- @2501_93430156
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
VLA 的定义在社区内出人意料地存在争议,尚未形成明确共识。近期一篇综述论文给出了一个广义定义:“视觉-语言-动作 (VLA) 模型是一个系统,它将视觉观察和自然语言指令作为必要输入,并可能整合其他感官模态。它通过直接生成控制指令来产生机器人动作。是否在某种类型的互联网规模视觉-语言数据上进行过预训练。VLA 是一个使用预训练骨干网络的模型,该骨干网络在互联网规模的视觉-语言数据上训练过,并随后被

从 2025 年 MSSP 的这些顶尖成果来看,智能运维的核心命题已经发生了质变:我们不再追求堆叠模型层数,而是如何让 AI 真正理解机械物理本质,在变幻莫测的工厂环境中提供确定性的答案。机械设备的故障诊断,过去主要依赖振动信号、频谱分析、包络谱、小波变换、经验模态分解等传统方法。今天,我们精选了 10 篇 MSSP 2025 年最具代表性的研究论文,带您梳理智能运维正在发生的五大核心趋势。今天,
近日,华为公司联合上海交通大学与华中科技大学的研究团队,共同推出了一款名为的世界模型。该模型在3D室内场景生成领域取得了显著突破,能够构建面积高达1800平方米(对应19x39个区块)的超大规模虚拟室内环境,并实现了高效的生成速度——在单张NVIDIA A100 GPU上,仅需30分钟即可生成约272平方米的场景。更重要的是,WorldGrow生成的场景不仅具备照片级的真实感和外观细节,其内部的几
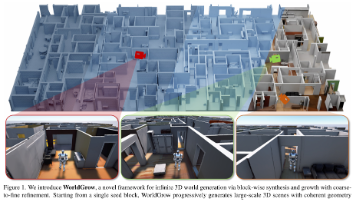
现有的世界模型(在虚拟环境中预测未来的模型)虽然提供了一种可行的替代方案,但它们大多无法支持与现代机器人策略进行复杂的多步交互,存在着视角单一、控制精度不足和长期交互不稳定等问题。该模型的核心思路是:改造一个预训练的视频生成模型,使其能够理解并精确模拟机器人高频动作所带来的多视角视觉变化,从而创建一个可交互的、高保真的机器人虚拟测试环境。该模型通过在虚拟的“想象空间”中模拟机器人的动作结果,不仅能

具身智能是一个广阔且充满活力的交叉学科领域。它不仅是算法的竞技场,也是系统工程、硬件设计与认知科学的交汇点。VLA和RL/IL是两个核心切入点,前者更前沿,后者更扎实。最重要的是,具身智能的研究并非必须依赖昂贵的硬件。利用开源的仿真环境、公开数据集和代码框架,在纯软件层面同样可以开展极具深度的研究。希望这份梳理能帮助你拨开迷雾,找到属于自己的那条研究路径,共同见证这场AI与物理世界融合的浪潮。

当前,虽然大语言模型和图像生成模型已经发展到万亿参数的规模,但人形机器人的控制技术却远远落后,模型规模小、行为单一,且训练过程需要大量人工设计的奖励函数,难以扩展。这种为特定任务手动设计奖励的方式,比如让机器人学会走路的奖励函数,并不能直接用于跳舞或格斗,导致每增加一个新能力,就需要重新设计一套复杂的系统,极大地阻碍了通用人形机器人控制技术的发展。为了解决这个问题,本文提出了一个。

AI圈的"转会地震"比想象中更劲爆!继体育圈的转会乌龙闹剧后,学术与产业双界传来重磅消息——从定义计算机视觉的"数据基石"到开辟具身智能的"产业航道",这位手握多个"奠基级成果"的狠人,若真落地复旦,是否会重塑中国AI从实验室到产业的竞争格局?让我们深扒这位顶流学者的成长轨迹与时代布局。

CoRL 2025(Conference on Robot Learning 2025)作为聚焦机器人与机器学习交叉领域的旗舰会议,近日于 2025 年 9 月 27 日至 30 日在韩国首尔 COEX 会展中心举办CoRL与同馆联办形成 “机器人学习 + 人形机器人” 的交流场景,会议主题涵盖操作、感知、规划与安全、运动控制、人形机器人与硬件等方向,9 月 27 日为工作坊,28 日至 30 日
Humanoid Everyday 项目通过提供大规模、多样化的数据集和标准化的评测平台,为通用人形机器人研究奠定了坚实的基础。实验分析不仅揭示了现有模仿学习方法在处理高维、复杂人形机器人任务时的局限性,也证明了大规模、多样化的数据预训练是提升模型泛化能力的关键路径。面对当前机器人学习数据集主要集中于固定基座机械臂,而现有人形机器人数据集在任务多样性、环境复杂性及人机交互方面存在局限的现状,南加州

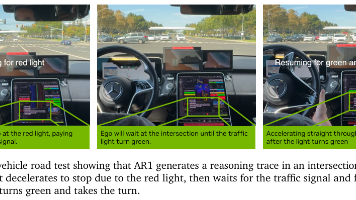
这项研究为自动驾驶领域带来的启示是, 단순히模仿驾驶行为是不够的,赋予模型“思考”和“推理”的能力,是通向更高级别自动驾驶的关键路径。它展示了如何利用大型语言模型的推理能力来解决具身AI(如自动驾驶)中的实际问题,为后续研究提供了一个功能强大且可解释的框架。此外,如何让模型从更少的、更高质量的人类标注数据中学习到更强的因果推理能力,也是一个值得探索的方向。它利用一个强大的视觉语言模型(VLM)来理