
写文章




- @Print_lin
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
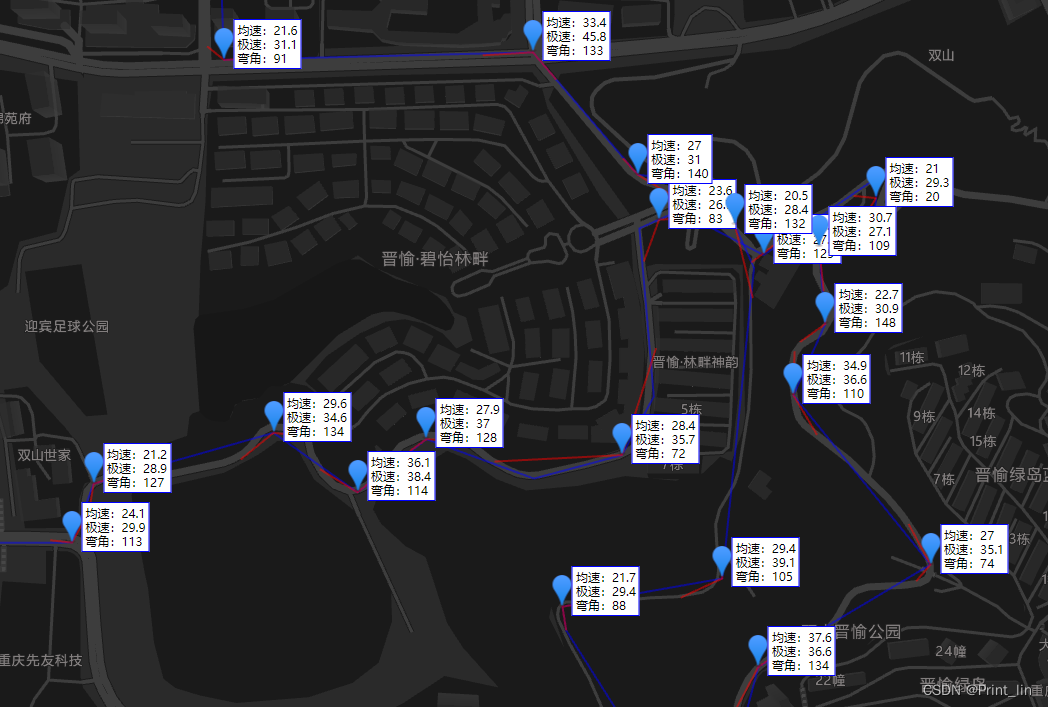
一种经纬度轨迹数据计算物理弯道的方法,轨迹弯道算法
本文使用了纯数学计算的方法计算识别了轨迹中的弯道位置,整体思路较为简单,不过最终效果十分可观,本算法已经在百万级用户的平台稳定运行,在实现过程中对GPS漂移、连续弯道、回旋弯道进行了处理。不过弯道数据仅供页面展示,不能用于准确判断。经过上文的算法,我们可以通过GPS坐标信息计算地理平面上的弯道数据,对于弯道的定义是三点的夹角值满足范围即可。整体思路简单,实现难度低,不依赖其它库,对一些基本的异常进
图片相似度比对算法
Ocr文字识别其中的一大关键就是两张图片相似与否的判断,所以我们希望寻找一种或多种算法来计算图片的相似度。本文将对于项目中使用的比对算法进行介绍,并将其联合运用进行初步文字识别。算法清单 像素点对比重心对比投影对比分块对比前提知识 计算机处理图片并不像人这样可以直观的理解处理,在计算机中的图像可以看成一个矩阵,矩阵中的元素是一个颜色值,这...
Springboot配置Redis多数据源
Springboot默认支持一路redis,项目中有需求用到redis多数据源。本文仅基于Springboot进行多数据源配置,不依赖其它JAR包支持,理论可配置无限多的redis连接。
到底了