




- @2601_95717211
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Wan 2.7 最近加了一个 Video Edit 模式。和之前的文生视频、图生视频不同,这次是拿一段已有的视频,用一句话告诉模型你想改什么,它就改什么。比如"把背景换成雪山"“让夹克变成红色”。传统视频编辑要开 Premiere 或者 After Effects,一帧一帧调。这个模型的思路是:你说改哪里,它自己处理,其他部分保持不变。实际效果怎么样?我拿一段城市街道行走的视频,测了换背景和改颜色
AI 运动控制这个能力,最近在短视频圈子里传得挺火。简单说就是:给一张人物照片,再给一段舞蹈视频做参考,AI 把舞蹈动作"迁移"到照片里的人身上。听起来像是 deepfake 的变种,但技术路线完全不同——它不是换脸,是让静态人物"动起来"。目前 API 层面能做到什么程度?手臂交叉、快速转身这种复杂动作能不能扛住?不同模型跑同一段参考视频,差距有多大?拿了 Kling 3.0 Pro、Kling

Qwen Image 2.0 今年 2 月上线。之前用 Qwen Image 生成图片要一个 API,编辑图片要换另一个。2.0 把这两件事合到了一起。跑了一下看看实际效果怎么样。

用 API 编辑图片,不画 mask、不框选区域,就用一句话描述"把背景换成深秋的日本庭院"——现在的模型真能做到吗?拿了三个 2026 年新出的图片编辑模型,同一张原图、同一个 prompt,跑了换背景、换风格、改局部元素三组测试。

这是 Wan 2.7 最大的新功能,我觉得也是最有意思的一个。普通 I2V 只能控制第一帧。FLF2V 让你同时控制第一帧和最后一帧——你告诉模型"视频从这张图开始,到那张图结束",中间的过渡它自己想办法。first = wavespeed.upload("./scene_day.jpg") # 白天的街景last = wavespeed.upload("./scene_night.jpg") #

上周帮朋友做一张活动海报,标题就四个字——“AI SUMMIT 2026”。我想着这么简单的事,用 AI 生图几秒钟搞定。结果 Midjourney 给我出了个 “AI SUMM1T 2O2G”。换 Stable Diffusion 试,“AI SUNMIT 2026”。离谱。这个问题我忍了快两年了。每次用 AI 出图,文字部分都得后期自己 P。直到最近试了几个 2026 年新出的模型,发现这事终
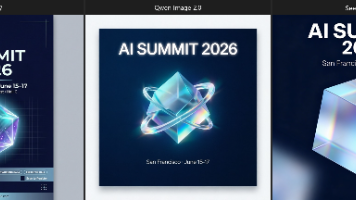
在做营销素材自动化,不同场景需要不同风格的图——产品图要写实、海报要能渲染文字、社交配图要出得快。试了几个模型,记录一下各自的效果和适用场景。
