




- @Android_xue
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
虽然安装完Anaconda后,就可以直接使用数据分析库进行代码编写以及数据分析,但是有时候我还是习惯用PyCharm开发(毕竟有很多年的Android Studio 和IDEA的使用经验),如何在PyCharm中导入常用的数据分析库呢?(1)打开PyCharm,选择左下角的Terminal,更新pippython -m pip install -U pip(2)安装各种库命令python...
报错在启动mysql服务时出现该错误:本地计算机上的mysql服务启动停止后,某些服务在未由其他服务或程序使用时将自动停止。解决前提以管理员身份运行cmd,然后切换到mysql安装盘,找到mysql的bin目录解决步骤1.删除原来的服务mysqld --remove mysql2.清空mysql根目录下的data目录3.在bin目录下执行命令m...
其实不管是哪家公司面试,都是根据你的简历来对你进行提问,所以自己简历上面写的知识点都要全部对答如流。还有慎用精通这样的字眼,工作五年以上的人,也不敢说自己对哪一方面能够达到精通的地步。下面是网上找的一些面试经历,可以看得出来问的都是大数据的基本知识点(可查阅这个大纲),而且现在大数据的面试官也不见得都是大牛,保持好心态,把自己真正懂的知识很流畅的表达出来即可。公司A:1.讲讲你做的过的项目。 项目
提取数据在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式!正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样...
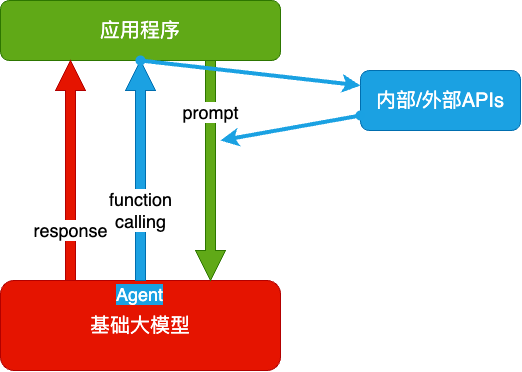
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。AI 全栈课程主要以 OpenAI 为例,少量介绍国产大模型,微调会用开源大模型。OpenAI 的接口名就叫「completion」,也证明了其只会「生成」的本质。然后用测试数据,在可以选择的模型里,做测试,找出最合适的。用人类比,训练就是学,推理就是用。很多企业将大模型和业务相结合,取得了或大或小的效果
前言我个人对Maven没有多少研究,仅仅是使用层面,但是有时候在IDEA中配置好Maven,写好pom.xml文件后,经常下载一会就停止了,也就是有些jar包并没有下载成功。我从网上搜了一下,发现大部分都在转载下面这些方法,在这里进行汇总。方法汇总删除本地的\repository库中所有.lastupdate后缀文件,重新下载这种方法操作简单,但是我不知道是否每次都能成功拷贝相应jar,手动导入本
Kafka从 0.11.0.0 版本开始提供了一种在生产者和消费者之间传递元数据的机制,叫做 Kafka header。使用这个机制,你可以在消息中添加一些与数据内容无关的附加信息,如消息的来源、类型、版本、生产时间、过期时间、分区数、用户 ID 等等。Kafka header 是由一个或多个键值对组成的列表,每个键值对都称为 header。消息可以包含零个或多个 header。Kafka hea
MapReduce是一种云计算的核心计算模式,是一种分布式运算技术,也是简化的分布式并行编程模式,主要用于大规模并行程序并行问题。MapReduce的主要思想:自动将一个大的计算(程序)拆分成Map(映射)和Reduce(化简)的方式。流程图如下:数据被分割后通过Map函数将数据映射成不同的区块,分配给计算集群进行处理,以达到分布运算的效果,再通过Reduce函数将结果进行汇...
Java对象的销毁每个对象都有生命周期,当对象的生命周期结束时,分配给对象的内存地址将会被回收。何种对象会被java虚拟机视为垃圾:(1)对象引用超过其作用范围,这个对象被视为垃圾{Example e = new Example();}在大括号之外的范围,就被视为超过e的作用范围。(2)将对象赋值为null{Example e = new Example()
下载Maven官网配置环境变量我的下载目录是在D:\develop\maven\apache-maven-3.6.1,所以右键点击计算机->属性->高级系统设置->环境变量->新建,然后添加系统变量点击path,配置:然后打开命令提示符:输入mvn -v配置settings文件和respository打开settings文件配置本地respositor...