- @2402_83276047
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
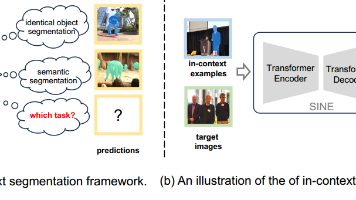
近年来,人们已经探索出了一些通用的分割模型,这些模型可以在一个统一的上下文学习框架内有效地处理各种图像分割任务。上下文分割中的任务歧义性,因为并非所有的上下文分割实例都能准确地传达任务信息。为了解决这个问题,本文提出了SINE(aSIN-contextExamples):一个利用上下文样例的简单图像分割框架。主要方法是利用了一个Transformer编码器-解码器结构,其中编码器提供高质量的图像表
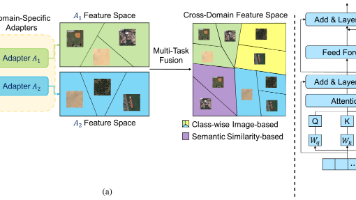
增量学习(Incremental Learning,IL)场景中的遥感模型通常需要应对新出现的类和跨领域的特征转移,本文将这种综合挑战称为跨域 IL现有方法通常单独处理类 IL (CIL)或者域 IL (DIL),无法有效处理跨域转换的重复类,并导致跨域的灾难性遗忘或特征错位。为了解决这一问题,本文提出了一种新的CDIL框架,它将具有领域特定的适配器模块(domain-specific adapt
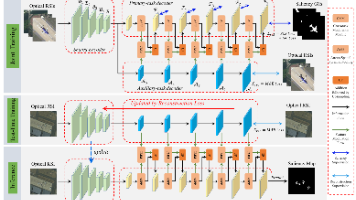
现有的光学遥感图像显著目标检测(RSI-SOD)方法严格遵循传统的"有监督训练-测试"模式,即模型在训练后保持不变并直接应用于测试样本,但由于遥感场景固有的多变性,这种模式在适应test-time图像方面面临着巨大的挑战。显著目标在大小、类型和拓扑结构上都表现出很大的差异,这使得在未见过的测试图像中进行精确定位变得复杂。此外,遥感图像的获取非常容易受到大气条件的影响,通常会导致图像质量下降以及训练
对比"语言-图像"预训练(ContrastiveLanguage-ImageP,CLIP)在各种图像级任务上表现出很强的zero-shot分类能力,因此引出了一系列研究:如何在不进行额外训练的情况下将CLIP应用于像素级开放词汇语义分割。关键是改进图像级CLIP的空间表示,如用self-self注意图或基于VFM的注意图代替最后一层的自我注意图。本文提出了一个新的分层框架CLIPer,它对CLIP
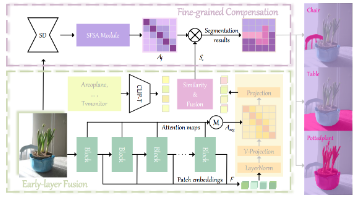
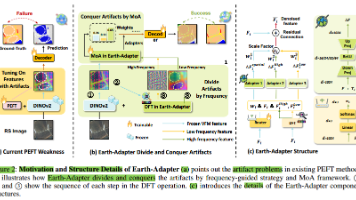
文章来自AAAI2026:在使适应下游任务时,关键的挑战是如何有效地其固有的功能,在这种情况下,方法由于其上级参数性能权衡而成为关键解决方案。但是,虽然功能强大,但在与现有的PEFT方法相结合时,在分割任务中往往会遇到困难,这种限制主要是由于他们无法有效地处理在RS图像中普遍存在的。在自然图像中,通常围绕前景对象,如人类或动物,它们引起的干扰相对有限。相比之下,RS图像由于其俯视视角,缺乏集中的主