




- @2501_92747450
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
此外,对于水下生物多样性的挑战,未来可以尝试将零样本学习(zero-shot learning)或小样本学习(few-shot learning)能力融入模型,使其在面对未知物种时也能做出合理的识别和描述,这对于真正的海洋探索应用至关重要。例如,在低光和浑浊场景下,NAUTILUS (LLaVA-1.5) 的性能提升分别高达7.5和8.1 PR@0.5,充分证明了其在复杂多变的水下环境中的强大适应

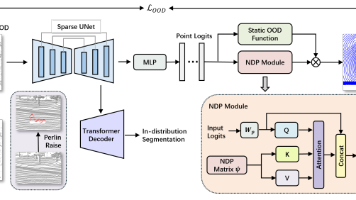
本文提出神经分布先验(NDP)框架,解决LiDAR感知中类别不平衡导致的OOD检测难题。通过可学习的注意力模块动态校准OOD分数,结合Perlin噪声合成OOD样本和软性离群点暴露训练策略,在STU数据集上AP提升超10倍。核心创新在于利用神经网络学习预测分布结构,自适应调整置信度偏差,显著提升自动驾驶场景对未知物体的识别能力。
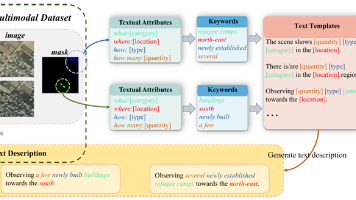
本文提出了一种新颖的遥感变化检测方法S2M,通过从现有掩码标签中自动提取结构化文本信息(位置、类别、类型、数量),实现零成本的多模态监督。该方法采用两阶段训练策略,结合视觉骨干网络和文本引导对齐模块,有效解决了语义模糊性问题。实验表明,S2M在多个数据集上显著优于基线模型,特别是减少了微小目标的漏检。该方法的创新点在于挖掘现有数据的隐含价值,无需额外标注或大模型支持,为资源受限场景提供了高效解决方
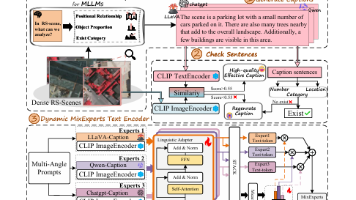
本文提出了一种创新的遥感图像语义分割方法,通过多模态大语言模型生成高质量文本描述来提升分割精度。研究团队设计了动态混合专家文本编码器(DMTE),利用三种不同视角的提示词引导多个MLLM生成多样化描述,并通过门控机制自适应筛选最优文本特征。结合语言查询引导注意力(LQGA)模块,该方法实现了文本语义对视觉特征的有效引导。实验表明,在多个遥感数据集上,该模型在mIoU和mF1指标上均显著优于现有方法
本文提出神经分布先验(NDP)框架,解决LiDAR感知中类别不平衡导致的OOD检测难题。通过可学习的注意力模块动态校准OOD分数,结合Perlin噪声合成OOD样本和软性离群点暴露训练策略,在STU数据集上AP提升超10倍。核心创新在于利用神经网络学习预测分布结构,自适应调整置信度偏差,显著提升自动驾驶场景对未知物体的识别能力。
此外,对于水下生物多样性的挑战,未来可以尝试将零样本学习(zero-shot learning)或小样本学习(few-shot learning)能力融入模型,使其在面对未知物种时也能做出合理的识别和描述,这对于真正的海洋探索应用至关重要。例如,在低光和浑浊场景下,NAUTILUS (LLaVA-1.5) 的性能提升分别高达7.5和8.1 PR@0.5,充分证明了其在复杂多变的水下环境中的强大适应
本周精选10篇CV领域前沿论文,覆盖医疗与生物医学影像、觉定位与多智能体轨迹预测、多模态与视觉-语言模型优化、生成模型与域自适应等方向。全部300多篇论文皆可自取。

摘要:视频扩散模型因Sora的发布引发广泛关注,但其技术门槛显著高于图像生成。核心挑战在于时序一致性(如帧间连贯性)和计算复杂度(如长视频的显存需求)。当前研究聚焦三大方向:1)时序建模(3DU-Net、时空注意力机制);2)高效采样(DiT架构替代传统U-Net);3)可控生成(文本/动作序列等条件输入)。最新突破包括清华VideoScene框架通过3D感知蒸馏实现单步3D场景生成,以及综述研究
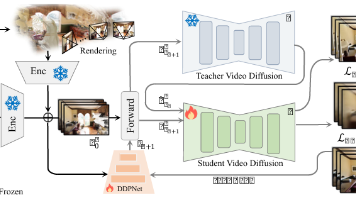
视频理解技术进展与多模态情感分析新方法 近期视频理解领域聚焦时序注意力与跨帧对齐技术,相比传统3D卷积,注意力机制在长视频建模中更具优势。当前研究趋势包括分解式时空注意力、对齐引导注意力和隐式可学习对齐(如NeurIPS 2022的ATA、ICCV 2023的ILA),以解决计算复杂度和运动对齐问题。 在多模态情感分析方向,KAIST提出多模态自注意力网络(MULTIMODAL SELF-ATTE
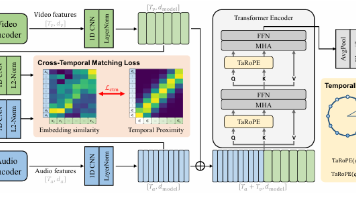
视频理解技术进展与多模态情感分析新方法 近期视频理解领域聚焦时序注意力与跨帧对齐技术,相比传统3D卷积,注意力机制在长视频建模中更具优势。当前研究趋势包括分解式时空注意力、对齐引导注意力和隐式可学习对齐(如NeurIPS 2022的ATA、ICCV 2023的ILA),以解决计算复杂度和运动对齐问题。 在多模态情感分析方向,KAIST提出多模态自注意力网络(MULTIMODAL SELF-ATTE