




- @WSRY_GJP
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在本节内容中,将详细介绍神经网络模块中包含的几个神经网络类的属性和功能,并详细讲解基于Python和Pytorch 实现的源码。本节内容的神经网络模块包括基本的深度神经网络 DNN、LSTM和卷积神经网络 CNN。
深度学习没有标准定义,但总的来说,深度学习是机器学习(ML)的一种,主要可以看作是人工神经网络(ANNs)的高级模型。这些技术被用作实现人工智能 (AI) 的工具
贝尔曼方程表示上述状态价值函数与状态-行为价值函数之间的关系。贝尔曼方程有贝尔曼期望方程和贝尔曼最佳方程。
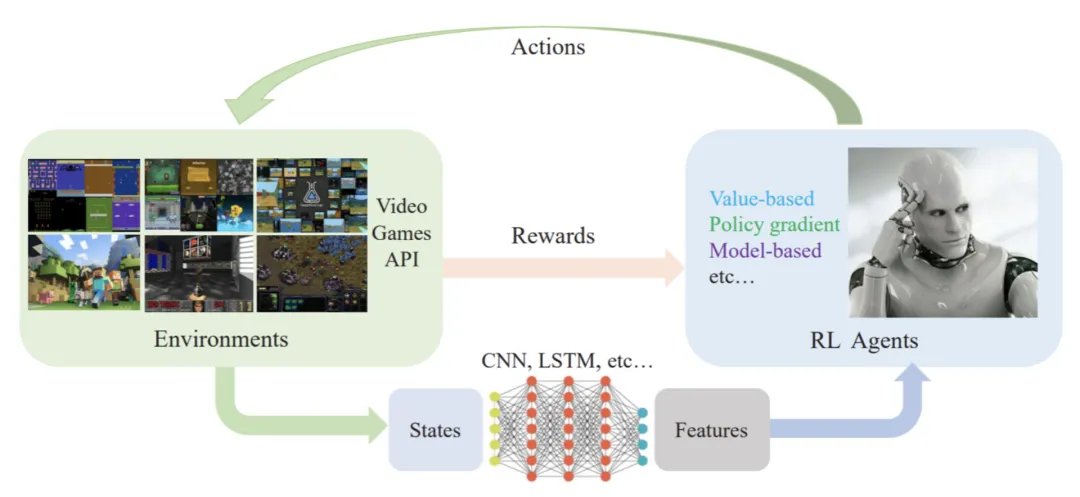
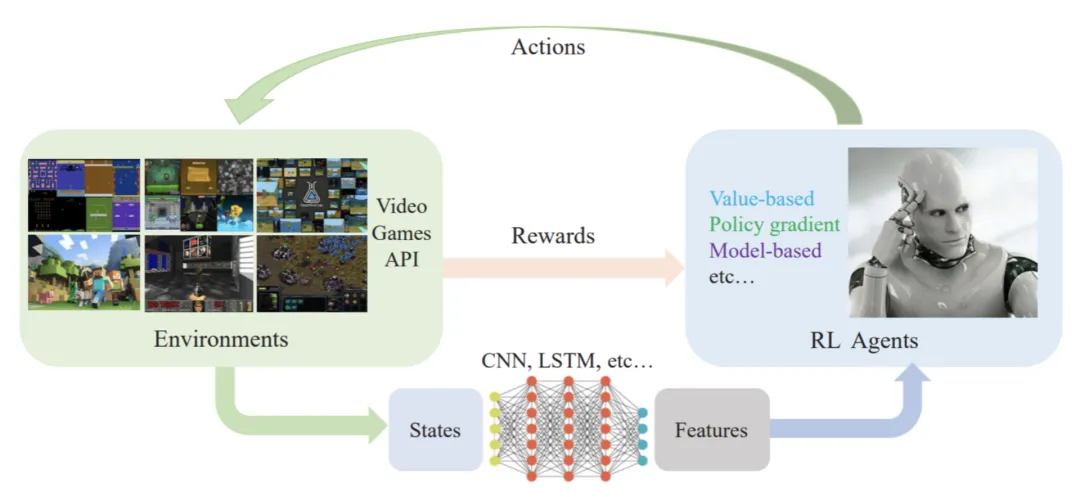
通过分析股票投资强化学习中必要的参与因素和作用,RLTrader 的架构主要有数据管理模块(data_manage,py)、主模块(main.py)、学习模块(learners.py)、可视化模块(visualizer.py)组成,其中主模块又分为环境模块(environment.py)、代理模块(agent.py)、神经网络模块组成(networks.py)

文章目录什么是强化学习(上)1. 强化学习(概述)2. 马尔可夫决策过程2.1 马尔可夫假设2.2 马尔可夫决策过程2.3 状态值函数(state-value function)2.4 状态-行动价值函数(action-valuefunction)什么是强化学习(上)1. 强化学习(概述)强化学习(Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行
matplotlib基础绘图函数功能函数功能figure.add_subplot创建选中资图,指定行数列数和子图编号plt.figure创建空话不,指定大小和像素plt.xlable(ylabel)添加x(y)轴名称,指定位置,颜色,字体的大小plt.xlim(ylim)指定x(y)轴范围,只能确定一个数值区间,而无法使用字符串标识plt.xt...
大话深度学习(五)优化神经网络的方法文章目录大话深度学习(五)优化神经网络的方法前言梯度下降算法随机梯度下降算法自适应学习率算法1.AdaGrad2.RMSProp3.Adam前言一般的神经网络的训练过程大致分为两个阶段:第一阶段:先通过前向传播算法得到预测值,将预测值与真实值做比较,得到二者之间的差别第二阶段:通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习旅使用梯度下...
贝尔曼方程表示上述状态价值函数与状态-行为价值函数之间的关系。贝尔曼方程有贝尔曼期望方程和贝尔曼最佳方程。
大话深度学习与Tensorflow2.0(一):深度前馈神经网络文章目录大话深度学习与Tensorflow2.0(一):深度前馈神经网络初识深度前馈神经网络全连接与稀疏连接初识深度前馈神经网络深度前馈神经网络可简称为前馈神经网络,前馈神经网络最具有代表性的一个样例就是多层感知机(MLP)模型。前馈神经网络的模型是向前的,模型的输入与输出不存在链接,例如一个输入输出满足一个函数y=f(x),...
通过分析股票投资强化学习中必要的参与因素和作用,RLTrader 的架构主要有数据管理模块(data_manage,py)、主模块(main.py)、学习模块(learners.py)、可视化模块(visualizer.py)组成,其中主模块又分为环境模块(environment.py)、代理模块(agent.py)、神经网络模块组成(networks.py)