




- @a1105425455
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
numpy:支持大量的维度数组与矩阵运算arrayimport numpy as np#导入库并别名x = np.array([[1,2],[2,3]],int)#创建int型的数组#array([[1, 2],#[2, 3]])x.ndim#维度 2x.shape = (1,3)#几行几列 可改变 x.shape可查看x.dtype#元素类型x.itemsize#每个元素多少字节np.arang
项目背景作为供应链行业领航企业,怡亚通推动供应链改变中国,不仅是以先进的供应链思维与管理推动中国主要核心城市的商业快速发展,也是以完善的供应链服务布局、开放的新流通平台助力中国1-6线城市以及乡镇的流通业进步,振兴中国农村流通经济,以供应链改变中国的时代洪流,推动全中国的发展与进步。上一个十年,怡亚通紧握快消市场高速发展机遇,打造380平台,实现业务规模的千亿级发展;未来,怡亚通将在380平台优势
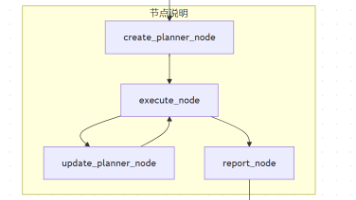
解析gemini-fullstack-langgraph-quickstart项目的后端架构并优化。

解析gemini-fullstack-langgraph-quickstart项目
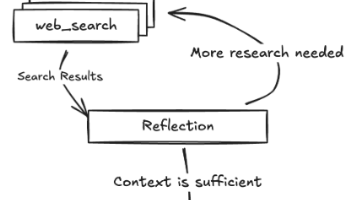
利用langgraph框架构建可分析文档的agent,附源码。
项目背景作为供应链行业领航企业,怡亚通推动供应链改变中国,不仅是以先进的供应链思维与管理推动中国主要核心城市的商业快速发展,也是以完善的供应链服务布局、开放的新流通平台助力中国1-6线城市以及乡镇的流通业进步,振兴中国农村流通经济,以供应链改变中国的时代洪流,推动全中国的发展与进步。上一个十年,怡亚通紧握快消市场高速发展机遇,打造380平台,实现业务规模的千亿级发展;未来,怡亚通将在380平台优势
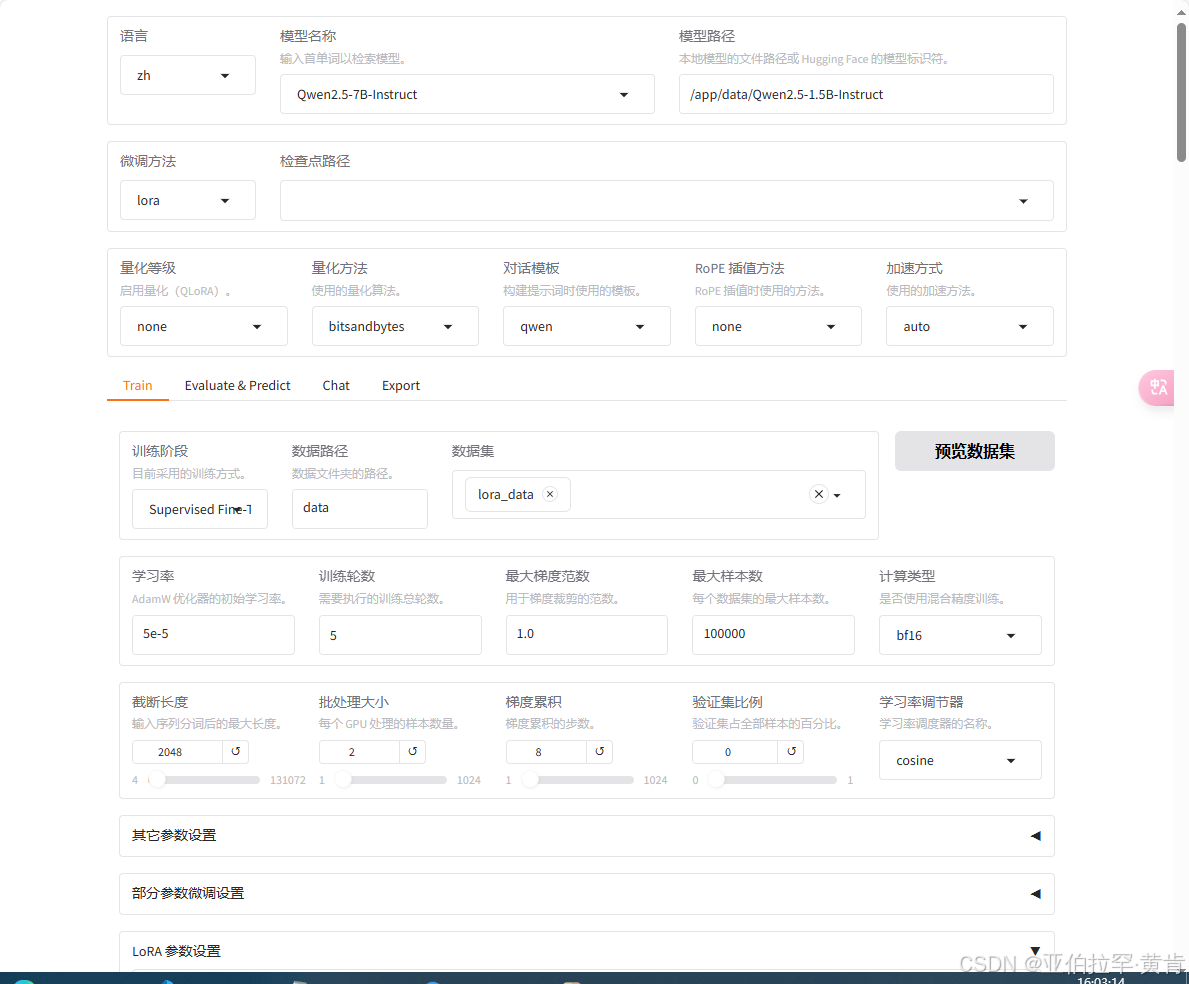
llama-factory微调Qwen2.5-7B-instruct实战,看这一篇就够了!!!(含windows和linux)
本文研究了智能体强化学习(Agentic RL)在文本转有声书任务中的应用。实验采用微软开源的Agent Lightning框架,基于Qwen-1.5b模型进行多轮交互式训练。通过GLM-4.7作为奖励模型,对20条《天龙八部》文本片段进行格式、内容、情感等多维度评估。使用GRPO算法训练后,验证集最佳成绩达到0.552,较基线提升341%。结果表明,Agentic RL能有效提升文本转语音任务的
解析gemini-fullstack-langgraph-quickstart项目