【原动力x 降本增效读后感】随感而发!
自我介绍
我是一名全栈开发者,是从微信公众号火爆的那个年代开始接触 IT 互联网行业的,目前在一家设备租赁公司担任技术管理,我的技术栈就不在这里介绍了,比较杂,因为前几家公司都是小公司,那时候老板恨不得把设计也给开了,让你连画图带写页面、带写服务器后端功能,再顺便把数据库和服务器的搭建都搞了。
也就是在那个年代的摧残下,自己一直搞的是全栈,服务器、数据库、后端、前端、微信公众号开发、等等…
现在看来,那个时候是技术门槛低,前端你会个 javascript + html + css 就能出手干活,老板是不愿意单独招一个前端来搭配你干活的,随着互联网的快步发展,技术在不停的更新、改革,我们在不停的学,到了现在这种情况,原本的前端从 简单的 js html css 到了 webpack + vue 或者 Vite + react 、uniapp、flatter等等;服务器也从以前的物理机到云服务器,再到现在的云原生大环境、docker、Kubernetes;快速的技术发展以及日益复杂的技术更新,让原本的全栈,要么学的累死,要么转向一门技术挖深;目前的大环境也是全栈越来越少,现在有的都是之前老程序员遗留下来的,新的全栈有,但是却比之前少了又少。服务器方面也是,原本只需要配置好开发环境、服务器安全、网络工具性能等就可以了。现在的 docker 和 Kubernetes 也是门槛越来越高;docker 还好,玩转 相关的 docker 命令、会写 dockerFile 应付日常开发搓搓有余,但是 Kubernetes 的门槛又在这个基础上增加不少。
关于电子书
首先,活动我是通过之前 CSDN 的技术活动群收到的,里面其实活动倒是挺多,但是很多兴趣倒不是很大,但是这个活动吸引我的,当时就是说电子书下载,我以为能白嫖一个技术类的电子书呢,其实呢,也确实是白嫖,报了名就有了。
然后,在工作之余,划水把整个书快速的过了一遍。
首先,整体来说,整本书还是写的不错的,通过多种方面,各种场景来梳理云原生的现状,以及需要优化的点和现状。其实目前很多公司如果用 Kubernetes 就是这样的,一顿配置,然后把 各个服务挂在各个服务中,然后其实具体每个节点的消耗怎么样,有没有处理?就算发现了有的节点消耗不均,又有没有去解决?
在我看来,一是责任心问题,二是技术问题,两者都有。
文章第一章节:降本增效是企业云原生应用的最大价值
该章节主要讲述了,云原生五大现状是哪些以及如何通过云原生技术进行成本优化,最后给出的结论是:随着云原生技术与业务应用深度融合,可以帮助企业实现更加灵活的弹性资源供给、智能的自动化流量调控。企业可以针对具有业务优先级、资源优先级、明显峰谷特性的业务,进行混部。

第二章节:我所经历的云原⽣降本增效最佳实践案例
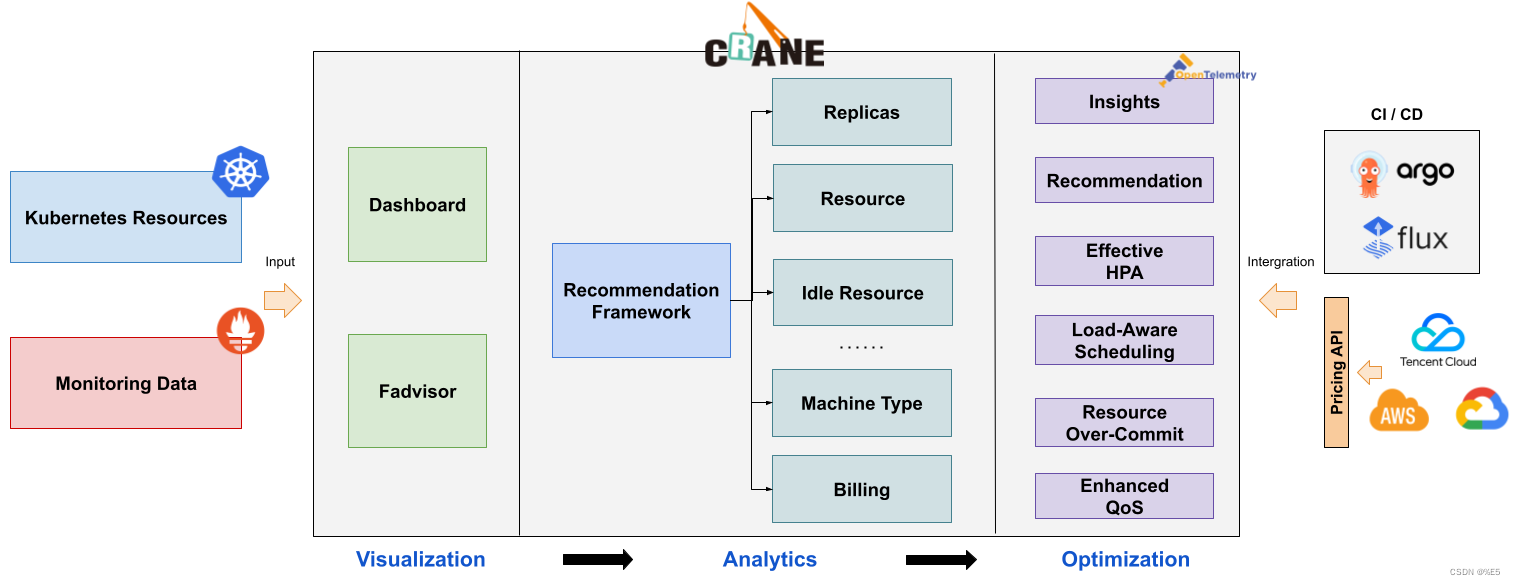
主要讲述的是一个开源项目 —— Crane,它是如何去分析和优化成本的,介绍了该开源项目的能力及产品架构:

腾 讯 开 源 了 一 个 成 本 优 化 项 目 Crane(Cloud Resource Analytics and
Economics),让腾讯自研业务云原生化的经验和工具帮助更多人。Crane 架构具备以下特点:
- 预测为王:可扩展的预测算法;
- 优化为本:基于预测的资源再分配、成本可视化、多维扩缩容;
- 稳定性为根:基于业务优先级的增强 QoS;⼲扰检测和主动回避。
并在腾讯的最佳实践中,列举了一系列的优化成果:
- 节点装箱率参差不齐:近⼀半集群装箱率不⾜ 50%;
- 节点利⽤率低:三分之⼆集群峰值利⽤率不到 40%;
- 业务资源利⽤率低:CPU 利⽤率 15%,内存利⽤率 25%;
- 有效弹性占⽐低:只有 10% 的 HPA 在本年度弹出过。
调研后发现,这是一个普遍现象,为了改善这些问题,腾讯是这样操作的。
第三章:Kubernetes 云上资源的分析与优化
这一章,主要讲述了Kubernetes 云上资源管理的现象,例如:
- 资源预留带来的资源浪费
- 资源紧缺带来的资源浪费
- 大量资源无法使用导致资源浪费
- HPA 原生能力不足
- VPA 工作原理和局限性

整体下来,干货十足,最后也通过基于 Crane 的 Kubernetes 的资源分析与优化
最后也通过各种优化方案和实践案例道出了优化之法。
第四章:Kubernetes 集群利用率提升实践
盖篇章通过利用率提升背景、常见集群负载优化方案思路、负载提升及稳定性优化、三方面进行讲解,最后也给出结论:
腾讯应用实践,分享了 Kubernetes 集群利用率提升的思路和实现方式,包括两级扩容机制、两级动态超卖、动态调度、动态驱逐。
第五章:云原生混部标准解读
该章主要解读了云原生混部标准。
从标准编制背景、云原生混部方案、混部能力要求等方面为我们夯实了最云原生混部的相关知识基础。
第六章:Caelus 全场景在离线混部的思考与实践
本片章,主要分享了腾讯云 Caelus 产品的混部案例实践。
第七章:通过云原生管理 Kubernetes GPU 资源
第七章主要通过,当前 Kubernetes GPU 使用方式、通过云原生方式管理 GPU 资源、通过 qGPU 共享提升 GPU 使用率等多个方面进行了分析和分享。全篇主要围绕 GPU的利用率等方面展开。介绍了如何使用云原生的方式管理 GPU 资源以及通过 qGPU 共享方式提高 GPU 使用率,降低了集群层面 GPU 资源的管理难易程度,使用效率得到提升。
第八章:Kubernetes 精细化调度助力容器资源分配
本章节,围绕 Kubernetes 的资源拓扑感知调度的主题展开。从 CPU 体系结构和吵闹的邻居问题切人,随
后阐述了原生 Kubernetes 的不足和混部场景下的算力感知的局限,最后从采集节点拓扑资源、扩展
Kubernetes 调度器、多级资源 QoS 分配策略几个方面给出了相应的解决方案。在策略的优化后,资源得
到更合理地利用。
未来,Kubernetes 精细化调度将会覆盖更多的场景,例如碎片 GPU、网络拓扑架构、电力调度。
第九章:作业帮云原生降本增效实践之路
本章节主要围绕了作业帮基于云原生进行了一系列改造,最终实现了降本增效,整体的降本服务度已达到 40%,
未来会继续探索更具性价比的降本增效方式。此外,作业帮运营工作当前已实现从靠人到靠平台的过渡,
将进一步向 BI 化、AI 化演进。
这一章节也让我想到了,我们公司当时也是基于这种原因从非容器环境,到了 K8s 环境的一个改革经历。
第十章:游戏平台上云是花钱还是省钱

最后总结,上云究竟是在花钱还是省钱这一问题,不同阶段的考量不同。IDC 部署阶段,由于中小企业基
础设施薄弱,需投入成本增强稳定性与安全性。云原生时期,计费模式带来的成本消耗已作为产品选择的
一条标准早早被纳入考量,除此之外,架构改造与云原生的结合能够有效提升工作效率,为实现长期节约
资源及成本提供了可能性。
全文整体下来,干货还是非常多的,既有一些比较陌生的概念介绍和理论知识的支撑,也提供了几个实际应用场景的特别案例。
个人认为云原生技术确实是一个非常有前景的技术,它可以使得应用程序更加稳定、可靠、高效,并且可以降低IT运维成本,提高企业的竞争力。
云原生技术是针对云计算环境中的应用程序而设计的,它采用了一系列的技术手段,如容器化、微服务架构、自动化运维等,可以使得应用程序具备更高的弹性、更好的可扩展性和更高的可靠性。
通过采用云原生技术,企业可以实现更快的应用程序部署和交付,更高的运行效率和更少的故障停机时间,从而带来更高的生产力和更低的成本。
总之,云原生技术是一个非常有前景的技术,它可以帮助企业实现降本增效,提高企业的竞争力。
个人总结及所想
个人上在云原生方面还是有一些应用经验的,只不过读了这本书后,确实更加通透了一些,期待新的作品。总结全文都是主要讲述目前的云原生现状的一些资源浪费以及利用率低,在我看来实际上就是技术门槛和解决问题的思想方面的问题,文中也给出了一些比较贴合实际的优化方式和洞察点,比如GPU利用率的分析和 精细化调度资源的方法等。
个人总结如下:
云原生目前存在的一些问题
1、有一定技术门槛,云原生技术需要掌握的知识面比较广,需要具备较高的技术水平才能运用得当。
2、不适用于所有项目,云原生需要使用大量的云计算和容器技术,需要大量的硬件和软件支持,因此成本相对较高,不适合小型企业使用。
3、需要有一定的安全意识和解决方案,云原生技术的开放性和灵活性使得其安全风险相对较高,需要加强安全措施来保护数据和系统。
4、需要专人运维,云原生技术需要进行持续集成和持续部署,需要对系统进行不断的监控和调整,因此运维难度较大。
5、云原生技术需要进行多平台兼容,不同平台之间的兼容性可能存在问题,需要进行充分的测试和调整。
云原生的优势所在
1、提高应用程序的可移植性、可扩展性和可维护性。
2、云原生应用程序可以轻松地在不同的云平台上运行,同时也可以根据需要进行水平或垂直扩展。
3、如果技术门槛不少问题,那么就能更高效的资源利用、更快的部署速度、更强的可扩展性、更好的容错能力、更低的运维成本、更好的安全性能。

加入腾讯云活动专属社区不迷路,这里有腾讯云相关活动第一手信息。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)