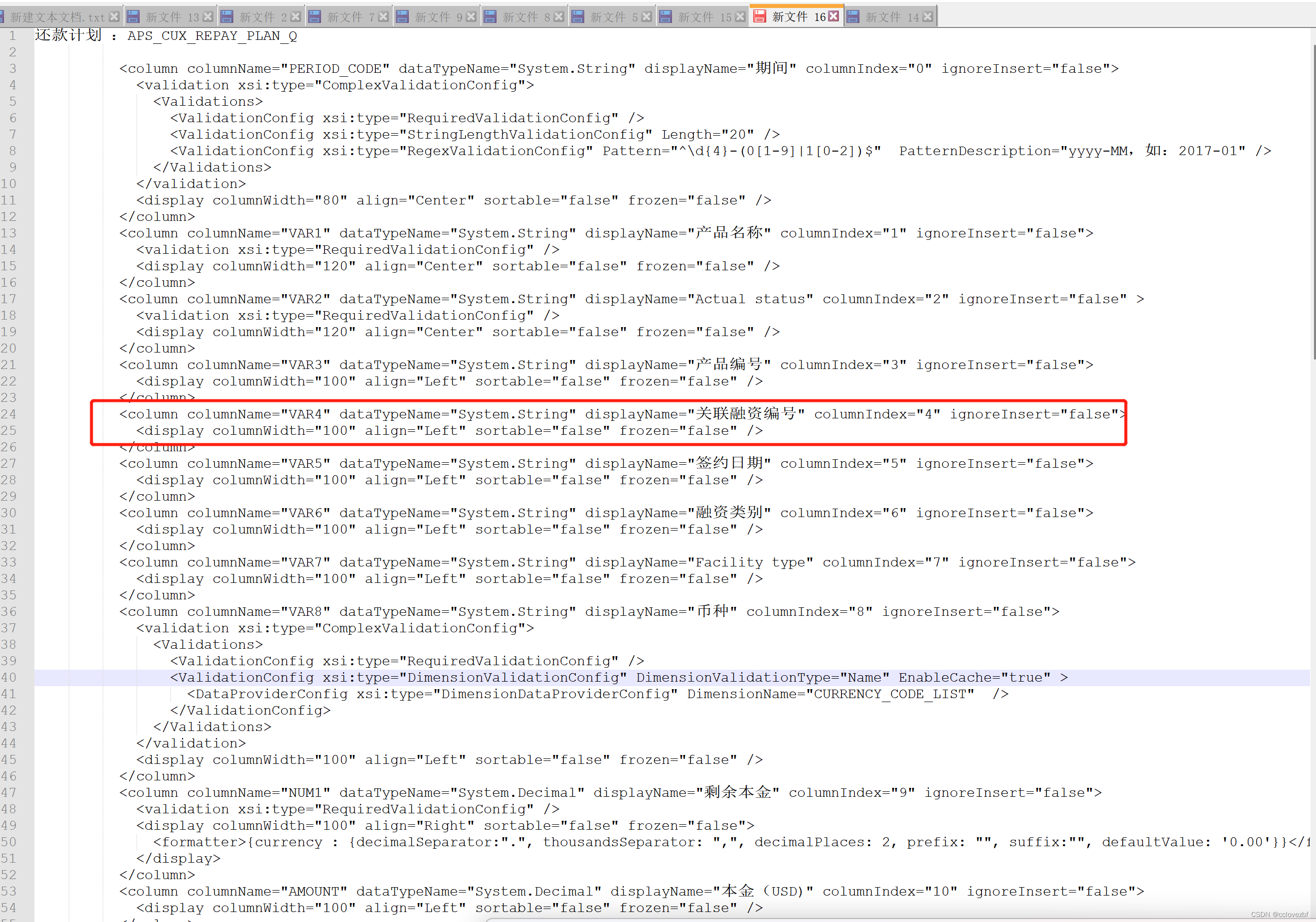
如何从有规律的文字中通过notepad++提取自己想要的内容
这个是连接hive报错的 大概率就是hiveConnection 和hiveDriver里解析hive url 和hive -d xxx=xxx这种时候出错了。背景:用dbeaver连接kerberos认证的hive,之前都是好好的,今天手贱点了下重置结果按照以前的死活连不上报上面的错误,其实这个错以前也遇到过忘了怎么解决的。明明显示了host为啥是null。说实话吧这个源码有点难搞,最近刚好我还
最常见的这个错误是类型转化异常,例如字符串Integer.parseInt("123abc"),abc不能转化为数字,通常在console报错栏可以找到对应位置。 由此在使用hibernate开发的时候 从数据库进进行多表连接查询,使用的是sql方法,查询的字段数据查到了,用List<User> users接收,在向前端传数据过程中mod