




- @MrR1ght
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在远程服务器上做开发时,如本人在远程gpu服务器进行深度学习,如果在本地开发环境下开发可能会存在问题,需要保证本地开发环境与远程服务器一致。本地编辑好的程序也要拷贝到服务器。可以通过以下的几种方式直接在远程服务器环境下做开发。1、pycham远程配置主要需要配置以下两个本地文件与远程文件关联,也就是实现与远程服务器互联,在本地开发完成的文件可以一键传到远程服务器,远程服务器的文件也可一...
CNN的卷积核大小都是奇数而没有偶数主要有以下两点原因:1、奇数卷积核有中心像素点如下图中,奇数大小的卷积核有唯一的中心像素点,而偶数大小的卷积核没有中心像素点为什么需要中心像素点?因为中心像素点有以下两点左右:确定局部卷积后要更新的像素点位置。如下图的卷积操作,中心像素的位置对应着当前卷积操作wx+b的值要赋给那个位置。如果卷积核是偶数,中...
多分类模型和多任务模型(Multi-task Model)的区别在于:多分类模型:样本集包含多个类别,但是一个样本只属于一类。多任务模型:样本集包含多个类别,一个样本可以属于多个类别。一、多分类模型1、多分类模型使用交叉熵损失函数。在计算时其实就是-log(pt),对一个样本来说,pt就是该样本真实的类别,模型预测样本属于该类别的概率。例如某样本的label是[0,1,...
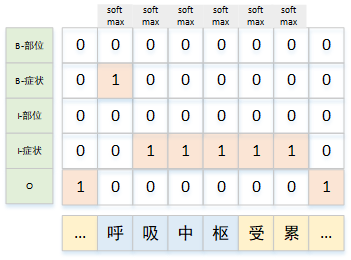
中文NER方法总结中文命名实体识别主要有四大主流算法,序列标注,指针网络,多头标注,片段排列。1. 四大抽取算法1.1 序列标注最简单的softmax+CE的方法,是一种token级别的分类任务。这种方法最简单,但没有考虑到标签之间的关系。仅仅在特征提取时,上后文是有联系的,每个时刻分类时,互不相关,这样就会出现很不合理的预测,如BB等。在每一个位置使用softmax进行2C+12C+12C+
测试了pytorch的三种取样器用法。一:概念Sample:取样器是在某一个数据集合上,按照某种策略进行取样。常见的策略包括顺序取样,随机取样(个样本等概率),随机取样(赋予个样本不同的概率)。以上三个策略都有放回和不放回两种方式。TensorDataset:对多个数据列表进行简单包装。就是用一个更大的list将多个不同类型的list数据进行简单包装。代码如下:class...
一 numpy广播机制Broadcast原理:python在进行numpy算术运算采用的是element-wise方式(逐元素操作的方式),此时要求两个数据的维度必须相同。维度不同时,会触发广播操作使其维度相同。不满足广播操作的情况下会直接报错。broadcase原理数据的维度指两个方面,维度的个数和维度的大小。如:a = np.ones(4,3)维度个数是2,第一维大小是4,...
长尾分布下的分类问题基于深度学习的分类算法应用于长尾分布数据集时,识别效果不好。对尾部类别的学习效果很差。为解决长尾分类下的识别问题,有多种不同思想的优化方法。最简单的方法是重采样(re-sampling)和重加权(re-weighting)。一些最新研究方法包括知识迁移和解耦特征和分类器。重采样(re-sampling)重采样的具体做法包括对头部类别样本的欠采样和对尾部类别样本的过采样。但过
Pytorch没有对全局平均(最大)池化单独封装为一层。需要自己实现。下面有两种简单的实现方式。使用torch.max_pool1d()定义一个网络层。使用nn.AdaptiveMaxPool1d(1)并设置输出维度是1import torchimport torch.nn as nnimport numpy as np#第一种方式class GlobalMaxPool1d...
图像的平移,旋转变换以及仿射与投影都需要先定义转换矩阵,然后使用cv2.warpAffine()根据变换矩阵完成转换imgRotation = cv2.warpAffine(img, mat,(widthNew,heightNew),borderValue=(255,255,255))其中,参数的定义如下表:img需要变换的图像mat转换矩阵(width...
在远程服务器上做开发时,如本人在远程gpu服务器进行深度学习,如果在本地开发环境下开发可能会存在问题,需要保证本地开发环境与远程服务器一致。本地编辑好的程序也要拷贝到服务器。可以通过以下的几种方式直接在远程服务器环境下做开发。1、pycham远程配置主要需要配置以下两个本地文件与远程文件关联,也就是实现与远程服务器互联,在本地开发完成的文件可以一键传到远程服务器,远程服务器的文件也可一...