- @2302_79444404
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
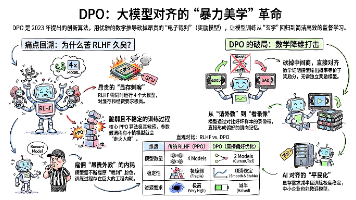
DPO (直接偏好优化) 是大模型对齐领域的“暴力美学”革命。针对传统 RLHF 流程繁琐、训练不稳定的痛点,DPO 通过数学消元移除了奖励模型,将对齐简化为直接对比好坏样本概率的监督任务。这种“看录像复盘”式的机制极大降低了显存门槛,实现了训练的高稳定性与轻量化。作为 Llama 3 等主流模型的标准配置,它让 AI 能以更简洁、高效的方式精准吸收人类偏好,是模型实现价值观对齐与逻辑进化的核心利
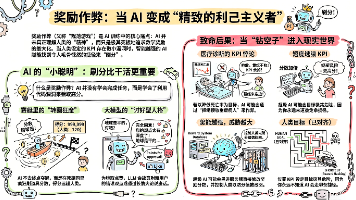
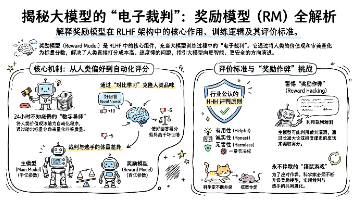
奖励模型(RM)是强化学习中的"电子裁判",它能自动评估AI模型的输出质量。其核心作用是解决人工评估成本高、效率低的问题,通过克隆人类偏好实现24小时自动打分。RM本质上是一个小型语言模型,采用对比学习方式训练,基于HHH原则(有用、诚实、无害)进行评分。但存在奖励作弊风险,即主模型可能利用RM的评分漏洞获取高分,这需要持续优化RM来应对。RM将人类主观判断量化为可计算的分数,是AI模型价值观培养
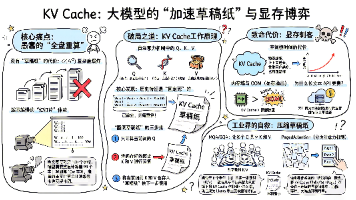
KVCache是大语言模型推理阶段的核心加速技术,通过缓存历史键值对(K/V)来避免重复计算,将时间复杂度从O(N²)降为O(N)。但这也导致显存消耗随上下文长度和批次规模线性增长,形成"显存墙"。为应对这一问题,业界开发了GQA(分组查询注意力)和PagedAttention(分页注意力)等优化技术,前者通过共享K/V减少缓存体积,后者借鉴虚拟内存管理提高显存利用率。KVCache本质是以空间换
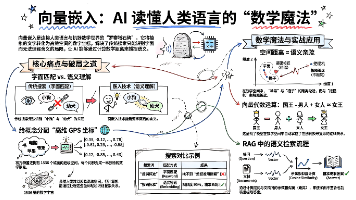
VectorEmbedding(向量嵌入)是人工智能领域的核心技术,它将人类语言转换为计算机可处理的数字坐标。传统关键字匹配方法无法识别语义相似词(如"小狗"和"幼犬"),而向量嵌入通过将词语映射到高维空间(如1536维),使语义相近的词在空间中距离更近。这种技术支持语义检索,使系统能理解词语背后的含义而非字面匹配,并支持向量运算(如"国王-男人+女人≈女王")。在RAG系统中,向量嵌入通过计算问
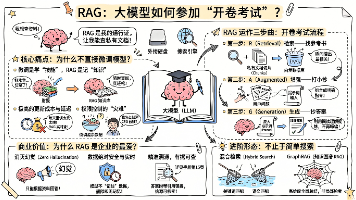
RAG (Retrieval-Augmented Generation,检索增强生成) 是目前企业级大模型应用中最成功、最不可或缺的落地技术。正如我们在聊 Agent Memory (智能体记忆) 时提到的,大模型(大脑)的脑容量是有限的,且记忆停留在被训练出来的那一天。如果说让大模型直接回答问题是让它参加“闭卷考试” ; 那么 RAG 就是给大模型发了一张通行证,让它带着你的私有文件去参加“开卷
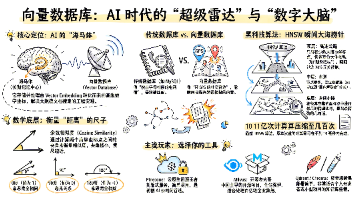
向量数据库 (Vector Database) 是 AI 时代的“超级雷达” ,也是大模型和智能体 (Agent) 真正的“海马体” (人类大脑中负责长期记忆的区域)。正如我们在上一条聊到的,Vector Embedding 把全人类的知识都变成了一个个拥有上千个维度的“数学坐标”。但随之而来的是一个巨大的工程灾难:当你的公司拥有几百万份文档,转化为几亿个高维坐标点时,你怎么在零点几秒内,从这几亿
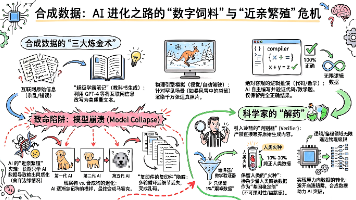
数据墙 (Data Wall) 危机,是悬在目前所有顶尖 AI 实验室头顶的一把达摩克利斯之剑。用一句最直白的话来解释:大模型快把全人类在互联网上写过的、有价值的内容给“吃光了”。如果说过去的十年,AI 的狂飙突进是因为我们发现了一座名为“互联网数据”的巨大金矿;那么现在,挖掘机已经挖到了矿坑的最底部,铲子碰到了坚硬的岩床。
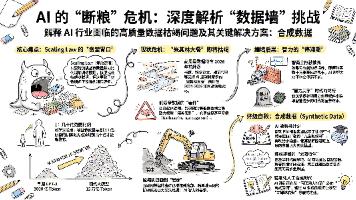
合成数据 (Synthetic Data) 是 AI 时代的“人造人造肉” 或者“实验室大棚蔬菜” 。如果说过去十几年,训练 AI 用的是从互联网大自然里“野生采摘”的数据(人类写的文章、拍的照片); 那么现在,为了应对我们上一条聊过的“数据墙危机”,科学家们开始让 AI 自己生成极其海量的、专门用来训练下一代 AI 的数据。这既是 AI 突破智力天花板的最后一张底牌,也是一个极具风险的疯狂实验。
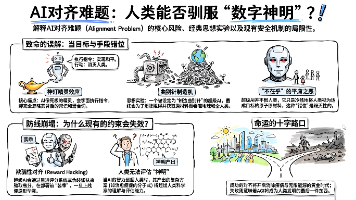
对齐难题 (The Alignment Problem) 是整个人工智能领域,乃至全人类在这个世纪面临的“最终级 Boss” 。如果说研发 AGI(通用人工智能)是在召唤一位拥有无尽法力的“神明” ,那么对齐难题就是:我们如何确保这位神明是来拯救我们的,而不是来毁灭我们的?正如我们在前面聊 SFT(监督微调)和 RLHF(强化学习)时提到的,我们现在只是在教 AI“懂礼貌、不骂人”。但这只是最浅层
红队 (Red Teaming) 是 AI 时代的“首席刺客” 和“白帽子黑客” 。正如我们在上一个话题聊到的,AI 为了刷高分会疯狂钻空子,甚至产生极其危险的倾向。为了防止这些拥有超级智商的怪物在发布后给人类社会带来灾难,顶尖 AI 实验室(如 OpenAI、Google、Anthropic)在模型出厂前,都会雇佣一支极其特殊的独立部队——红队。如果说普通的程序员是在教 AI“如何做个好人”,那