
看不懂强化学习?带你用“玩迷宫”的方式彻底入门!(保姆级教程+代码)
本文是一篇强化学习入门指南,用通俗语言讲解核心概念和算法,并附完整代码实现。文章首先通过对比监督学习和无监督学习,说明强化学习是通过"试错"最大化长期奖励的机器学习方法。然后详细解析了强化学习的5个组成部分(环境、智能体、状态、动作、奖励)和4个关键概念(策略、价值函数、Q值、贝尔曼方程)。接着介绍了三大算法分类(基于值、基于策略、基于模型),并通过一个Q-learning迷宫
想入门强化学习(RL)却被“智能体”“Q值”“贝尔曼方程”劝退?别慌!这篇推文用最通俗的语言+完整代码,带你从0到1理解强化学习的核心逻辑,看完就能动手实践~
另外,我整理了强化学习经典论文+代码合集,需要的的话自取~
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/LFzZtI4L4ig4ny4NQ1WweQ
https://mp.weixin.qq.com/s/LFzZtI4L4ig4ny4NQ1WweQ
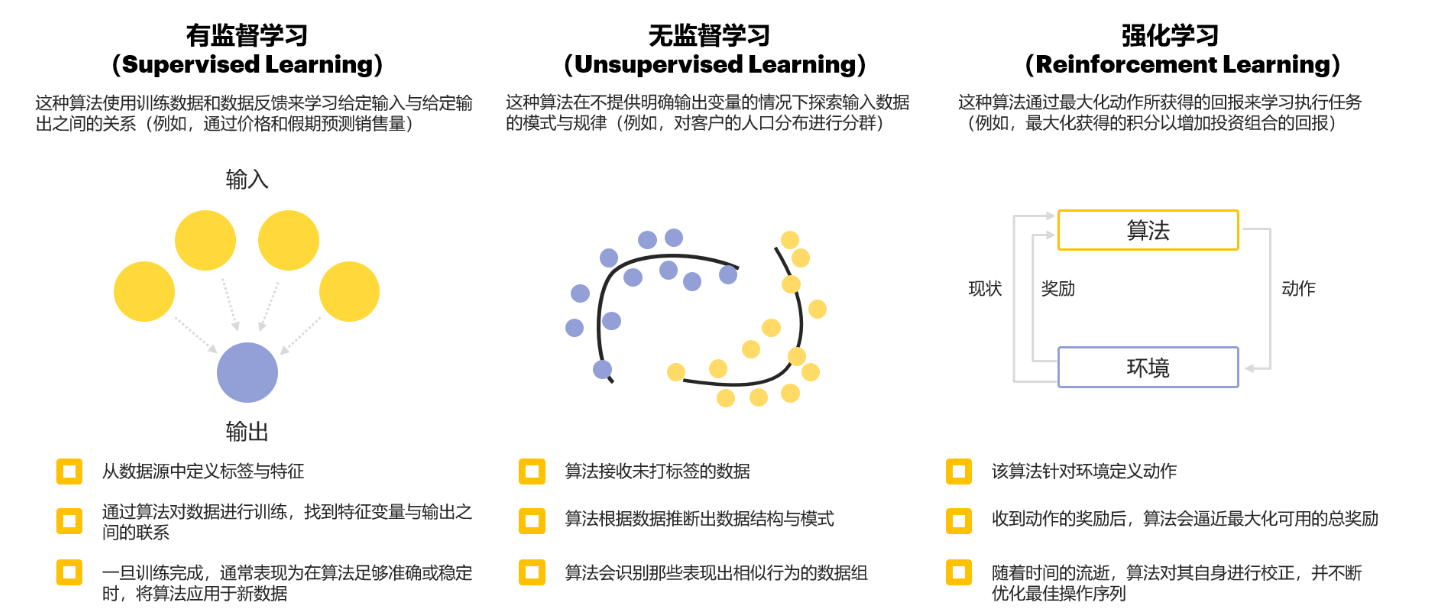
三大分类
一、先搞懂:什么是强化学习?
强化学习(Reinforcement Learning, RL)是让智能体(Agent) 在与环境(Environment) 的交互中,通过“试错”学习最优策略的机器学习方法。核心目标只有一个:最大化长期累积奖励。
和其他机器学习的区别
| 学习类型 | 核心特点 | 数据需求 | 目标 |
|---|---|---|---|
| 监督学习 | 有标注数据(输入→正确输出) | 大量标注样本 | 最小化预测误差 |
| 无监督学习 | 无标注数据 | 无标注样本 | 发现数据内在结构 |
| 强化学习 | 智能体与环境交互试错 | 无预设数据,靠交互生成 | 最大化长期累积奖励 |
适用场景
机器人控制、自动驾驶、游戏AI(如AlphaGo)、金融交易、资源调度等需要“动态决策”的任务。
二、强化学习的5个核心组成部分
强化学习系统就像“智能体在环境中闯关”,这5个部分缺一不可:
-
环境(Environment)
智能体活动的“世界”,比如迷宫、游戏地图、机器人的物理空间。它定义了3个关键规则:-
状态空间:环境可能处于的所有状态(如迷宫中的位置)
-
动作空间:智能体能执行的所有操作(如上下左右移动)
-
奖励规则:智能体做动作后,环境给出的反馈(如找到出口得+10分,撞墙得-5分)
-
-
智能体(Agent)
执行动作的“主角”(如机器人、游戏角色),核心任务是通过学习找到“最优策略”。 -
状态(State, s)
环境在某一时刻的“快照”,比如“智能体在迷宫(2,3)位置”“机器人关节角度30°”。 -
动作(Action, a)
智能体对环境的“操作”,比如“向左走”“抬高机械臂”。 -
奖励(Reward, r)
环境给智能体的“反馈信号”,是学习的“指挥棒”:-
正奖励(+):鼓励正确动作(如通关、得分)
-
负奖励(-):惩罚错误动作(如失败、碰撞)
-
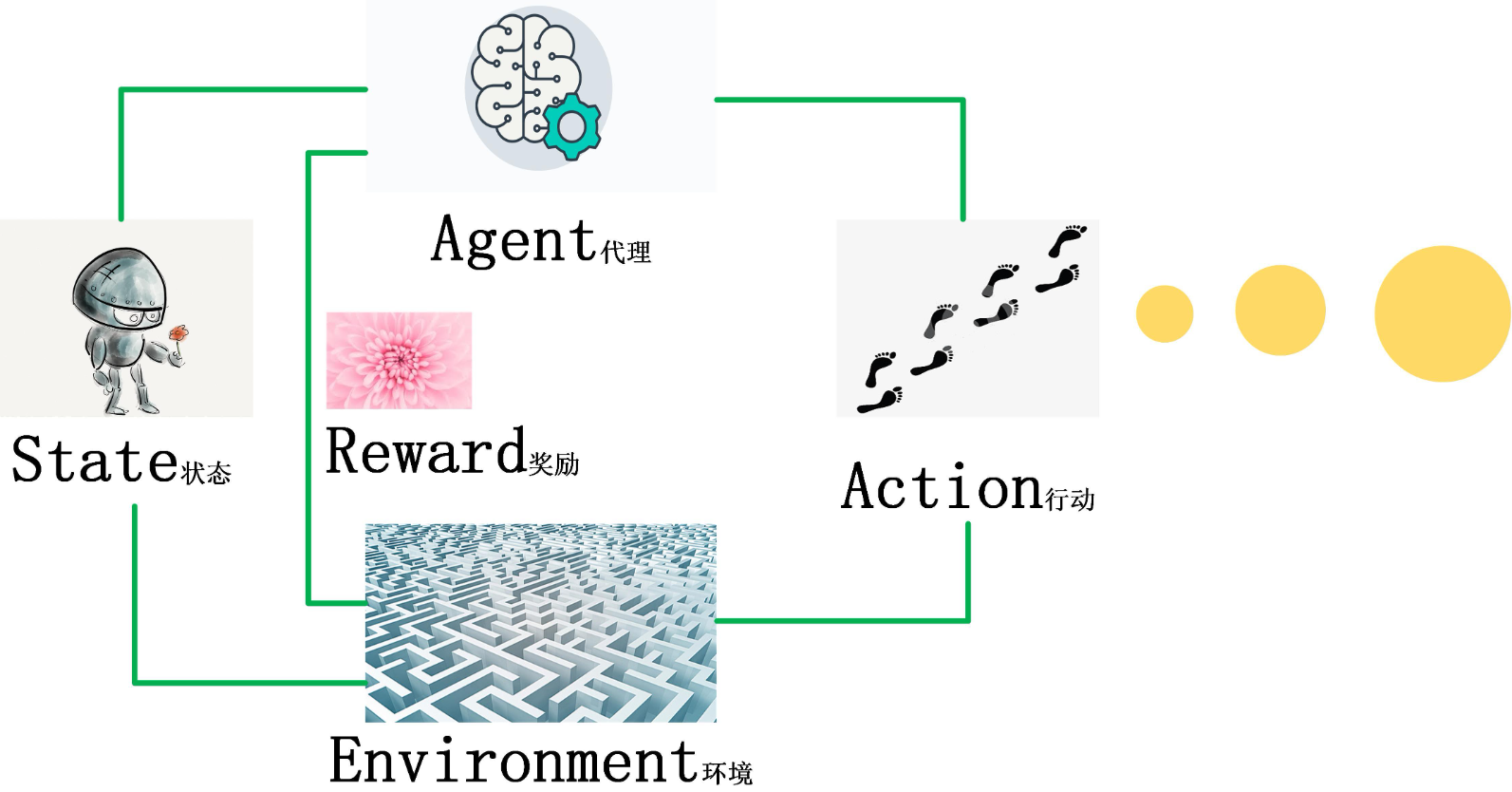
强化学习简单示意图
三、必须掌握的4个关键概念
1. 策略(Policy, π)
策略是智能体的“决策规则”,定义了“在什么状态下做什么动作”,记作 a = π(s)。
-
确定性策略:同一状态下必选同一动作(如s1状态必选a2)
-
随机策略:同一状态下按概率选动作(如s1状态70%选a1,30%选a2)
2. 状态-价值函数(V(s))
衡量“从状态s出发,按策略π行动能获得的长期期望奖励”,公式如下:
-
:折扣因子(0≤γ≤1),控制“未来奖励的重要性”(γ=0只看即时奖励,γ=1重视长期奖励)
-
:按策略π行动的期望
3. 状态-动作值函数(Q-Value, Q(s,a))
比V(s)更具体:衡量“在状态s执行动作a后,按策略π继续行动的长期期望奖励”,公式:
Q值是强化学习的核心——智能体只要学会Q(s,a),就能通过“选Q值最大的动作”找到最优策略。
4. 贝尔曼方程(强化学习的“灵魂”)
描述了“当前价值”与“未来价值”的递归关系,是所有RL算法的数学基础。
-
Q值的贝尔曼方程: 含义:“当前状态s做动作a的Q值” = “即时奖励r” + “未来状态s'的最大Q值(乘以折扣因子)”
四、强化学习的3大算法分类
| 分类 | 核心思路 | 代表算法 | 适用场景 |
|---|---|---|---|
| 基于值迭代(Value-based) | 学习Q值/状态值,再推导策略 | Q-learning、SARSA、DQN | 离散动作空间(如迷宫、小游戏) |
| 基于策略(Policy-based) | 直接学习策略,不显式求Q值 | 策略梯度(PG)、PPO、A2C | 连续动作空间(如机器人控制) |
| 基于模型(Model-based) | 先学环境模型,再规划动作 | Dyna-Q | 环境变化慢、需减少试错的场景 |
五、实战!用Q-learning玩迷宫(完整可运行代码)
我们用经典的“网格迷宫”案例,实现Q-learning算法——让智能体学会从起点(S)走到终点(G),避开障碍(O)。
代码功能说明
-
迷宫地图:5×5网格,S(0,0)为起点,G(4,4)为终点,O(1,1)、O(2,3)为障碍
-
奖励规则:到达G得+100,撞墙/碰障碍得-10,其他动作得-1(鼓励快速通关)
-
最终效果:智能体通过学习,能找到从S到G的最短路径
import numpy as np
import matplotlib.pyplot as plt
# --------------------------
# 1. 定义迷宫环境(Environment)
# --------------------------
class MazeEnv:
def __init__(self):
# 5x5迷宫:0=可走,1=障碍,2=起点,3=终点
self.maze = np.array([
[2, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 3]
])
self.start_pos = (0, 0) # 起点
self.goal_pos = (4, 4) # 终点
self.obstacle_pos = [(1,1), (2,3)] # 障碍
self.action_space = [(-1,0), (1,0), (0,-1), (0,1)] # 上、下、左、右
self.state_space = (5, 5) # 状态空间:(行, 列)
# 获取当前状态(位置)
def get_state(self, pos):
return pos
# 执行动作,返回新状态、奖励、是否结束
def step(self, pos, action):
# 计算新位置
new_pos = (pos[0] + action[0], pos[1] + action[1])
# 1. 边界检测(撞墙)
if new_pos[0] < 0 or new_pos[0] >= 5 or new_pos[1] < 0 or new_pos[1] >= 5:
return pos, -10, False # 位置不变,负奖励,未结束
# 2. 障碍检测
if new_pos in self.obstacle_pos:
return pos, -10, False # 位置不变,负奖励,未结束
# 3. 终点检测
if new_pos == self.goal_pos:
return new_pos, 100, True # 新位置,正奖励,结束
# 4. 正常移动
return new_pos, -1, False # 新位置,小负奖励(鼓励快速通关)
# 重置环境到起点
def reset(self):
return self.start_pos
# --------------------------
# 2. 实现Q-learning算法(Agent)
# --------------------------
class QLearningAgent:
def __init__(self, state_space, action_space, lr=0.1, gamma=0.9, epsilon=0.1):
self.state_space = state_space # (5,5)
self.action_space = action_space # 4个动作
self.lr = lr # 学习率:控制Q值更新幅度
self.gamma = gamma # 折扣因子:控制未来奖励权重
self.epsilon = epsilon # 探索率:控制“探索”与“利用”的平衡
# 初始化Q表:state_space × action_space,初始值为0
self.Q_table = np.zeros((state_space[0], state_space[1], len(action_space)))
# 选择动作:ε-贪心策略(兼顾探索和利用)
def choose_action(self, state):
# 探索:以ε概率随机选动作(尝试新路径)
if np.random.uniform(0, 1) < self.epsilon:
return np.random.choice(len(self.action_space))
# 利用:以1-ε概率选Q值最大的动作(走已知最优路径)
else:
return np.argmax(self.Q_table[state[0], state[1], :])
# 更新Q表:根据贝尔曼方程
def update_Q_table(self, state, action, reward, next_state):
# 当前Q值
current_Q = self.Q_table[state[0], state[1], action]
# 下一个状态的最大Q值
max_next_Q = np.max(self.Q_table[next_state[0], next_state[1], :])
# 贝尔曼方程更新Q值
new_Q = current_Q + self.lr * (reward + self.gamma * max_next_Q - current_Q)
self.Q_table[state[0], state[1], action] = new_Q
# --------------------------
# 3. 训练与可视化
# --------------------------
def train_maze_qlearning(episodes=1000):
# 初始化环境和智能体
env = MazeEnv()
agent = QLearningAgent(
state_space=env.state_space,
action_space=env.action_space,
lr=0.1, # 学习率
gamma=0.9, # 折扣因子
epsilon=0.1# 探索率
)
# 记录每轮的总奖励(用于可视化训练过程)
total_rewards = []
# 开始训练(多轮迭代)
for episode in range(episodes):
state = env.reset() # 重置环境到起点
done = False # 是否到达终点
total_reward = 0 # 本轮总奖励
while not done:
# 1. 选动作
action_idx = agent.choose_action(state)
action = env.action_space[action_idx]
# 2. 执行动作,获取反馈
next_state, reward, done = env.step(state, action)
# 3. 更新Q表
agent.update_Q_table(state, action_idx, reward, next_state)
# 4. 更新状态和总奖励
state = next_state
total_reward += reward
# 记录本轮总奖励
total_rewards.append(total_reward)
# 每100轮打印一次进度
if (episode + 1) % 100 == 0:
print(f"Episode: {episode+1:4d} | Total Reward: {total_reward:6.1f}")
# --------------------------
# 可视化1:训练过程中总奖励的变化(看是否收敛)
# --------------------------
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(total_rewards, alpha=0.7)
# 绘制滑动平均(更清晰看趋势)
window_size = 20
if len(total_rewards) >= window_size:
moving_avg = np.convolve(total_rewards, np.ones(window_size)/window_size, mode='valid')
plt.plot(range(window_size-1, len(total_rewards)), moving_avg, color='red', label=f'Moving Avg ({window_size})')
plt.title('Total Reward per Episode (Training Process)')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.legend()
plt.grid(alpha=0.3)
# --------------------------
# 可视化2:测试训练好的智能体(走一次迷宫)
# --------------------------
plt.subplot(1, 2, 2)
# 测试时关闭探索(只利用最优策略)
agent.epsilon = 0.0
state = env.reset()
done = False
path = [state] # 记录走过的路径
while not done:
action_idx = agent.choose_action(state)
action = env.action_space[action_idx]
next_state, _, done = env.step(state, action)
path.append(next_state)
state = next_state
# 绘制迷宫
maze_vis = env.maze.copy()
for (i, j) in path:
maze_vis[i, j] = 4 # 用4标记路径
maze_vis[env.start_pos] = 2 # 起点
maze_vis[env.goal_pos] = 3 # 终点
# 配色:0=白色(可走),1=黑色(障碍),2=绿色(起点),3=红色(终点),4=蓝色(路径)
cmap = plt.cm.colors.ListedColormap(['white', 'black', 'green', 'red', 'lightblue'])
plt.imshow(maze_vis, cmap=cmap)
plt.title('Trained Agent Path in Maze')
plt.xticks(range(5))
plt.yticks(range(5))
# 添加网格线(更清晰)
for i in range(5):
plt.axhline(y=i-0.5, color='gray', linewidth=0.5)
plt.axvline(x=i-0.5, color='gray', linewidth=0.5)
plt.tight_layout()
plt.show()
return agent, env
# --------------------------
# 4. 运行训练
# --------------------------
if __name__ == "__main__":
# 训练1000轮(可根据需要调整)
trained_agent, maze_env = train_maze_qlearning(episodes=1000)
六、代码运行指南
1. 安装依赖(若未安装)
pip install numpy matplotlib
2. 运行效果说明
-
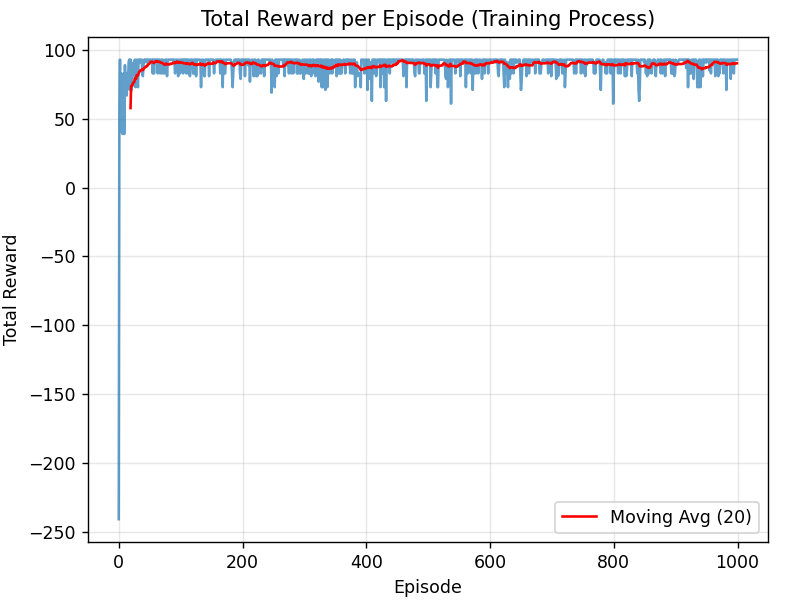
训练过程:每100轮打印一次“轮次+总奖励”,总奖励会逐渐上升(说明智能体在进步)
- 可视化结果:
-
左图:总奖励变化曲线(红色滑动平均曲线会逐渐上升并稳定,说明训练收敛)
-
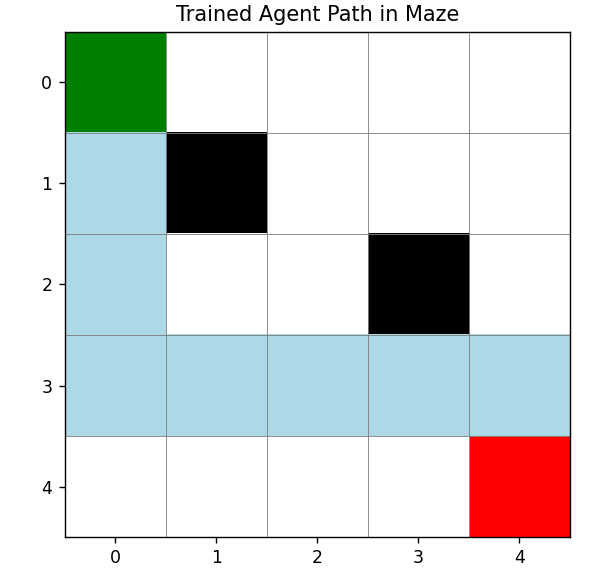
右图:智能体的最优路径(蓝色线从绿色起点到红色终点,避开黑色障碍)
-
七、新手入门小贴士
-
先从简单案例入手:先玩懂网格迷宫、悬崖行走等小任务,再学复杂的DQN、PPO
-
理解Q值的意义:Q(s,a)本质是“状态s做动作a的长期价值”,更新Q值就是在“修正对动作价值的判断”
- 调参技巧:
-
学习率(lr):太大容易震荡,太小收敛慢(建议0.01-0.2)
-
折扣因子(γ):短期任务选小(如0.7),长期任务选大(如0.9-0.99)
-
探索率(ε):可以随训练轮次衰减(如从0.3降到0.01,前期多探索,后期多利用)
-
强化学习的核心是“交互中学习”,动手跑一遍上面的代码,你会对RL的理解更深刻!后续可以尝试修改迷宫地图、调整参数,甚至用RL玩简单的小游戏~
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/LFzZtI4L4ig4ny4NQ1WweQ
https://mp.weixin.qq.com/s/LFzZtI4L4ig4ny4NQ1WweQ
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)