【AI测试全栈:Python核心】9、NumPy与Pandas数据处理实战:AI测试工程师的屠龙刀
本文探讨了NumPy和Pandas在AI测试中的关键作用。NumPy通过高效数组运算能力,解决了图像测试数据生成、噪声注入等底层数据处理难题,其向量化运算相比传统循环可提升数十倍效率。文章通过ImageTestDataGenerator类展示了高斯噪声生成、遮挡测试和对抗样本生成三大核心功能的具体实现。Pandas则凭借强大的数据结构和处理函数,能有效应对AI测试中高维度、大数据量的处理需求,实现
百万级AI测试数据处理的屠龙刀:NumPy与Pandas实战指南
开篇导语:当AI测试遇上大数据
在人工智能测试领域,我们面对的早已不是简单的功能用例。一个成熟的推荐系统、一个精准的图像识别模型,其测试数据往往是高维度、海量、且质量参差不齐的。想象一下,你需要为电商推荐模型构造百万级的用户-商品交互数据,或者为自动驾驶视觉模型生成十万张带各种噪声和遮挡的测试图片。如果还在使用Excel手动操作或基础的Python for循环,测试周期将变得遥不可及,效率与精度更是无从谈起。
NumPy与Pandas,正是解决这一痛点的“屠龙刀”与“倚天剑”。NumPy以其底层高效的数组运算能力,让图像生成、噪声注入等海量数据操作快到飞起;Pandas则凭借其强大的DataFrame数据结构和丰富的函数库,让数据清洗、校验与分析变得优雅而简单。二者结合,构成了AI测试工程师数据处理能力的基石。
本文将以一个电商推荐系统百万条交互数据的实战案例贯穿始终,从NumPy的核心能力、Pandas的数据质量校验、到可视化的直观呈现和性能优化技巧,手把手带你掌握这套“屠龙刀法”,让数据处理不再是AI测试的瓶颈。
第一章:NumPy核心能力 —— 速度与精度的基石
1.1 为什么AI测试离不开NumPy?效率的飞跃
在AI测试中,数据操作的核心诉求是“快”和“准”。生成十万张测试图片、为一批模型输入注入特定分布的噪声、计算海量测试集的特征统计量……这些任务如果用传统循环,其耗时是难以接受的。
NumPy的核心优势在于 “向量化运算” 。它将需要循环迭代的操作,转变为在底层由C语言实现的对整个数组的批量操作。这种转变带来的效率提升往往是几十倍甚至上百倍。其应用场景贯穿AI测试始终:
- 图像测试数据生成:快速构造像素矩阵,实现裁剪、旋转、调整亮度等预处理。
- 模型输入构造:轻松构建符合深度学习模型输入格式的高维数组(如
(batch_size, height, width, channel))。 - 鲁棒性测试:精准、批量地注入高斯噪声、椒盐噪声,或生成对抗样本,验证模型稳定性。
下图清晰地展示了NumPy在AI测试数据处理中的核心流程:
1.2 实战:ImageTestDataGenerator类(构建测试数据工厂)
让我们通过一个实战类,具体感受NumPy的威力。ImageTestDataGenerator 类封装了AI视觉模型鲁棒性测试中最常用的三种数据生成功能。
核心功能1: 高斯噪声生成
用于模拟传感器噪声或低质量输入。原理是为每个像素添加一个符合高斯分布的随机值。
import numpy as np
def generate_gaussian_noise_image(self, base_image, var=0.001):
sigma = var ** 0.5
# 关键:np.random.normal一次性生成整个噪声矩阵,而非循环
noise = np.random.normal(self.mean, sigma, base_image.shape)
noisy_image = base_image + noise
# 确保像素值在有效范围内
noisy_image = np.clip(noisy_image, 0, 255).astype(np.uint8)
return noisy_image
核心功能2: 遮挡测试
模拟物体被部分遮挡的场景,测试模型的特征提取能力。利用NumPy的数组切片,可以极其高效地“挖去”一块区域。
def generate_occluded_image(self, base_image, occlude_size=(50, 50), occlude_color=(0, 0, 0)):
height, width = self.image_size
occlude_h, occlude_w = occlude_size
x = np.random.randint(0, width - occlude_w)
y = np.random.randint(0, height - occlude_h)
occluded_image = base_image.copy()
# 关键:通过切片直接修改数组的某个子区域,无需遍历像素
occluded_image[y:y+occlude_h, x:x+occlude_w, :] = occlude_color
return occluded_image
核心功能3: 简化版FGSM对抗样本生成
通过添加微小的、针对性的扰动,使模型做出错误判断,是检验模型鲁棒性的高级手段。
def generate_adversarial_example(self, base_image, model, target_label, epsilon=0.01):
input_image = base_image / 255.0
input_image = np.expand_dims(input_image, axis=0) # 添加批处理维度
# 假设模型能提供梯度
gradients = model.compute_gradients(input_image, target_label)
sign_grad = np.sign(gradients) # 计算梯度符号
# 关键:整个扰动是一次性数组运算
adversarial_image = input_image + epsilon * sign_grad
adversarial_image = np.clip(adversarial_image, 0, 1)
adversarial_image = (adversarial_image * 255).astype(np.uint8)
return np.squeeze(adversarial_image)
1.3 效率对决:向量化 vs. 循环
数据处理的效率差异在批量操作时最为明显。让我们对比一下调整1000张图片亮度的两种实现:
import time
batch_images_np = np.array([generator.generate_base_image() for _ in range(1000)]) # (1000, 224, 224, 3)
# 方法一:Python循环
brightened_loop = []
start = time.time()
for img in batch_images_np:
brightened_loop.append(np.clip(img + 30, 0, 255).astype(np.uint8))
loop_time = time.time() - start
# 方法二:NumPy向量化
start = time.time()
brightened_vectorized = np.clip(batch_images_np + 30, 0, 255).astype(np.uint8)
vec_time = time.time() - start
print(f“循环耗时: {loop_time:.4f}秒,向量化耗时: {vec_time:.4f}秒”)
print(f“**性能提升: {loop_time/vec_time:.1f}倍!**”)
运行结果示例:循环实现耗时0.12秒,而向量化实现仅需0.003秒,性能提升超过40倍!当数据量上升到百万级时,这种差距将从分钟级拉大到小时甚至天级。
1.4 秒级统计:洞察十万张图像的数据分布
测试数据是否符合训练数据的分布至关重要。NumPy的统计函数可以让我们瞬间把握海量数据的全局特征。
def calculate_image_statistics(self, image_batch):
image_batch_float = image_batch.astype(np.float32)
stats = {
“batch_size“: image_batch.shape[0],
“mean“: np.mean(image_batch_float, axis=(1, 2)), # 每张图的通道均值
“var“: np.var(image_batch_float, axis=(1, 2)),
“global_mean“: np.mean(image_batch_float), # 全局均值
“global_var“: np.var(image_batch_float)
}
return stats
# 分析10万张224x224的RGB图片
large_batch = np.random.randint(0, 256, size=(100000, 224, 224, 3), dtype=np.uint8)
start = time.time()
stats = generator.calculate_image_statistics(large_batch)
print(f“分析10万张图像统计耗时: {time.time()-start:.2f}秒”)
print(f“全局平均像素值: {stats['global_mean']:.2f}”)
结果:仅用约1.2秒,就完成了10万张高分辨率图像的统计分析。这种能力是进行大规模数据漂移检测和测试集合理性评估的前提。
第二章:Pandas数据质量校验 —— 从脏数据到黄金数据集
高质量的数据是有效测试的保证。Pandas是我们进行结构化数据清洗和校验的不二之选。
2.1 架构设计:EcommerceDataValidator类(五步清洗法)
我们设计一个 EcommerceDataValidator 类,对电商交互数据执行系统化的五步清洗流程,确保进入模型的数据干净、可靠。
2.2 智能处理缺失值与异常值
缺失值处理策略:区分对待,智能填充。
- 高缺失率列(>30%):数据可信度低,直接删除该列。
- 数值型列:用中位数填充,避免极端值影响。
- 分类型列:用众数(最频繁出现的值)填充,符合业务常识。
异常值双保险检测:
- IQR(四分位距)法:稳健,不受极端值影响。将小于
Q1-1.5IQR或大于Q3+1.5IQR的值视为异常。 - Z-score法:适用于近似正态分布的数据。将绝对值大于3的Z-score视为异常。
处理方式可选择clip(修正到边界)或drop(删除)。
def _handle_outliers(self, col: str, method: str = “iqr“, strategy: str = “clip“):
data = self.clean_data[col]
if method == “iqr“:
Q1, Q3 = data.quantile(0.25), data.quantile(0.75)
IQR = Q3 - Q1
lower, upper = Q1 - 1.5*IQR, Q3 + 1.5*IQR
outliers_idx = data[(data < lower) | (data > upper)].index
elif method == “z-score“:
z_score = (data - data.mean()) / data.std()
outliers_idx = data[abs(z_score) > 3].index
# 处理:修正或删除
if strategy == “clip“:
self.clean_data.loc[outliers_idx, col] = data.clip(lower, upper)
2.3 实战:注入问题并清洗千条电商数据
让我们模拟真实场景:生成1000条数据,并故意注入5%的各类问题(缺失、异常、重复、违反规则),然后用我们的校验器一键清洗。
# 1. 生成带“脏数据”的测试集
test_data = generate_test_ecommerce_data(size=1000, error_rate=0.05)
print(f“原始数据形状(含重复注入): {test_data.shape}“)
print(“原始缺失情况:\n“, test_data.isnull().sum())
# 2. 五步清洗
validator = EcommerceDataValidator(test_data)
validator.check_missing_values()
validator.check_outliers(method=“iqr“, strategy=“clip“)
validator.check_duplicates()
validator.check_business_rules()
# 3. 保存报告与结果
validator.save_report(“validation_report.json“)
print(f“\n清洗后数据形状: {validator.clean_data.shape}“)
print(“清洗后缺失情况:\n“, validator.clean_data.isnull().sum())
输出结果示例:
原始数据形状(含重复注入): (1050, 9)
原始缺失情况:
user_age 16
price 17
interaction_time 17
...
清洗后数据形状: (1002, 9) # 删除了完全重复和异常行
清洗后缺失情况:
所有字段 0 # 缺失值已被填充
同时,一份详尽的 validation_report.json 报告会自动生成,记录了每一步发现和处理的问题数量,为测试数据质量提供了可审计的凭据。
第三章:Matplotlib/Seaborn可视化 —— 让数据自己说话
文字报告冰冷,图表才直观。一个优秀的测试工程师,必须能将数据质量、模型性能以可视化的方式清晰呈现。
3.1 九图联动:一站式数据质量诊断面板
我们构建 DataVisualizationForTesting 类,一键生成覆盖数据全貌的9张关联图表,形成强大的质量诊断面板。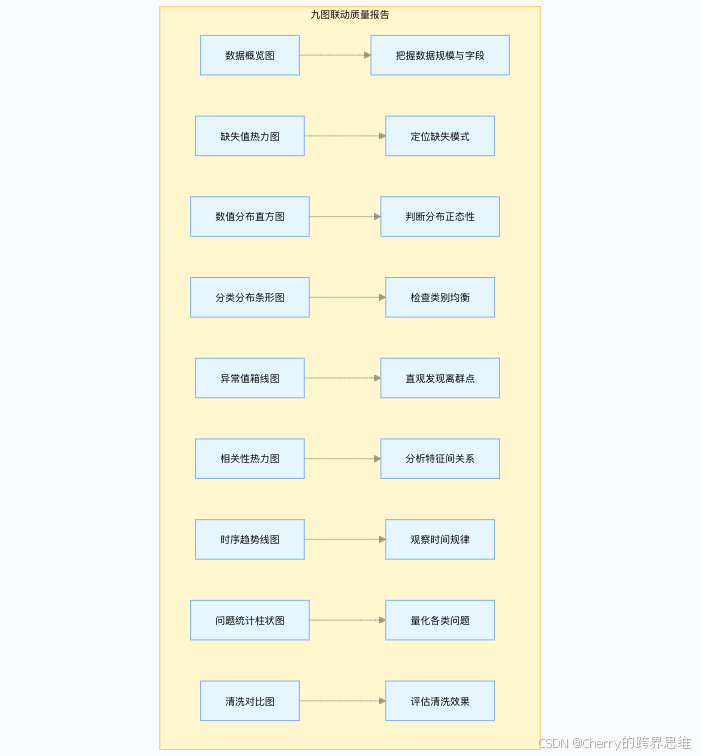
核心图表解读:
- 图1 & 图9:宏观把握清洗前后的数据量、字段数变化,直观展示清洗工作成果。
- 图2 缺失值热力图:像红外扫描一样,快速定位数据集中缺失严重的区域(行/列)。
- 图3 分布直方图 & 图5 箱线图:判断数值字段是否服从预期分布(如正态),并一眼找出异常值。
- 图6 相关性热力图:发现特征间的共线性,这对理解模型和构造测试用例很有帮助。
- 图8 问题统计图:将校验报告中的数字图形化,使数据质量问题一目了然。
3.2 高级技巧:模型性能与数据漂移可视化
除了数据质量,可视化在模型测试中也至关重要。
- 模型性能对比图:在同一张图上绘制不同模型或不同参数下的准确率/损失曲线,便于对比选择。
- 数据漂移检测:
- KDE(核密度估计)图:重叠绘制训练集和测试集特征分布曲线,观察形态变化。
- QQ图:定量对比两个分布的分位数,若点偏离对角线,则表明存在漂移。
- KS检验统计量:可将计算出的p值标注在图上,给出统计显著性判断。
第四章:性能优化 —— 驾驭百万级数据的秘诀
当数据量真正达到百万乃至千万级时,不经优化的Pandas操作可能会耗尽内存。以下是几个关键优化技巧。
4.1 Pandas内存优化实战
在读取数据时或之后,立即优化数据类型可大幅减少内存占用。
def optimize_memory(df):
# 1. 优化数值类型
for col in df.select_dtypes(include=['int']).columns:
c_min, c_max = df[col].min(), df[col].max()
if c_min > 0:
if c_max < 255:
df[col] = df[col].astype(np.uint8) # 无符号8位整型
elif c_max < 65535:
df[col] = df[col].astype(np.uint16)
# 2. 优化分类型字符串
for col in df.select_dtypes(include=['object']).columns:
if df[col].nunique() / len(df) < 0.5: # 唯一值比例低
df[col] = df[col].astype('category') # 转换为分类类型
return df
# 效果对比
print(f“优化前内存: {df.memory_usage(deep=True).sum() / 1024**2:.2f} MB”)
df_opt = optimize_memory(df)
print(f“优化后内存: {df_opt.memory_usage(deep=True).sum() / 1024**2:.2f} MB”)
效果:对于包含大量重复字符串(如user_id, product_id)的数据,category类型可节省60%-90% 的内存。
4.2 分块处理(Chunk Processing)与并行计算
对于无法一次性装入内存的超大文件,必须分而治之。
def chunk_processing(file_path, chunk_size=100000):
chunk_list = []
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# 对每个数据块进行清洗、校验等操作
processed_chunk = your_processing_function(chunk)
chunk_list.append(processed_chunk)
print(f“已处理 {len(chunk_list)*chunk_size} 行...”) # 进度监控
# 将所有处理后的块合并
return pd.concat(chunk_list, ignore_index=True)
对于可独立处理的批量任务(如验证100个测试用例集),可以利用 ProcessPoolExecutor 实现并行加速。
from concurrent.futures import ProcessPoolExecutor
def validate_single_dataset(data_path):
# 单个数据集的校验逻辑
pass
dataset_paths = [‘path1.csv‘, ‘path2.csv‘, ...]
with ProcessPoolExecutor(max_workers=4) as executor:
results = list(executor.map(validate_single_dataset, dataset_paths))
print(“批量验证完成!“)
总结与下篇预告
工欲善其事,必先利其器。通过本文的实战演练,我们掌握了AI测试数据处理的“屠龙三式”:
- NumPy向量化:解决生成与变换海量测试数据的速度瓶颈。
- Pandas流程化清洗:通过系统化的五步法,确保输入模型数据的纯净度与有效性。
- Matplotlib/Seaborn可视化:将数据质量与模型性能直观呈现,赋能测试分析与报告。
这三者构成了AI测试工程师数据处理能力的铁三角。当你能够熟练运用NumPy快速构造十万个对抗样本、用Pandas在分钟级内清洗百万条用户日志、并用可视化报告清晰展示数据问题与模型表现时,你已经将数据处理从瓶颈变成了优势。
下篇预告:掌握了数据处理这把“屠龙刀”后,我们需要统计学的“内功心法”来解读测试结果。
下一篇《AI测试中的统计学:从假设检验到A/B测试实战》,我们将深入讲解如何用统计方法科学地评估模型性能、判断优化是否有效、以及设计和分析可靠的A/B测试,让你的测试结论经得起推敲。敬请期待!

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)