- @DengCaixiang2021
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
RNN(循环神经网络)是一种专门处理序列数据的神经网络,通过隐藏状态传递历史信息,实现对序列数据的记忆功能。其核心特点是每个时间步都会结合当前输入和前一步的隐藏状态生成输出,适用于连续剧理解、语言模型等时序任务。示例代码展示了PyTorch实现的简单RNN模型,包含输入层、RNN层和全连接层,演示了如何处理二维序列数据(batch_size=2, seq_len=5)并输出分类结果。该模型通过维护
机器学习、深度学习、神经网络之间的关系

一、在 AudioPolicyService 中,选择音频路由时会从当前音频流的类型获取音频的路由策略:/frameworks/av/services/audiopolicy/managerdefault/AudioPolicyManager.cpp/frameworks/av/services/audiopolicy/enginedefault/src/Engine.cpp音频策略枚举:二、获取
RNN(循环神经网络)是一种专门处理序列数据的神经网络,通过隐藏状态传递历史信息,实现对序列数据的记忆功能。其核心特点是每个时间步都会结合当前输入和前一步的隐藏状态生成输出,适用于连续剧理解、语言模型等时序任务。示例代码展示了PyTorch实现的简单RNN模型,包含输入层、RNN层和全连接层,演示了如何处理二维序列数据(batch_size=2, seq_len=5)并输出分类结果。该模型通过维护
卷积神经网络(Convolutional Neural Network,CNN)是一类专门用于处理具有类似网格结构的数据的深度学习模型。它在计算机视觉领域取得了巨大成功,广泛应用于图像识别、物体检测、语义分割等任务。
自动语音识别技术经过多年的发展,已经从早期简陋的模板匹配系统演进为今天复杂而精巧的深度学习模型。在原理层面,ASR将声音信号转为文本所涉及的每一步都凝聚了大量研究者的智慧;在应用层面,ASR正悄然改变着人机交互的方式,让语音成为与计算机交流的自然手段。展望未来,ASR研究仍在继续:如何让机器听懂更多语言、在嘈杂人群中分辨每个声音、用更少的数据学会新语种,以及更贴近地模仿人类听觉的鲁棒性。这些挑战伴

自动语音识别技术经过多年的发展,已经从早期简陋的模板匹配系统演进为今天复杂而精巧的深度学习模型。在原理层面,ASR将声音信号转为文本所涉及的每一步都凝聚了大量研究者的智慧;在应用层面,ASR正悄然改变着人机交互的方式,让语音成为与计算机交流的自然手段。展望未来,ASR研究仍在继续:如何让机器听懂更多语言、在嘈杂人群中分辨每个声音、用更少的数据学会新语种,以及更贴近地模仿人类听觉的鲁棒性。这些挑战伴
机器学习、深度学习、神经网络之间的关系
自动语音识别技术经过多年的发展,已经从早期简陋的模板匹配系统演进为今天复杂而精巧的深度学习模型。在原理层面,ASR将声音信号转为文本所涉及的每一步都凝聚了大量研究者的智慧;在应用层面,ASR正悄然改变着人机交互的方式,让语音成为与计算机交流的自然手段。展望未来,ASR研究仍在继续:如何让机器听懂更多语言、在嘈杂人群中分辨每个声音、用更少的数据学会新语种,以及更贴近地模仿人类听觉的鲁棒性。这些挑战伴
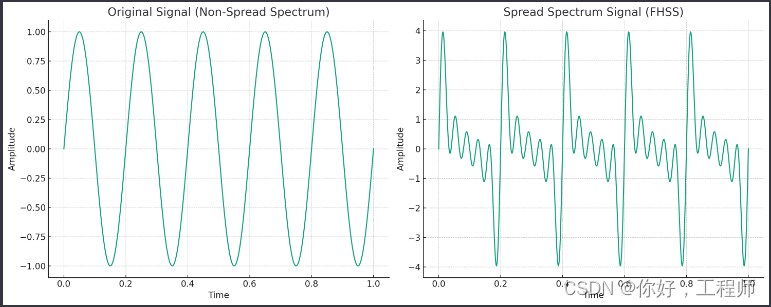
"展频" (Spread Spectrum) 是一种通信技术,它通过扩展信号在频谱上的占用宽度来增强信号的抗干扰能力和安全性。这种技术主要用于无线通信,例如在蜂窝网络、Wi-Fi和卫星通信中。展频技术的关键优势包括抵抗窄带干扰、减少被检测和拦截的风险以及提高信号质量。