




- @Franklin7B
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
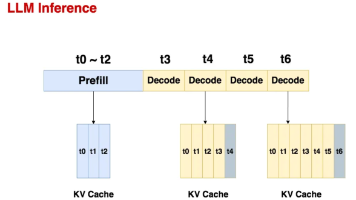
本文以输入"hi, who are you"为例,详细拆解了vLLM推理的Prefill和Decode过程。Prefill阶段对6个输入token进行嵌入、位置编码和32层Transformer计算,其中KV Cache采用分块存储(块大小16),仅需1个物理块。Decode阶段则自回归生成新token,每次仅处理单个token并复用预填充的KV Cache。整个过程严格遵循因
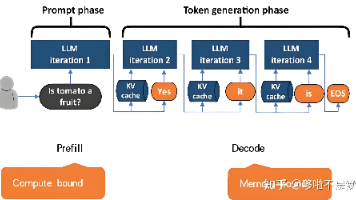
本文系统讲解了vLLM框架下prefill和decode的完整流程。在prefill阶段:1) 对输入token序列计算隐藏状态并应用RoPE位置编码;2) 并行生成Q/K/V矩阵;3) 计算注意力分数并softmax归一化;4) 加权求和得到输出向量;5) 缓存全部KV对。decode阶段则:1) 仅处理当前token;2) 计算最新Q/K/V;3) 结合历史KV缓存;4) 更新缓存并生成下一t
修改meta_main_app.toml中的node_id = 100。首先我们在火山云上申请一个ecs.hpcpni3ln.45xlarge实例作为编译环境使用. 注意在创建实例的时候,选择unbuntu 22.04。每个存储节点修改/opt/3fs/etc/storage_main_app.toml中的node_id,五台机器分别为10001~10005。另外由于3FS使用了mellanox网
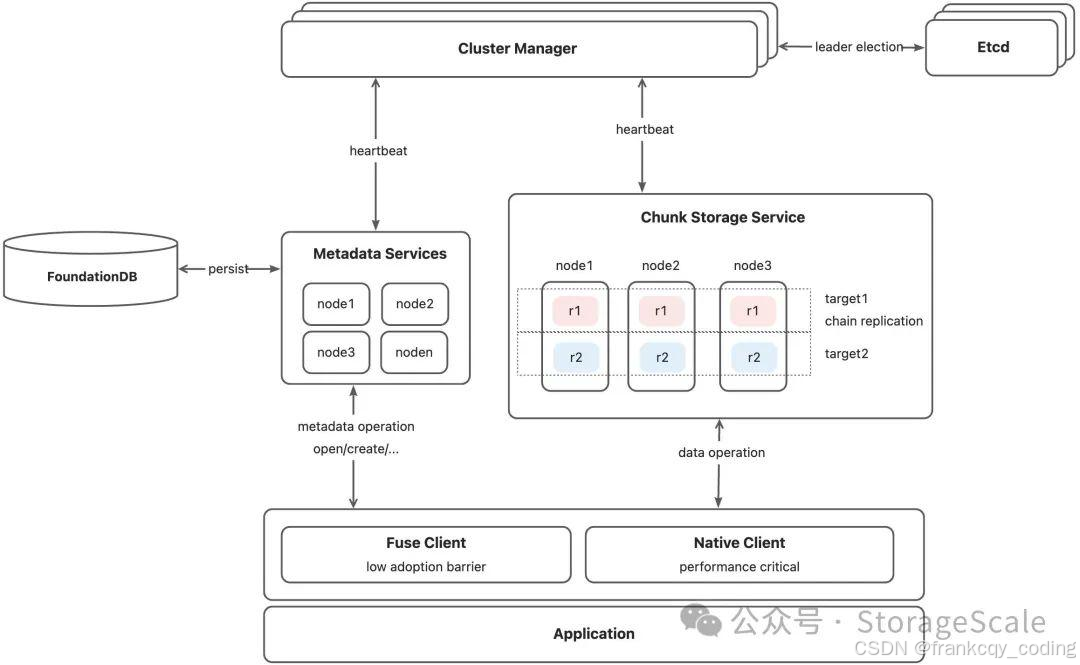
修改meta_main_app.toml中的node_id = 100。首先我们在火山云上申请一个ecs.hpcpni3ln.45xlarge实例作为编译环境使用. 注意在创建实例的时候,选择unbuntu 22.04。每个存储节点修改/opt/3fs/etc/storage_main_app.toml中的node_id,五台机器分别为10001~10005。另外由于3FS使用了mellanox网
1999 年,英伟达发明了 GPU(graphics processing unit),本节将介绍英伟达 GPU 从 Fermi 到 Blackwell 共 9 代架构,时间跨度从 2010 年至 2024 年,具体包括费米(Feimi)、开普勒(Kepler)、麦克斯韦(Maxwell)、帕斯卡(Pashcal)、伏特(Volt)、图灵(Turing)、安培(Ampere)和赫柏(Hopper)
上段时间遇到了 docker 容器内部 dns 解析失败的问题,发现在 docker run启动容器之后,容器内部访问外部的接口总是提示无法解析 dns,然而容器外部是可以解析的,dns的配置也没有任何问题。用docker exec -it contaner_name bash进去,ping 任何域名都是不通。最终的解决办法在在于,停止 docker daemon,删掉 ifconf...
修改meta_main_app.toml中的node_id = 100。首先我们在火山云上申请一个ecs.hpcpni3ln.45xlarge实例作为编译环境使用. 注意在创建实例的时候,选择unbuntu 22.04。每个存储节点修改/opt/3fs/etc/storage_main_app.toml中的node_id,五台机器分别为10001~10005。另外由于3FS使用了mellanox网
一、虚拟机迁移概述1、vMotion基础知识简介您可使用热迁移或冷迁移将虚拟机从一个主机或存储位置移至另一位置。例如,您可使用 vSphere vMotion 将已打开电源的虚拟机从主机上移开,以便执行维护、平衡负载、并置相互通信的虚拟机、将多个虚拟机分离以最大限度地减少故障域、迁移到新服务器硬件等等。您可使用冷迁移或热迁移将虚拟机移至其他主机或数据存储。冷迁移:...