




- @2401_83227843
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些技术趋势相当于智能体行业的“基础设施升级”:协议标准化是统一了全国的交通规则,不同地区的车辆都能互通;多智能体协作是从单人作业升级为工厂流水线,分工协作提升效率;多模态能力是给智能体加装了眼睛、手等更多器官,能处理的任务类型大幅增加。基础设施完善后,智能体的落地成本将快速下降,覆盖场景将指数级扩展。
AI智能体(AI Agent)是一种能够感知环境、进行决策并执行行动的智能软件实体,不仅能回答问题,还能调用工具、访问知识库并完成实际任务。其核心是将大语言模型(LLM)与外部能力结合,实现从“聊天”到“干活”的跨越。
AI智能体(AI Agent)是一种能够感知环境、进行决策并执行行动的智能软件实体,不仅能回答问题,还能调用工具、访问知识库并完成实际任务。其核心是将大语言模型(LLM)与外部能力结合,实现从“聊天”到“干活”的跨越。
AI智能体(AI Agent)是一种能够感知环境、进行决策并执行行动的智能软件实体,不仅能回答问题,还能调用工具、访问知识库并完成实际任务。其核心是将大语言模型(LLM)与外部能力结合,实现从“聊天”到“干活”的跨越。
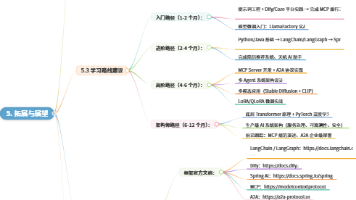
AI智能体开发知识体系分为五大层级,从基础到进阶形成完整能力链路:基础入门层:覆盖大模型背景、提示词工程、开发环境搭建,完成从0到1的认知入门核心原理层:覆盖Transformer架构、RAG技术、Agent核心机制、开发方案选型,理解底层运行逻辑进阶应用层:覆盖低代码平台、模型微调、编程框架、前沿趋势,掌握复杂应用开发能力工程实践层:覆盖MCP/A2A协议、多语言融合、多智能体架构、测试部署,支
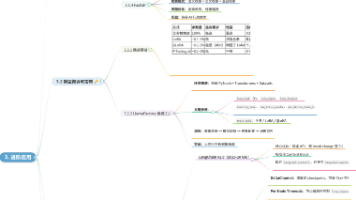
测试部署与可观测性体系相当于智能体系统的“质检运维部门”:上线前做层层检测,保障功能与效果达标;上线后做全链路监控,出问题能快速定位根因;持续做效果评估,指导迭代优化。这是智能体从原型走向生产级应用必不可少的配套体系。
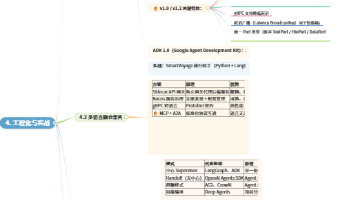
这些技术趋势相当于智能体行业的“基础设施升级”:协议标准化是统一了全国的交通规则,不同地区的车辆都能互通;多智能体协作是从单人作业升级为工厂流水线,分工协作提升效率;多模态能力是给智能体加装了眼睛、手等更多器官,能处理的任务类型大幅增加。基础设施完善后,智能体的落地成本将快速下降,覆盖场景将指数级扩展。
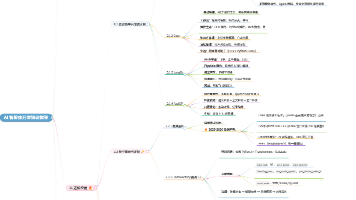
智能体开发方案覆盖从低代码可视化到专业编程框架的多个层级,不同方案在抽象程度、灵活度、开发成本与定制能力上存在明确差异,对应不同的业务场景与开发团队。

大语言模型是基于Transformer架构、通过海量文本数据预训练得到的生成式AI模型,具备自然语言理解、生成、推理等通用能力,是AI智能体的核心决策与推理引擎。
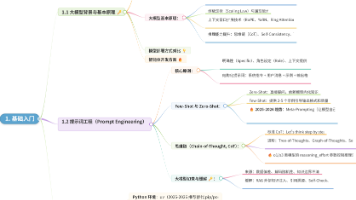
大语言模型是基于Transformer架构、通过海量文本数据预训练得到的生成式AI模型,具备自然语言理解、生成、推理等通用能力,是AI智能体的核心决策与推理引擎。