




- @AIMoster
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
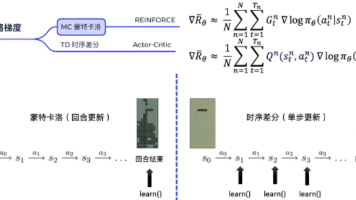
本文通过走迷宫游戏生动形象地介绍了强化学习四大算法:REINFORCE通过完整轨迹调整策略;Actor-Critic引入实时反馈机制;A2C采用优势函数优化;A3C实现异步并行加速。文章详细解析了各算法的数学原理和实现代码,并通过CartPole游戏对比测试。结果表明,REINFORCE在该任务中表现最优,A3C次之,而Actor-Critic和A2C相对较弱。最后给出了学习建议:从简单算法入手,
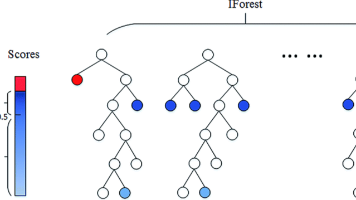
摘要:本文系统介绍了6种异常检测算法及其应用场景。通过电商欺诈检测等案例,说明了异常检测的核心逻辑:识别少数异常样本与正常样本的特征差异。详细讲解了孤立森林、One-Class SVM、LOF、ABOD、椭圆模型和VAE的数学原理与特点,并以鸢尾花数据集为例提供完整的Python实战代码。最后对比了各算法优缺点,帮助读者根据数据集特点选择合适的检测方法,包括训练速度、高维适应性和适用场景等关键指标
本文系统梳理2025年机器学习领域期刊投稿策略,将IF≥2的优质期刊分为三大阵营:顶刊阵营(IF≥4.0)适合突破性成果,如Nature Machine Intelligence(IF23.9);中高性价比阵营(IF3.0-6.5)平衡影响力与命中率,如Neurocomputing(IF6.5);易投实用阵营(IF2.0-3.0)适合刚需投稿,如Neural Processing Letters(

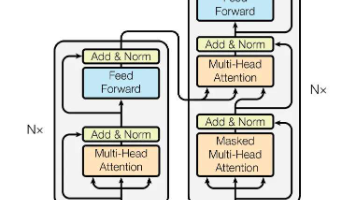
摘要: 本文系统介绍了生成式对抗网络(GAN)的发展历程与核心原理,从基础GAN到DCGAN、CycleGAN、Pix2Pix和StyleGAN的五代演进。通过“造假者VS侦探”的比喻解析GAN的对抗训练机制,结合数学公式和网络结构详细说明各代模型的创新点:DCGAN引入卷积提升图像质量,CycleGAN实现无监督风格迁移,Pix2Pix完成有监督图像转换,StyleGAN实现精细化生成控制。文章
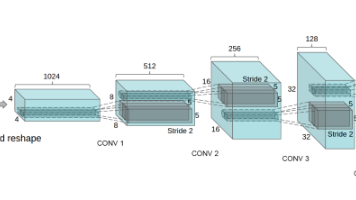
本文介绍了将Transformer与强化学习相结合的创新方法。Transformer作为特征提取器,能够理解复杂环境状态;强化学习则负责优化决策策略。文章详细阐述了融合思路,包括使用Transformer作为策略网络,通过注意力机制捕捉状态特征,结合强化学习的延迟奖励处理能力。以CartPole控制问题为例,展示了该方法的PyTorch实现,并提出了算法升级和网络加深等改进方向。这种结合充分发挥了
本文系统梳理2025年机器学习领域期刊投稿策略,将IF≥2的优质期刊分为三大阵营:顶刊阵营(IF≥4.0)适合突破性成果,如Nature Machine Intelligence(IF23.9);中高性价比阵营(IF3.0-6.5)平衡影响力与命中率,如Neurocomputing(IF6.5);易投实用阵营(IF2.0-3.0)适合刚需投稿,如Neural Processing Letters(
本文通过走迷宫游戏生动形象地介绍了强化学习四大算法:REINFORCE通过完整轨迹调整策略;Actor-Critic引入实时反馈机制;A2C采用优势函数优化;A3C实现异步并行加速。文章详细解析了各算法的数学原理和实现代码,并通过CartPole游戏对比测试。结果表明,REINFORCE在该任务中表现最优,A3C次之,而Actor-Critic和A2C相对较弱。最后给出了学习建议:从简单算法入手,
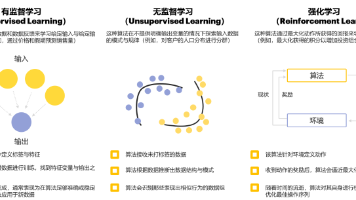
本文是一篇强化学习入门指南,用通俗语言讲解核心概念和算法,并附完整代码实现。文章首先通过对比监督学习和无监督学习,说明强化学习是通过"试错"最大化长期奖励的机器学习方法。然后详细解析了强化学习的5个组成部分(环境、智能体、状态、动作、奖励)和4个关键概念(策略、价值函数、Q值、贝尔曼方程)。接着介绍了三大算法分类(基于值、基于策略、基于模型),并通过一个Q-learning迷宫
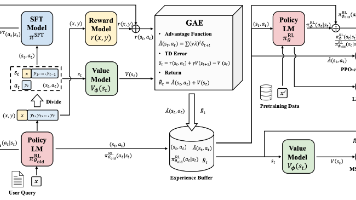
本文系统介绍了六种主流深度强化学习算法的原理与应用。DDPG适用于连续动作空间控制,PPO实现简单且性能稳定,TRPO理论严谨但实现复杂,SAC具有良好探索能力,TD3是DDPG的改进版本,MADDPG则专为多智能体系统设计。文章通过Pendulum-v1环境对比了这些算法的性能,提供了完整的代码实现和训练流程。结果表明,PPO和SAC通常表现最优,而TD3比DDPG更稳定。文章建议初学者从PPO
【摘要】朴素贝叶斯是机器学习入门的经典算法,特别适合新手学习。其核心基于贝叶斯定理和条件独立性假设,通过概率计算实现分类,具有简单易懂、计算高效的特点,广泛应用于垃圾邮件识别、情感分析等场景。文章详细解析了算法原理,包括贝叶斯定理公式、条件独立性假设和分类规则,并介绍三种常见模型变种(高斯/多项式/伯努利)及其适用场景。最后提供完整的Python代码示例(使用sklearn实现鸢尾花分类),帮助读
