- @2401_82857325
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2025年昇腾CANN训练营第二季推出系列课程,助力开发者提升算子开发技能。训练营提供0基础入门、码力全开特辑等专题,完成AscendC算子中级认证可获得证书及抽奖机会。文章对比了昇腾算子开发的两种范式:基于Python的TIK/TBE和基于C++的AscendC,通过VectorAdd算子实例展示其差异。TIK需要手动计算参数,类似"汇编级Python";而AscendC采用

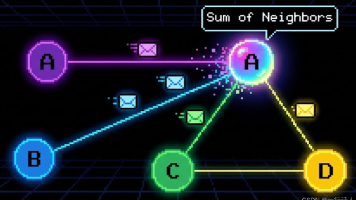
摘要:图神经网络(GNN)的核心计算范式是消息传递(Message Passing),通过边表(Edge Index)实现节点间的信息传递。关键操作为Gather(收集源节点特征)和Scatter(累加到目标节点),需使用原子操作避免写冲突。AscendC实现时采用边中心并行策略,性能优化重点包括:1)对边索引按目标节点排序以减少原子冲突;2)将稀疏图计算转化为SpMM。优化图数据局部性是提升GN
摘要:2025年昇腾CANN训练营第二季推出系列专题课程,助力开发者掌握AscendC算子开发技能,完成认证可获得证书及华为产品奖励。本期重点解析AscendC算子开发微认证攻略,涵盖理论考点(硬件架构、编程模型、API规范)和实操技巧(环境配置、代码补全、避坑指南),并提供考前检查清单。通过认证将验证开发者对AI底层开发的掌握程度,为进阶学习奠定基础。
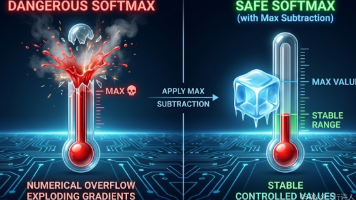
摘要:本文详细解析在昇腾NPU上开发高性能Softmax算子的关键技术。针对FP16数值范围有限的挑战,提出基于x-max(x)的数值稳定方案,避免指数运算溢出。重点剖析AscendC编程中的向量化优化技巧,如使用Brcb指令实现高效广播,避免标量-向量数据搬运开销。同时强调工业级实现中FP16到FP32的精度保护策略,并简要探讨大模型场景下的OnlineSoftmax实现思路。通过硬件特性和算法
《AscendC算子融合技术解析与实践》摘要:本文深入探讨了AscendC平台中算子融合技术在高性能计算中的应用。通过分析计算密度公式FLOPs/Bytes,指出Element-wise操作存在IO瓶颈问题。文章以AddRelu算子为例,对比传统单算子调度与融合方案,展示后者可减少50%IO数据量并提升带宽性能。详细介绍了融合算子的实现方法,包括UB空间规划、原地计算等关键技术,同时指出UB容量、

摘要:本文深入探讨昇腾NPU上数据重排性能优化策略。针对Transpose/Permute操作导致的计算流等待问题,提出三种硬件级优化方案:1)利用MTE引擎的Stride搬运实现内存搬运时的数据重排;2)使用Vector单元的Gather指令处理UB内部细粒度重排;3)借助Cube单元的格式转换电路完成大规模矩阵转置。特别指出,通过MatMul伪计算可充分利用Cube单元的高吞吐特性。文章强调在

摘要:2025年昇腾CANN训练营第二季推出0基础入门、码力全开特辑等专题课程,助力开发者提升算子开发技能。完成AscendC算子中级认证可获证书,参与社区任务更有机会赢取华为手机等大奖。报名链接:https://www.hiascend.com/developer/activities/cann20252

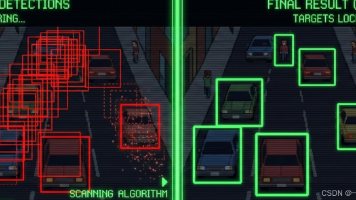
摘要:2025年昇腾CANN训练营第二季提供算子开发课程,助力开发者技能提升。本文重点讲解在AscendC中优化目标检测网络中的NMS(非极大值抑制)算法。针对NMS串行处理的特点,提出"并行IoU+串行Mask"策略,利用Vector指令批量计算交并比,同时保持贪心算法逻辑。详细介绍了AscendC实现方案,包括Kernel类定义、IoU并行计算核心逻辑,并探讨了性能优化方向
摘要:2025年昇腾CANN训练营第二季推出Voxelization算子开发专题,重点解决3D点云处理中的稀疏性、冲突写入和随机访存难题。该算子需将不规则点云转换为规整特征图,核心挑战包括动态输入、并发写入和内存不连续访问。训练营提供从基础到进阶的课程体系,完成认证可获华为设备奖励,助力开发者掌握自动驾驶等领域的LiDAR感知模型优化能力。报名链接:https://www.hiascend.com

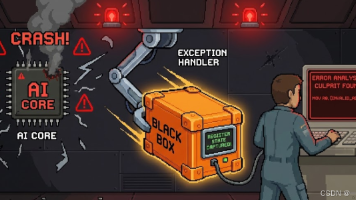
摘要:2025年昇腾CANN训练营第二季提供全场景算子开发课程,助力开发者技能提升。针对NPU算子开发中的致命错误,文章详细介绍了两种调试方法:通过acl.json配置导出异常信息(ExceptionDump)和使用ada工具提取黑匣子日志(BlackBox)。重点解析了常见错误类型(越界写、死锁、栈溢出)的诊断技巧,强调反汇编分析和防御性编程的重要性。训练营还提供AscendC认证和丰厚奖品,报