- @LFM3320829529
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要介绍大模型训练(优化)的几种高效策略的理论原理与工程实现代码:监督微调(SFT)、近端策略优化(PPO)、直接偏好优化(DPO)以及组相对策略优化(GRPO)。

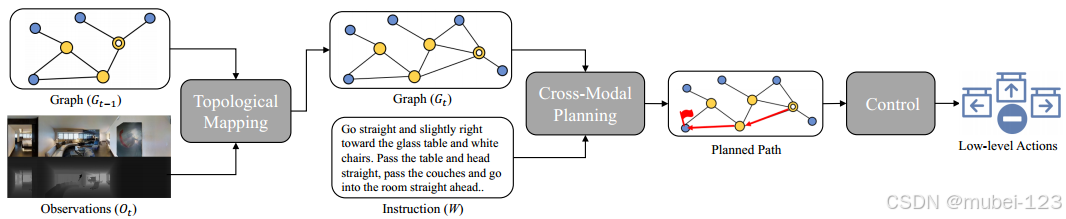
本工作的主要贡献:(1)提出了一种新的基于拓扑图的VLN-CE鲁棒导航规划方法。它可以有效地抽象连续环境,并促进代理的长期目标规划;(2)通过综合实验研究了构建拓扑图的基本设计选择,证明了简洁的深度设计是航路点预测的最佳选择;(3)提出了一种有效的试错控制器来解决避障问题。
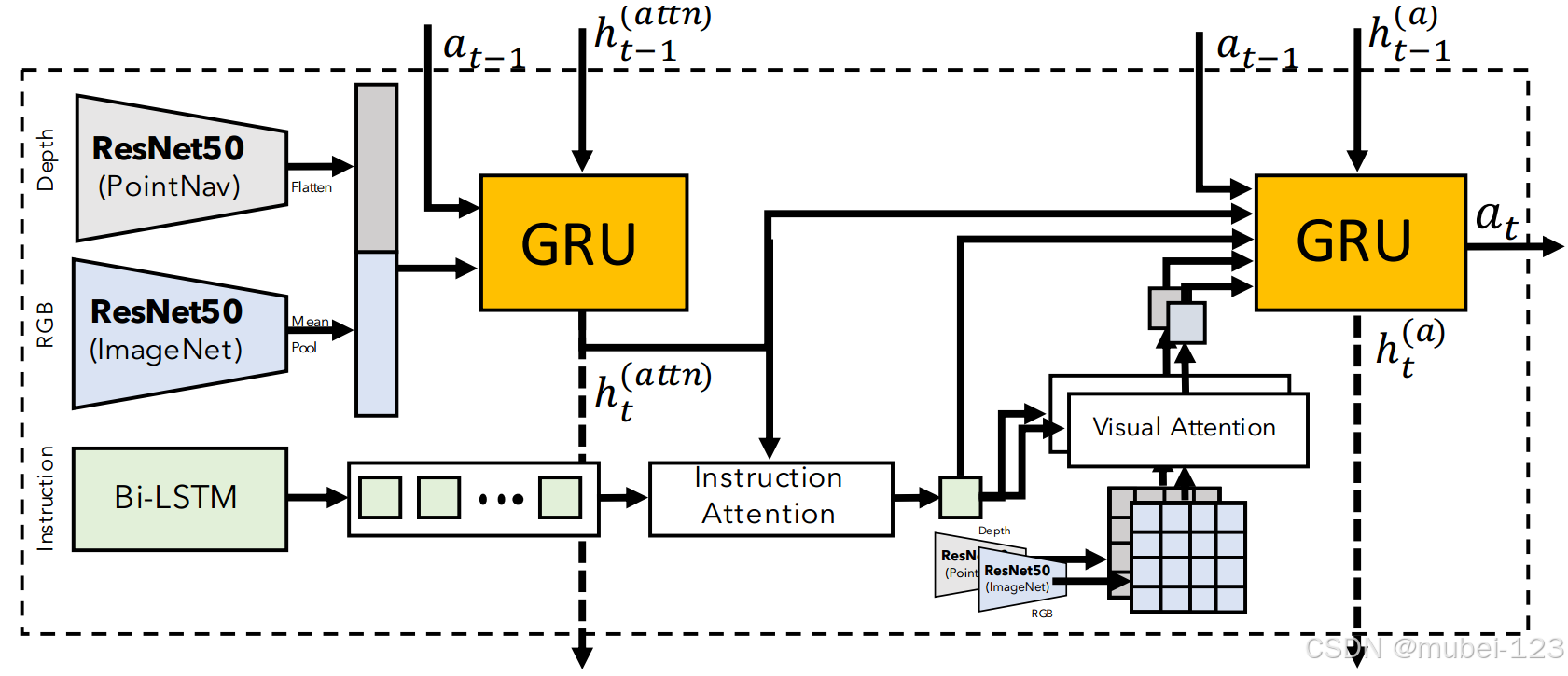
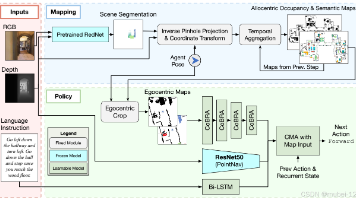
此工作的主要贡献:(1)提出一种无人机视觉语言导航数据集,收集25个不同的城市级环境,涵盖市中心、工厂、公园和村庄等各种场景,包括870多种不同类型的对象,总共8446条飞行路径,每条路径与注释中的3条指令对齐,子路径与子指令对齐,每条指令中最多有83个单词,涉及4470个词汇; (2)提出一种起始基线模型,该模型基于门控循环单元(GRU)和跨模态注意力CMA。
模仿学习。为模型提供高质量的“问题-答案”配对数据,让它学习如何生成正确的回答。强化学习。让模型通过试错,根据一个“奖励模型”的反馈来优化自己的策略(即生成答案的方式)。绕过奖励模型,直接使用偏好数据来优化模型。它是一种更聪明、更简洁的数学转换。用简单规则对模型自己实时生成的结果进行分组比较,从而实现自我迭代优化。其革命性在于,它完全摆脱了对“人类标注的偏好数据”或“奖励模型”的依赖,仅依靠一个可
Transformer是谷歌2017年发表的论文《Attention Is All You Need》中提出的,用于NLP的各项任务,其引入了自注意力机制(self-attention mechanism),具有长距离依赖关系建模、并行计算能力和通用性能优点,已广泛应用于系列数据的处理。在本文中,我们将从Transformer的整体框架、Encoder结构和输入输出、Decoder的结构和输入输出

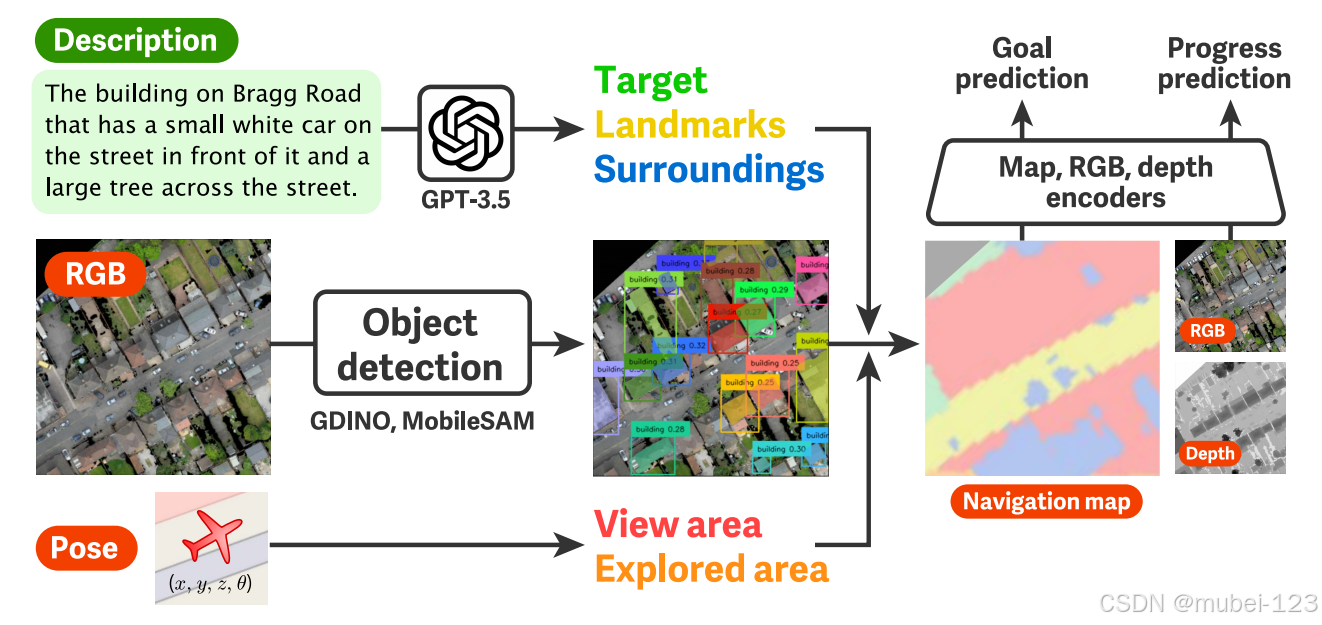
此工作的主要贡献:(1)开发了一种新型的基于网络的3D飞行模拟器,该模拟器在浏览器中运行,并与MTurk集成,以收集城市规模的大规模人类辅助生成的飞行轨迹;(2)收集了一个新颖的无人机视觉语言导航数据集CityNav,包含32637种语言目标描述和人类演示,利用真实城市及其地理信息的3D扫描;(3)提供了一个基线模型,其中包括一个表示地理信息的内部二维空间地图。
本工作的主要贡献如下:扩展高性能Transfrmer VLN代理的隐式记忆对于IVLN来说是不够的,但构建映射的代理可以从环境持久性中受益。具体来说:(1)对于离散模型,代理在图边上移动,观察清晰、框架良好的图像,提出一种最先进的Transformer代理,在解释指令时基于路径历史学习隐式记忆;(2)对于连续模型,代理在观察从离散全景图像重建的3D环境的噪声图像的同时,预测动作,提出了一种构建和解
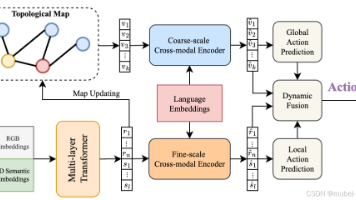
本工作的主要贡献:(1)提出了一种新的学习和融合框架,为VLN任务引入了三维语义表示;(2)设计了一个区域查询前置学习任务,以自监督学习的方式帮助从未标记的三维语义重建中学习三维语义表示。
注意力机制是一种在神经网络的设计中被广泛使用的技术。在认知科学中,当信息输入规模超过大脑的处理能力时,人类倾向于有选择地将注意力集中于感兴趣的信息,并忽略其他信息。本文将详细介绍并梳理目前存在的各类注意力机制的原理,方便按需使用。
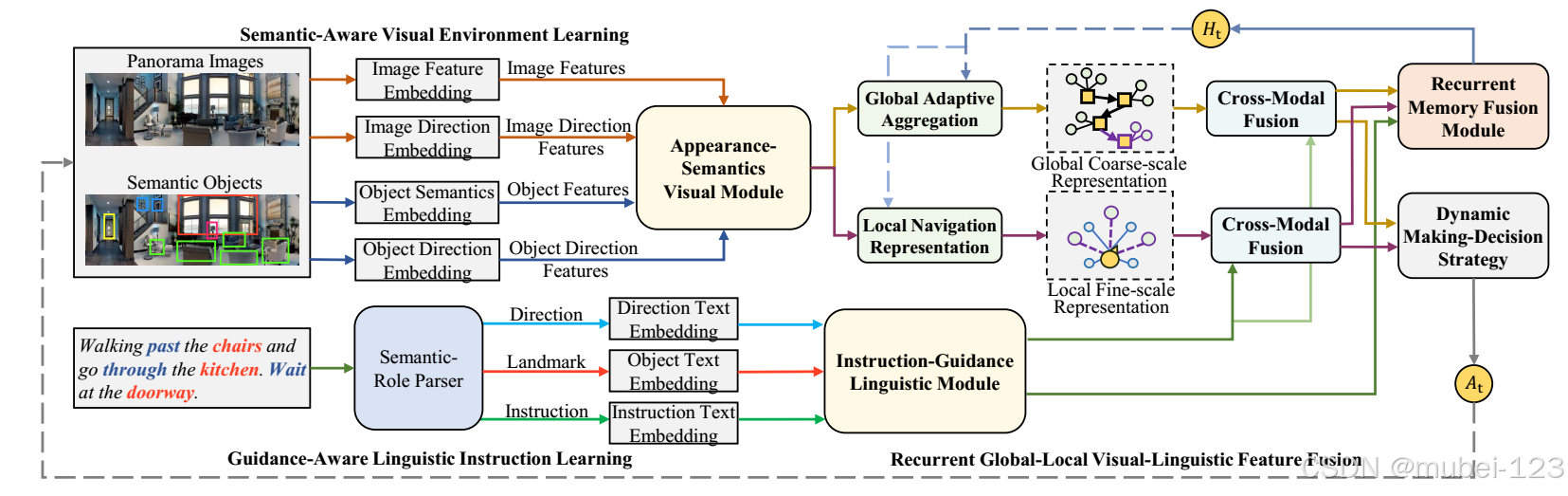
本工作的主要贡献:(1)提出了一种双重语义增强结构,分别增强视觉和语言语义表征;(2)使用显式和隐式记忆传输通道来增强模型自适应记忆和推断导航状态的能力。