




- @2301_77486062
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以上就是今天介绍的几种深度学习模型和他们的一些常见模型,如果是考虑比较好发论文的话,建议从Transformer方向去做,因为近几年正是Transformer火热的时段,我们有很多比较好的idea可以借用,同时追逐前沿的创新点是比较好中论文的,而CNN和GAN的模块的话,我建议是作为一个小的研究点去做创新,这样可以帮助我们快速出论文。后续为大家讲解代码以及论文的阅读。
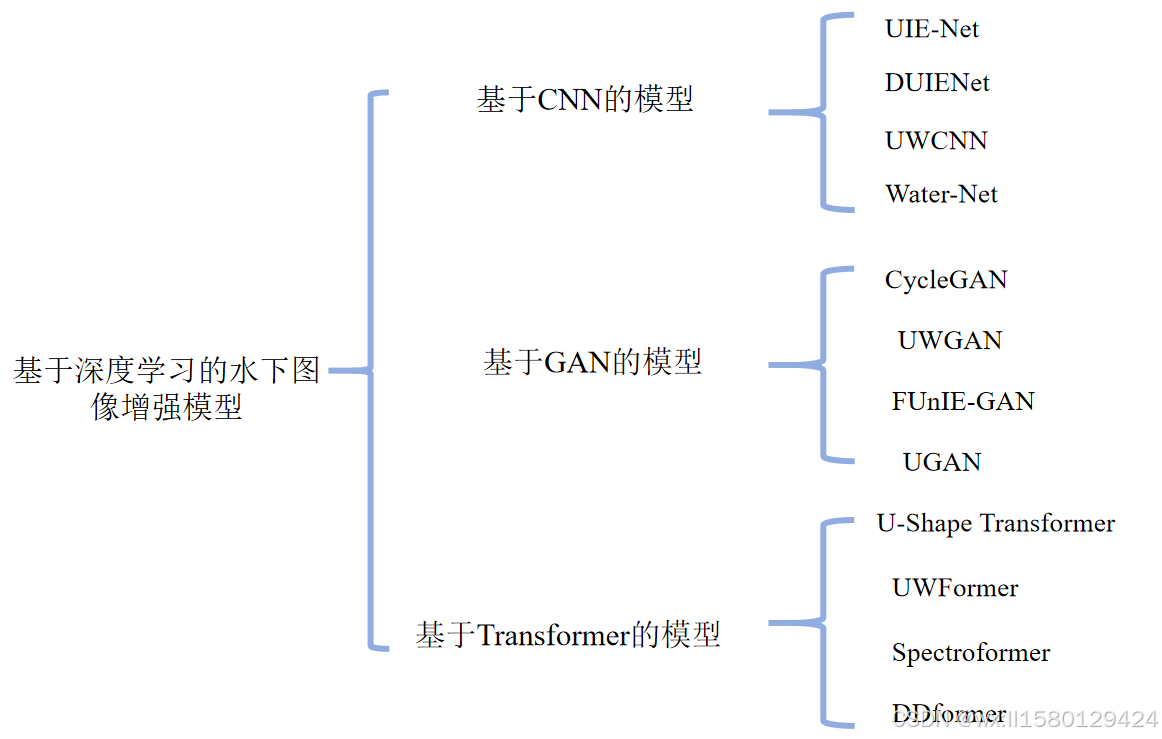
以上就是今天介绍的几种深度学习模型和他们的一些常见模型,如果是考虑比较好发论文的话,建议从Transformer方向去做,因为近几年正是Transformer火热的时段,我们有很多比较好的idea可以借用,同时追逐前沿的创新点是比较好中论文的,而CNN和GAN的模块的话,我建议是作为一个小的研究点去做创新,这样可以帮助我们快速出论文。后续为大家讲解代码以及论文的阅读。
论文题目:Learning A Sparse Transformer Network for Effective Image Deraining论文主要可用模块:TSAK稀疏注意力模块。

以上就是今天介绍的几种深度学习模型和他们的一些常见模型,如果是考虑比较好发论文的话,建议从Transformer方向去做,因为近几年正是Transformer火热的时段,我们有很多比较好的idea可以借用,同时追逐前沿的创新点是比较好中论文的,而CNN和GAN的模块的话,我建议是作为一个小的研究点去做创新,这样可以帮助我们快速出论文。后续为大家讲解代码以及论文的阅读。
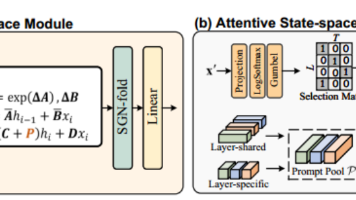
ASE是论文最核心的创新点。传统的Mamba模型存在因果性约束,即当前像素只能访问序列中之前的像素信息,这限制了图像恢复任务中的全局信息利用。而ASE通过引入可学习的提示(prompts)到状态空间方程中,使查询像素能够"跳出"扫描顺序的限制,直接访问图像中任意位置的相关像素,实现了非因果建模能力,打破了传统Mamba的单向依赖局限,显著减少了多方向扫描的计算冗余,提高效率。
以上就是今天介绍的几种深度学习模型和他们的一些常见模型,如果是考虑比较好发论文的话,建议从Transformer方向去做,因为近几年正是Transformer火热的时段,我们有很多比较好的idea可以借用,同时追逐前沿的创新点是比较好中论文的,而CNN和GAN的模块的话,我建议是作为一个小的研究点去做创新,这样可以帮助我们快速出论文。后续为大家讲解代码以及论文的阅读。
论文题目:Learning A Sparse Transformer Network for Effective Image Deraining论文主要可用模块:TSAK稀疏注意力模块。