




- @adaedwa187545
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
将分布式软总线技术巧妙融入您的应用中,不仅能够显著提升用户体验的广度和深度,还能极大地拓宽应用的适用场景与边界。用户将享受到前所未有的跨设备无缝协同,无论是智能穿戴、智能家居,还是车载系统,都能实现信息的自由流转与服务的无缝衔接,从而探索出更多元、更便捷的生活方式。这样的融合,无疑是对“用户至上”理念的深刻践行,也是HarmonyOS生态繁荣发展的强大驱动力。

软件定时器以Tick为基本计时单位,当用户创建并启动一个软件定时器时,OpenHarmony LiteOS-M内核会根据当前系统Tick时间及用户设置的定时间隔确定该定时器的到期Tick时间,并将该定时器控制结构挂入计时全局链表。软件定时器是系统资源,在模块初始化的时候已经分配了一块连续的内存,系统支持的最大定时器个数由los_config.h中的LOSCFG_BASE_CORE_SWTMR_LI
HDMI(High Definition Multimedia Interface),即高清多媒体接口,是Hitachi、Panasonic、Philips、Silicon Image、Sony、Thomson、Toshiba共同发布的一款音视频传输协议,主要用于DVD、机顶盒等音视频Source设备到TV、显示器等Sink设备的传输。HDMI传输过程遵循TMDS(Transition Minim
关于文件系统的介绍已经写了三篇,但才刚刚开始,其中的 [文件系统篇] 一定要阅读,用生活中的场景去解释计算机各模块设计的原理和运行机制是整个系列篇最大的特点,计算机文件系统相关概念是非常的多的,若不还原其本质,不跳出这些概念去看问题是很难理解它为什么要弄这么些东东出来让你头大. 反之,如果搞明白了这些概念背后的真相你想忘记它们都很难,问题是经不起追问的, 多追问几个为什么就会离本源越来越近.上面提
关联线程组(related thread group)提供了对一组关键线程调度优化的能力,支持对关键线程组单独进行负载统计和预测,并且设置优选CPU cluster功能,从而达到为组内线程选择最优CPU运行并且根据分组负载选择合适的CPU调频点运行。CPU轻量级隔离特性提供了根据系统负载和用户配置来选择合适的CPU进行动态隔离的能力。内核会将被隔离CPU上的任务和中断迁移到其他合适的CPU上执行,
bootstrap_lite部件会编译//base/startup/bootstrap_lite/services/source/bootstrap_service.c,该文件中,通过SYS_SERVICE_INIT将Init函数符号灌段到__zinitcall_sys_service_start和__zinitcall_sys_service_end中,由于Init函数是没有显式调用它,所以需要
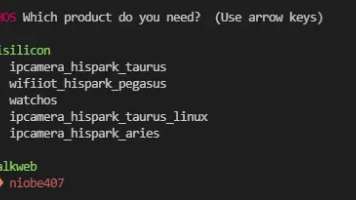
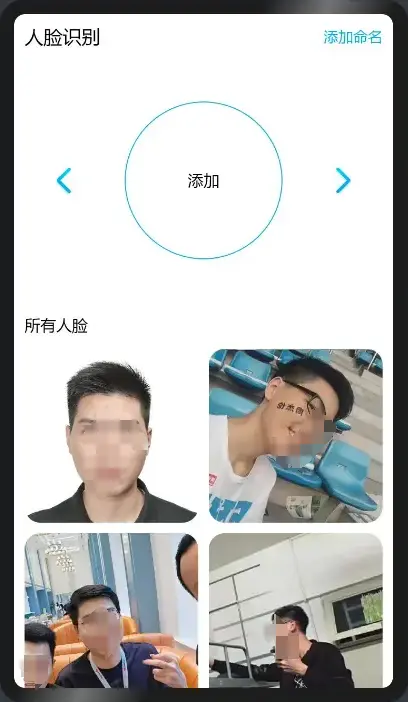
相信大部分同学们都已了解或接触过OpenAtom OpenHarmony(以下简称“OpenHarmony”)了,但你一定没在OpenHarmony上实现过人脸识别功能,跟着本文带你快速在OpenHarmony标准设备上基于SeetaFace2和OpenCV实现人脸识别。
opengauss-driver是纯仓颉语言实现的 openGauss 和 PostgreSQL 数据库驱动。
bootstrap_lite部件会编译//base/startup/bootstrap_lite/services/source/bootstrap_service.c,该文件中,通过SYS_SERVICE_INIT将Init函数符号灌段到__zinitcall_sys_service_start和__zinitcall_sys_service_end中,由于Init函数是没有显式调用它,所以需要
驱动主要包含两部分,平台驱动和器件驱动。平台驱动主要包括通常在SOC内的GPIO、I2C、SPI等;器件驱动则主要包含通常在SOC外的器件,如 LCD、TP、WLAN等图1OpenHarmony 驱动分类HDF驱动被设计为可以跨OS使用的驱动程序,HDF驱动框架会为驱动达成这个目标提供有力的支撑。开发HDF驱动中,请尽可能只使用HDF驱动框架提供的接口,否则会导致驱动丧失跨OS使用的特性。在开始驱