




- @2301_76800270
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LoRA是一种基于基础模型的微调技术,通过少量数据和低算力需求即可生成特定风格的效果。与Checkpoint相比,LoRA训练时间短、数据量小但依赖基础模型。使用时需设置触发词并调整权重(0.2-0.5之间),权重过高会导致画面扭曲。多个LoRA可混合使用(建议不超过5个)以创造新风格,但需逐个叠加调试。提示词需包含质量描述、主体特征、环境元素等,并参考作者提供的参数设置。手部修复等细节可通过TI

本文分享了几款AI绘画工具及提示词资源的使用体验,主要分为三类:1.在线AI工具(NovelAI、Cerehub等),以动漫风格生成为主,部分提供免费试用;2.提示词资源(PromLib、HuggingFace等),推荐建立个人提示词库,其中PromLib的提示词可视化功能最实用;3.模型平台(CivitAI),提供丰富的优质模型资源。作者强调工具选择因人而异,建议结合自身需求尝试,并逐步构建个人
ComfyUI相较于WebUI在ControlNet应用上的主要区别在于可视化程度和局部控制能力,但核心原理相同。文章详细介绍了ControlNet各类模型的功能分类(如边缘检测、深度控制、姿态控制等)及其典型应用场景(建筑渲染、角色设计、老照片修复等),特别强调了模型版本(SD1.5/SDXL)与图像尺寸的匹配问题。通过线稿上色的具体案例,说明了工作流搭建中需注意参考图尺寸调整、模型兼容性测试以

摘要:本文介绍了在ComfyUI平台搭建基础工作流的关键步骤,包括checkpoint选择、K采样器设置和CLIP提示词撰写。重点解析了checkpoint配置文件的选择标准,需根据模型类型(如V1/V2/动漫)、功能需求(修复/CLIP跳过)和精度要求(fp16/fp32)进行匹配。同时详细对比了6种潜在空间缩放方法的特点和适用场景,并提供了放大模型选型建议(2x/4x/8x)及不同内容类型(动

简单说明提示词的撰写规则,正负向提示词分开撰写,一些模型可能不需要负向提示词就能产出较好的画面,而一些提示词则需要在正向提示词中增加对画面质量的提示词,通用的提示词书写公式:基础公式:人物+场景(实物)+环境/氛围(虚景);进阶公式:光照+镜头
《ComfyUI整合包入门指南》摘要 秋叶发布的ComfyUI整合包为AI绘画爱好者提供了便捷的解决方案。该整合包包含基础工作流、外置VAE、批量生成等核心功能,通过节点式界面实现Stable Diffusion模型的灵活调用。基础工作流包含Checkpoint模型加载、CLIP文本编码、K采样器、VAE解码器等6个关键节点,支持LoRA微调技术和多图批量生成。相比WebUI,ComfyUI具有配

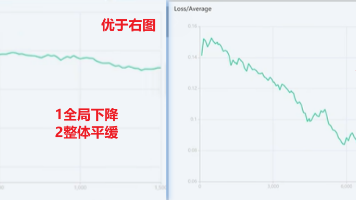
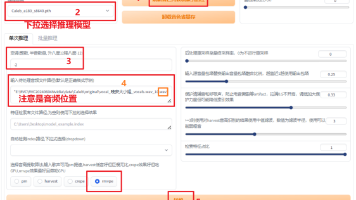
本文总结了AI模型训练的关键要点:1.数据集需高质量且多样化,但要注意版权风险;2.训练参数调节技巧,包括学习率设置、网络大小选择、精度策略等;3.模型评估方法,通过损失曲线判断收敛情况;4.风格LoRA和人物形象LoRA的训练差异。文章还介绍了LoRA模型的作用机制,以及如何通过优化算法和参数调节提升模型性能。这些基础知识适用于在线模型训练平台的使用。
《RVC歌声转换项目使用指南摘要》 该项目是基于检索的声音转换技术(RVC),可实现AI翻唱功能。作者分享了自己在Windows11环境下的部署经验: 下载并解压整合包,替换补丁文件后运行web界面; 数据集准备需经过多步音频处理,建议使用纯净人声; 训练时需注意采样率设置(建议40K)、音高算法选择等参数配置; 推理阶段需根据性别转换调整音调(男转女+7,女转男-7); 项目支持本地部署,整合了
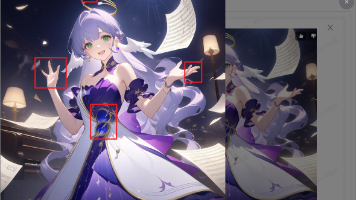
【AI绘画精准控制技巧】本教程主要讲解如何解决AI绘画中面部扭曲问题,并精准控制人物姿势。面部修复建议:1)使用F.1类模型;2)设置较大分辨率;3)开启高分辨率修复;4)使用ADetailer插件(含多种面部/手部/服饰检测模型)。姿势控制主要通过ControlNet实现,支持硬边缘、深度图、姿态等多种控制类型。实操时需注意:选择合适预处理模型,调整控制权重(0.7-1),保持参考图与生成图比例

新手使用在线WebUI生图平台(如LibLib)时,应将其作为学习提示词撰写的入门工具。平台会自动匹配模型和参数,提供风格筛选和一键生成功能,但真正理解生图原理需要转向本地/云部署。选择模型时需注意底模类型、参数设置和版权要求。虽然在线平台操作便捷,但免费服务可能隐藏着长期的学习成本。建议掌握基础后深入接触更专业的部署方式,以获取更全面的参数控制能力。
