- @2401_84586462
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ODS 层,是最接近数据源中数据的一层,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD 层来做。

我们知道一般都是从多个点来画出直线,那么如果点的排列并非能够用一条直线来拟合,但是又需要找到这样一条线来拟合多个坐标轴上面的点,那么一般都是采用曲线进行拟合。但是如何在众多密集且离散的分布点中找到一条曲线来尽可能多的去拟合多个点呢?这就需要我们采取相应的算法或者策略。我们需要使这条直线到各个数据点之间的误差最小且更可能的逼近,那么宏观来看该算法应该是全局最优算法,所以根据此我们使用最小二乘法来拟合
注意:逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息。如果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。当我们用指令设置过期数据后,数据对应的地址会放在expires空间中,存储方式是哈希,存储的value是过期时间。Redis使用内存存储数据,在执行每一
基于es聚合函数bucket_sort、terms和指标聚合cardinality实现。

⚫ 客户端与数据节点的交互是通过来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。在客户端可以使用shell或是JavaApi进行HDFS的简单操作。
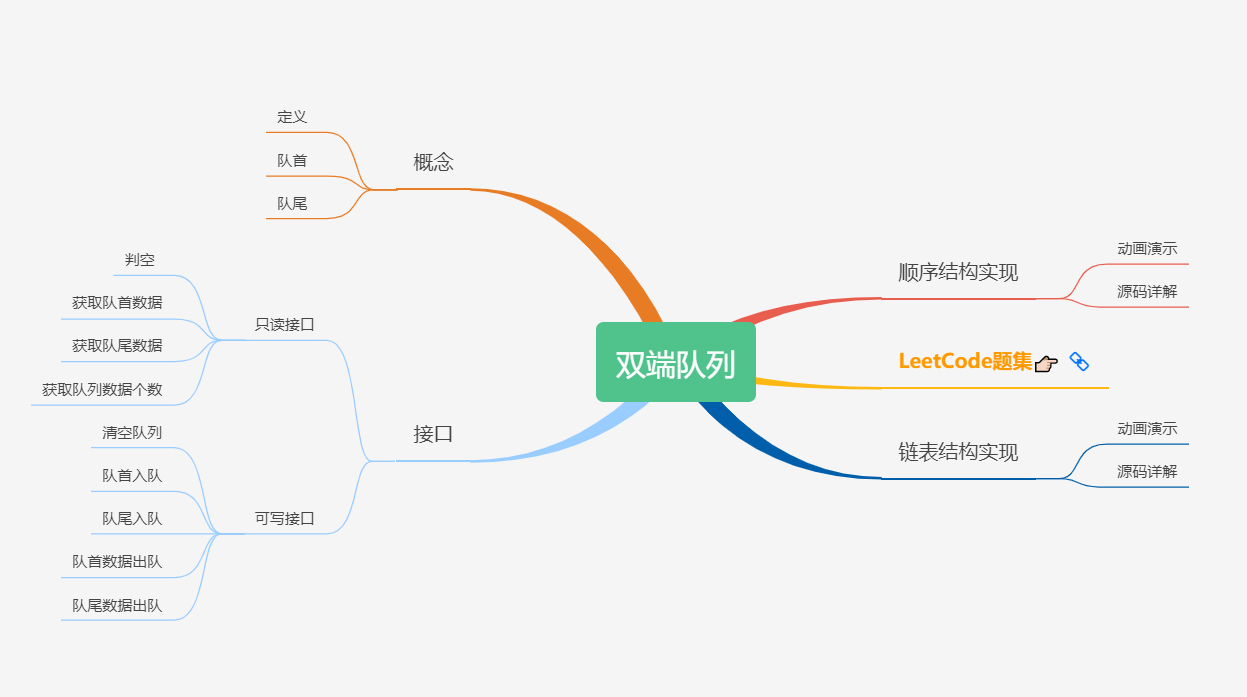
目前本专栏正在进行优惠活动,在博主主页添加博主好友(好友位没有满的话),可以获取付费专栏优惠券。「 数据结构 」和「 算法 」是密不可分的,两者往往是**「 相辅相成 」的存在,所以,在学习「 数据结构 」的过程中,不免会遇到各种「 算法 」。到底是先学 数据结构 ,还是先学 算法,我认为不必纠结这个问题,一定是一起学的。「 增 」「 删 」「 改 」「 查 」**。基本上所有的数据结构都是围绕这
我们知道一般都是从多个点来画出直线,那么如果点的排列并非能够用一条直线来拟合,但是又需要找到这样一条线来拟合多个坐标轴上面的点,那么一般都是采用曲线进行拟合。但是如何在众多密集且离散的分布点中找到一条曲线来尽可能多的去拟合多个点呢?这就需要我们采取相应的算法或者策略。我们需要使这条直线到各个数据点之间的误差最小且更可能的逼近,那么宏观来看该算法应该是全局最优算法,所以根据此我们使用最小二乘法来拟合