
写文章




- @Li12139
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Bert自学笔记1
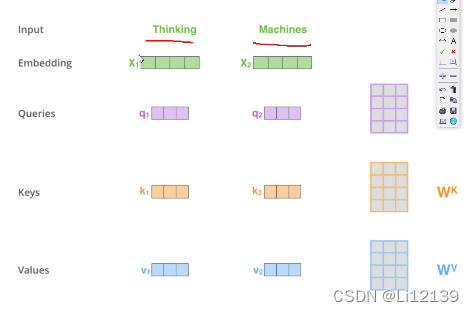
传统Rnn有什么问题:每一个下一步都会用到前面的结果,不独立,不能并行计算,消耗算力大,所以层数较少,不能像卷积那样有很多层。Transformer可以作并行。Rnn中的注意力机制,即给每个词分配重要性权重,让网络知道哪个重要,哪个不重要。此即是ATTention。传统的word2vec用词向量表示文本特征,救活了nlp。当训练传统word2vec时,先训练好一个词向量,再对语料库中的文本转换为词
pytorch神经网络基础
import torchfrom torch import nnfrom torch .nn import functional as F# 定义了一个特殊的module# net = nn.Sequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))x=torch.rand(2,20)# print(net(x))# 感知机class MLP

到底了