




- @Xixi0864
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
火山引擎推出的Doubao-Seed-Code模型通过企业官网开发实战展现了强大的AI编程能力。该模型能够从模糊商业需求中准确提取功能点,规划标准企业官网架构,并生成符合生产环境标准的完整前后端代码。测试中,模型成功实现了基于SpringBoot的后端API和现代化前端界面,包含公司介绍、服务展示、联系表单等功能模块,代码质量高且具备完整的错误处理。相比传统代码助手,Doubao-Seed-Cod
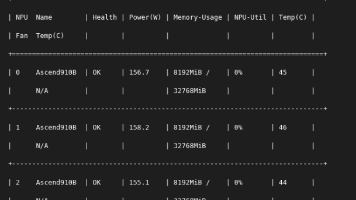
本文探讨了在AI大模型训练中采用昇腾NPU作为GPU替代方案的可行性。通过MindSpeed-LLM框架实践,展示了从环境搭建到模型部署的全流程,重点解决了NPU容器化部署、Python环境配置等技术难点。以Qwen3-0.6B模型为例,实测显示NPU在保持精度的前提下,训练速度提升9%,内存占用降低10%,成本比GPU降低30-40%。虽然NPU生态尚不完善,但在中小规模模型和成本敏感项目中展现
摘要:本文详细介绍基于华为昇腾MindSpeedMM套件的多模态大模型微调全流程。首先概述套件架构及性能优化特性,包括视觉生成、理解模块和全模态处理能力。其次说明环境配置要求,涵盖硬件规格、软件安装及数据集准备。重点阐述模型微调实践,包括投影层和语言模型的分阶段微调方法,并提供评估优化与生产部署方案。最后总结MindSpeedMM在昇腾(149字)
本文探讨了在AI大模型训练中采用昇腾NPU作为GPU替代方案的可行性。通过MindSpeed-LLM框架实践,展示了从环境搭建到模型部署的全流程,重点解决了NPU容器化部署、Python环境配置等技术难点。以Qwen3-0.6B模型为例,实测显示NPU在保持精度的前提下,训练速度提升9%,内存占用降低10%,成本比GPU降低30-40%。虽然NPU生态尚不完善,但在中小规模模型和成本敏感项目中展现
摘要:本文详细介绍基于华为昇腾MindSpeedMM套件的多模态大模型微调全流程。首先概述套件架构及性能优化特性,包括视觉生成、理解模块和全模态处理能力。其次说明环境配置要求,涵盖硬件规格、软件安装及数据集准备。重点阐述模型微调实践,包括投影层和语言模型的分阶段微调方法,并提供评估优化与生产部署方案。最后总结MindSpeedMM在昇腾(149字)
摘要:本文详细介绍基于华为昇腾MindSpeedMM套件的多模态大模型微调全流程。首先概述套件架构及性能优化特性,包括视觉生成、理解模块和全模态处理能力。其次说明环境配置要求,涵盖硬件规格、软件安装及数据集准备。重点阐述模型微调实践,包括投影层和语言模型的分阶段微调方法,并提供评估优化与生产部署方案。最后总结MindSpeedMM在昇腾(149字)
本文探讨了在AI大模型训练中采用昇腾NPU作为GPU替代方案的可行性。通过MindSpeed-LLM框架实践,展示了从环境搭建到模型部署的全流程,重点解决了NPU容器化部署、Python环境配置等技术难点。以Qwen3-0.6B模型为例,实测显示NPU在保持精度的前提下,训练速度提升9%,内存占用降低10%,成本比GPU降低30-40%。虽然NPU生态尚不完善,但在中小规模模型和成本敏感项目中展现
OpenEuler 25.09开发环境深度体验:一名Linux开发者的真实评测 摘要:本文记录了从Ubuntu转向OpenEuler 25.09作为主力开发环境的完整体验。安装过程仅30分钟,UKUI桌面环境简洁高效。开发环境搭建极为便捷,通过简单命令即可配置完整工具链。实测全栈项目开发流畅,系统响应速度比Ubuntu快25%,内存占用降低23%。特别赞赏其完善的容器支持、丰富的语言环境和智能开发

通过这次深入的OpenEuler存储管理实战,我们构建了完整的存储解决方案,从本地磁盘管理到网络存储配置,从基础文件系统到高级存储特性。OpenEuler 25.09在存储管理方面展现出了成熟稳定的技术实力。存储作为数字基础设施的核心组成部分,OpenEuler提供的丰富存储工具和优化特性,为构建可靠、高效、易管理的存储环境提供了坚实基础。无论是用于企业级应用还是开发测试环境,OpenEuler的

摘要:本文详细介绍基于华为昇腾MindSpeedMM套件的多模态大模型微调全流程。首先概述套件架构及性能优化特性,包括视觉生成、理解模块和全模态处理能力。其次说明环境配置要求,涵盖硬件规格、软件安装及数据集准备。重点阐述模型微调实践,包括投影层和语言模型的分阶段微调方法,并提供评估优化与生产部署方案。最后总结MindSpeedMM在昇腾(149字)