【数据处理、AI大模型、爬虫】python基础部分
本文介绍了Python编程基础语法要点,包括:1. 基本输入输出:print函数用法、格式化字符串、变量赋值规则;2. 数据类型:字符串、整数、浮点数、布尔值的操作;3. 流程控制:条件判断、循环语句(for/while);4. 数据结构:列表、字典的定义和使用;5. 函数定义与调用:参数传递、返回值处理;6. 面向对象:类定义、继承和方法重写;7. 文件操作:读写文本文件的不同方法;8. 异常处
目录
print用法
print("baba!\'"+"nihao")
print("baba\n你好")
print("""锄禾日当午
汗滴禾下土""")输出:
baba!' nihao
baba
你好
锄禾日当午
汗滴禾下土
变量赋值
greet="你好"
greet_chinese=greet
greet_english="hello"
print(greet_chinese)
print(greet_english)你好
hello
命名规则:只能由数字,英文,下划线组成,不能数字开头
空格用下划线命名,小写为主
彩色是关键词,不建议使用成变量名
计算
带小数点的是浮点数,区别于整数
2的3次方 2**3
调用math 函数库
Import math
result=math.log2(8)
print(result)
例如
计算一元二次方程
Import math
a=1
b=2
c=1
delta=b**2-4*a*c
print((-b+math.sqrt(delta))/(2*a))
print((-b-math.sqrt(delta))/(2*a))-1.0
-1.0
Math 数据库可以用哪些呢?
python官方网站有
注释
在代码开头 #
一大段就是 command #可以把每一行都加上#
或者就是“““ ”””
例如
import math
a=1
b=2
c=1
delta=b**2-4*a*c
"""print((-b+math.sqrt(delta))/(2*a))"""
print((-b-math.sqrt(delta))/(2*a))输出
-1.0
数据类型
字符串str
整数int
浮点数 float
布尔类型 bool
空值类型 NoneType
- 字符串长度len()函数,搜索字符串的第几位在字符串变量名后[ ], 从第一位是0 ⚠️空格符号都算一位,\n 换行和 \' 算一位
- 整数和浮点数可以进行加减乘除
- 布尔类型只有True和False(⚠️T和F大写)
- 空值None
type函数可以看出数据类型
例如
#字符串长度
s="Helloworld\n你好"
print(s)
print(len(s))
#通过索引找到单个字符
print(s[0])
print(s[len(s)-1])
#布尔类型
b1=True
b2=False
#空值类型
n=None
#type函数
print(type(s))
print(type(b1))
print(type(n))
print(type(1))
print(type(1.5))
Hello world
你好
14
H
好
<class 'str'>
<class 'bool'>
<class 'NoneType'>
<class 'int'>
<class 'float'>
交互模式
在mac的终端就可以操作
读一行执行一行
- 不需要创建文件就可以运行
- 不需要print就可以看到返回的结果
- 所有的输入指令都不会被保存
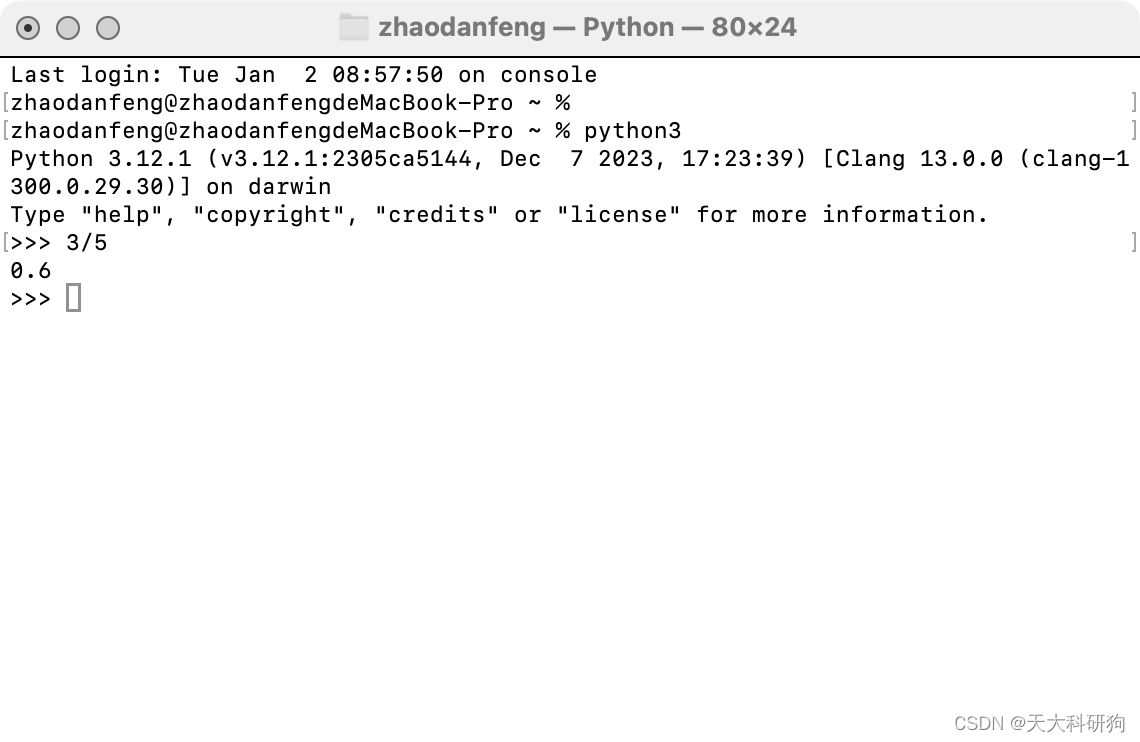
input用户交互模式
input默认都是字符串,所以要进行转换
float()变成浮点数
str()变成字符串
例如:
#计算BMI
user_weight=float(input("您的体重是:(单位kg)"))
user_height=float(input("您的身高是:(单位m)"))
BMI=user_weight/user_height**2
print("您的BMI是:"+str(BMI))
您的体重是:(单位kg)100
您的身高是:(单位m)100
您的BMI是:0.01
user_age=input("输入年龄:")
print("您的年龄:"+user_age)
print("十年后您的年龄:"+str(int(user_age)+10))
输入年龄:25
您的年龄:25
十年后您的年龄:35
可以看出来 input的输出类型是字符串
进行运算必须对其进行变化形式
条件语句:
If(条件):
(缩进4位)执行
else:
判断语句有
==
!= (不等于)
>= <= > <
例如
错误的例子
#今天能打游戏吗
mood_index=int(input("对象心情指数:"))
if[mood_index>=60]:
print("可以出去玩")
else:
print("不玩")对象心情指数:22
可以出去玩
⚠️错误的,if[]一定执行下面的语句,可以用()
正确的是
#今天能打游戏吗
mood_index=int(input("对象心情指数:"))
if mood_index>=60:
print("可以出去玩")
else:
print("不玩")对象心情指数:22
不玩
多层嵌套条件语句
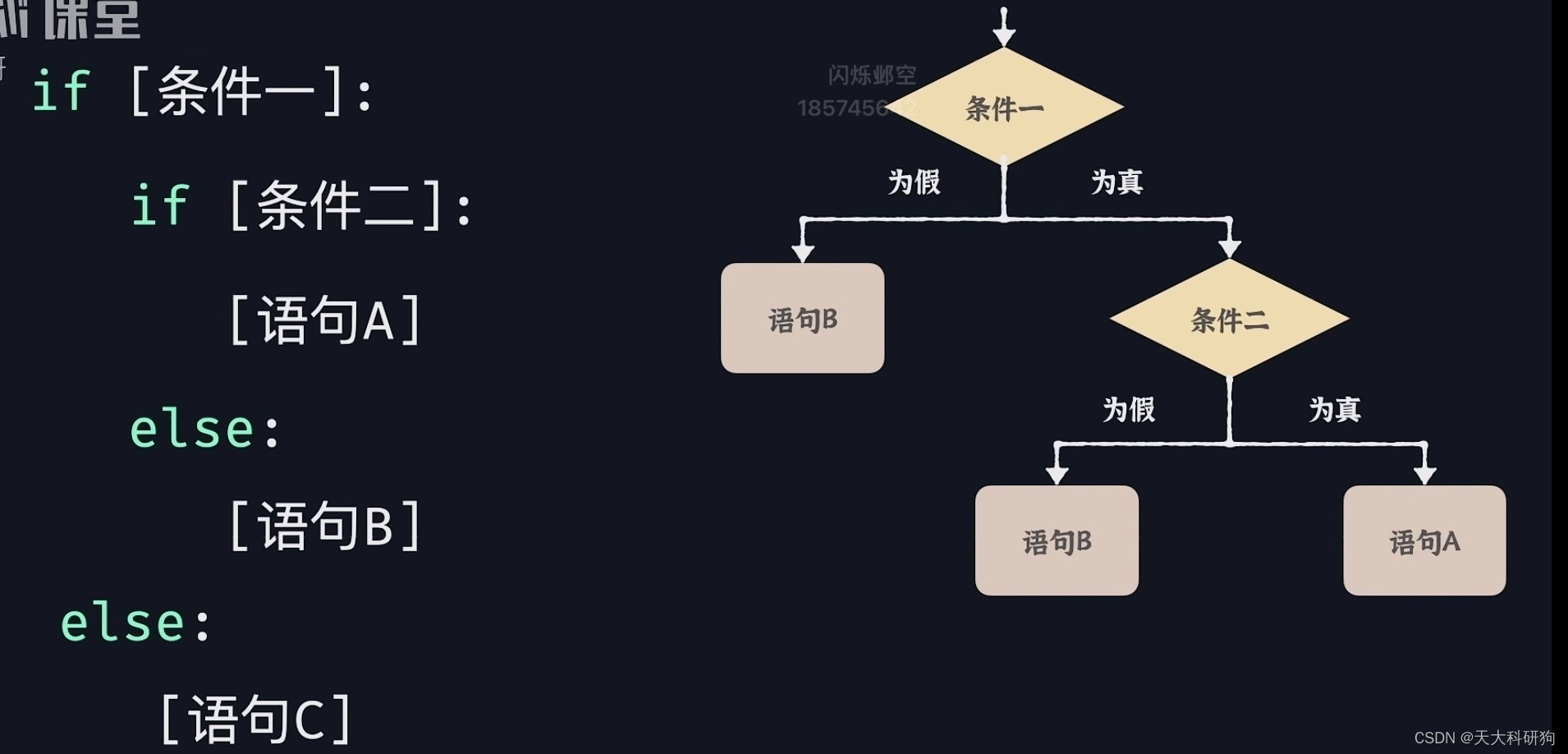
⚠️林粒粒这个图做的有问题的,条件一为假时候应该是语句C
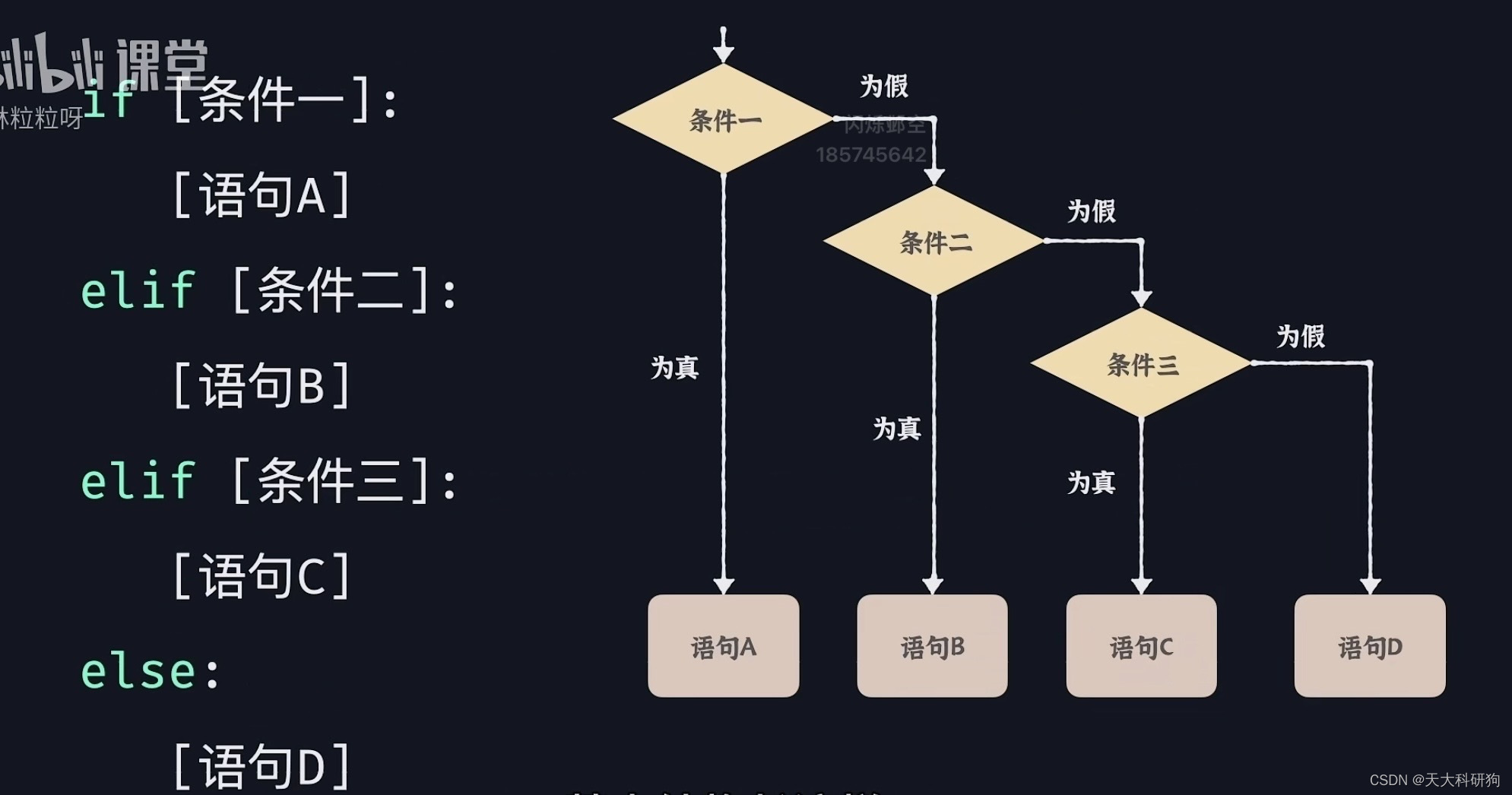
elif语句
语句从上到下的执行
⚠️即使同时满足了条件1和条件3,执行语句A不往下执行
例如:
#计算BMI
user_weight=(float(input("您的体重是:(单位kg)")))
user_height=float(input("您的身高是:(单位m)"))
BMI=user_weight/user_height**2
print("您的BMI是:"+str(BMI))
#偏瘦BMI<=18
#正常18<BMI<=25
#偏胖25<BMI<=30
#肥胖BMI>30
if BMI<=18:
print("偏瘦")
elif 18<BMI<=25:
print("正常")
elif 25<BMI<=30:
print("偏胖")
else:
print("肥胖")您的体重是:(单位kg)80
您的身高是:(单位m)1.8
您的BMI是:24.691358024691358
正常
逻辑语句
语句not>and>or
非 与 或
if(house_work_count>10 and shopping_count>4):
print("好")
else:
print("不好")python列表
列表名=[ , , ]
可以对列表进行 增加内容,减少内容,替换内容,找到单独的元素,
排序,找最大值 最小值
例如:
shopping_list=["kindle"]
shopping_list.append("键盘")
shopping_list.append("键帽") #增加用.append函数
print(shopping_list)
shopping_list.remove("kindle") #移除用.remove函数
print(shopping_list)
print(len(shopping_list)) #列表长度
print(shopping_list[0]) #列表单独元素调用
shopping_list[0]="kindle" #列表单独元素替换
print(shopping_list)
#排序
price=[700,800,1500,900]
max_price=max(price) #列表最大值
min_price=min(price) #列表最小值
sorted_price=sorted(price) #列表从小到大排序
print(max_price)
print(min_price)
print(sorted_price)['kindle', '键盘', '键帽']
['键盘', '键帽']
2
键盘
['kindle', '键帽']
1500
700
[700, 800, 900, 1500]
python字典
键值对,
元组,和list比较像的,但是不可变的
列表方括号,元组()
字典是可变的,可以删除和添加键值对
可以判断某个键是否已经存在,删除已存键,字典的元素个数
例如:结合input 、字典、if判断,只做一个快捷键词典
#结合input、字典、if判断,只做一个快捷键词典
slang_dict={"ctrl+v":"粘贴","ctrl+c":"复制"}
slang_dict["ctrl+x"]="剪切" #字典添加
slang_dict["ctrl+p"]="打"
slang_dict["ctrl+p"]="打印" #字典修改
del slang_dict["ctrl+x"] #字典删除
query=input("输入快捷键")
if query in slang_dict: #in判断是否在字典里
print("找到了")
print(slang_dict[query])
else:
print("没找到"+query)
print("本词典一共"+str(len(slang_dict))+"个")输入快捷键ctrl+p
找到了
打印
输入快捷键ctrl
没找到ctrl
本词典一共3个
python的for循环
循环可以循环字符串,数组,字典
字符串就是每个字母的循环
数组就是每个元素的循环
字典是每个元组循环
for 变量名 in 可迭代的对象:
对每个变量做的事情
数组循环
temp_list=[36,35,37,38]
for t in temp_list:
if t>=37:
print("发烧")发烧
发烧
字典循环
字典的三个方法:
temp_dict.keys() 所有键
temp_dict.values() 所有值
temp_dict.items() 所有 键值对
例如
temperature_dict = {"111":36.4, "112" :36.6, "113":36.2, "114":38}
for temperature_tuple in temperature_dict.items():
staff_id = temperature_tuple[0]
temperature = temperature_tuple[1]
if temperature >= 38:
print(staff_id)114
temperature_dict = {"111":36.4, "112" :36.6, "113":36.2, "114":38}
for staff_id, temperature in temperature_dict.items():
if temperature >= 38:
print(staff_id)114
for循环结合range
for t in range (5,10): # 5开始,10不包含
print (t)
5 6 7 8 9
range(5,10,2)5 7 9
例如计算1+2+3+ 。。。+100
total = 0
for i in range(1, 101):
total = total + i
print(total)python while循环语句
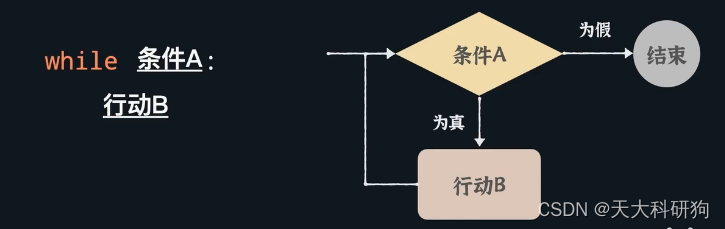
用while语句循环,拍日落
当条件合适,不知道什么时候结束的时候,while循环比for循环更加实用
while和for可以互相转换
比如打印列表里的所有数据
list1=["ni","hi","hello"]
for char in list1:
print(char)list1=["ni","hi","hello"]
for i in range(len(list1)):
print(list1[i])list1=["ni","hi","hello"]
i=0
while i<len(list1):
print(list1[i])
i=i+1⚠️i=i+1;
例如,写一个求平均值的程序,q结束输入
print("这是一个求平均数的程序")
num=0
total=0
user_input=input("请输入数字(到q结束)")
while user_input !="q":
total+=float(user_input) #和total=total+float(user_input)一样
num+=1 #和num=num+1一样
user_input = input("请输入数字(到q结束)")
if num==0:
print("平均数为0")
else:
print("平均数为:"+str(total/num))
格式化字符串
可以对文本进行格式化字符串,也可以对数字格式化
Python中的format方法是字符串格式化的核心工具,通过花括号{}作为占位符来构建动态字符串内容
基本使用方式
format支持两种参数传递方式:位置参数和关键字参数。位置参数按照顺序填充到花括号中,例如"{}吃{}".format("猫","鱼")会输出"猫吃鱼"。关键字参数则通过明确的参数名指定值,如"今年{name}{age}岁".format(name="小明", age=18),这种方式不受参数顺序影响
gpa_dict={"小明":3.251,"小王":3.233,"小李":3.555}
for name,gpa in gpa_dict.items():
print("{0},你好。你的成绩是{1}".format(name,gpa))
print("{0},你好。你的成绩是{1:.2f}".format(name,gpa)) #.2f是指浮点数保留两位小数小明,你好。你的成绩是3.251
小明,你好。你的成绩是3.25
小王,你好。你的成绩是3.233
小王,你好。你的成绩是3.23
小李,你好。你的成绩是3.555
小李,你好。你的成绩是3.56
python函数
DRY原则:不要重复自己的代码
def 函数名(参数1,参数2):
比如计算一个扇形的面积
def calculate_sector(center_angle,r):
area=center_angle/360*3.14*r**2
print("扇形面积为"+str(area))
print(f"扇形面积为:{area}") #接上一节:格式化字符串
calculate_sector(1,1)扇形面积为0.008722222222222223
扇形面积为:0.008722222222222223进程已结束,退出代码为 0
return语句
作用域:如果在函数里的,不会被整体的程序使用,例如
def calculate_sector(center_angle,r):
area=center_angle/360*3.14*r**2
print(str(area))
S1=calculate_sector(1,1)
print(S1)输出
0.008722222222222223
None
如果使用了return函数
def calculate_sector(center_angle,r):
area=center_angle/360*3.14*r**2
print(str(area))
return area
S1=calculate_sector(1,1)
print(S1)
输出
0.008722222222222223
0.008722222222222223
不同函数return返回值是不一样的
print和append默认返回none
len和sum等,返回具体数字
return返回训练:
"""
写一个计算BMI的函数,函数名为 colculate_BMI。
1. 可以计算任意体重和身高的BMI值
2. 执行过程中打印一句话,“您的BMI分类为:xx"
3. 返回计算出的BMI值
BMI=体重/(身高**2)
BMI分类
偏瘦:BMI <= 18.5
正常:18.5 < BMI <= 25
偏胖:25 < BMI <= 30
肥胖:BMI >3
"""
def colculate_BMI(height,weight):
BMI = weight / height ** 2
return BMI
user_weight=(float(input("您的体重是:(单位kg)")))
user_height=float(input("您的身高是:(单位m)"))
user_BMI=colculate_BMI(user_height,user_weight)
print("您的BMI是:"+str(user_BMI))
if user_BMI<=18:
print("偏瘦")
elif 18<user_BMI<=25:
print("正常")
elif 25<user_BMI<=30:
print("偏胖")
else:
print("肥胖")
输出
您的体重是:(单位kg)79
您的身高是:(单位m)1.8
您的BMI是:24.382716049382715
正常
官方的程序对比:
def colculate_BMI(height,weight):
BMI = weight / height ** 2
if BMI<=18:
print("偏瘦")
elif BMI<=25:
print("正常")
elif BMI<=30: #elif已经排除了上一种情况了
print("偏胖")
else:
print("肥胖")
return BMI
result=colculate_BMI(1.8,70)
print(f"你的BMI是{result}")正常
你的BMI是21.604938271604937
官方的没有输入界面
python引入模块
可以从官方引入模块,也可以从第三方引入模块
def median(num_list):
sorted_list = sorted(num_list)
n = len(num_list)
# 如果一共有奇数个数字,取中间那个
if n % 2 == 1:
return sorted_ list[n // 2]
# 如果一共有偶数个数字,取中间两个的平均值
else:
return (sorted_list[n // 2 - 1] + sorted_list[n // 2]) / 2
print(median ( [69, 124, -32, 27, 217]))可以直接转化为下面的
import statistics
print(statistics.median([69, 124, -32, 27, 2171])引入模块的三种方法
- import语句
import statistics print(statistics.median([19, -5, 36])) print(statistics.mean([19, -5, 36])) - from...import...语句
from statistics import median, mean print(median([19, -5, 36])) print (mean([19, -5,36])) - from...import*(库里的所有全部函数调用)但是不推荐,不同的库可能由相同名称的函数
from statistics import * print (median ( [19, -5, 36])) print(mean ( [19, -5, 36]))
第三方模块如何导入
pypi.org网站对第三方模块下载
然后在终端输入pip install,
然后就可以调用了
python面向对象编程
分为两种编程思路
- 面向过程编程 C C++ 类比编年体 函数,拆分成一步步步骤
- 面向对象编程 Java 类比纪传体
面向对象编程,考虑对象有什么性质
类和对象
定义类,从类创建对象
类是模版(可以认为是图纸),对象是从类创建的实例,其中还包含属性。
- 方法,就是放在类里面函数
- 属性,就是放在类里面的变量
定义好类以后,就可以通过类去创建对象,让各个对象去执行这种方法
封装
写类的人,将内部细节隐藏起来,使用的只看外部,不需要了解内部原理
继承
学生父类,大学生和小学生都是这个类的,特征继承
多态
调用写作业方法,但是大学生和小学生因为所属类不同,调用不同的写作业方法。

python创建类
深入面向对象编程的具体语法,创建一个自己的类。
类命名以大写去分割单词
类定义属性
即“对象有什么性质”
class CuteCat:
def __init__(self,cat_name,cat_age,cat_color): #init构造函数方法,括号里可以放任意数量的参数,但是第一个永远是self占用
self.name=cat_name
self.age=cat_age
self.color=cat_color
cat1=CuteCat("Jojo", 2, "orange")
print(f"小猫{cat1.name}的年龄是{cat1.age},他是{cat1.color}")小猫Jojo的年龄是2,他是orange
⚠️课程的展示是_init_,实际在mac上是_ _init_ _
类定义方法
即“对象能做什么事情”
定义方法和定义函数差不多,写在class里面,表示属于该类的方法
也是第一个用self占用
例如
class CuteCat:
def __init__(self,cat_name,cat_age,cat_color):
self.name=cat_name
self.age=cat_age
self.color=cat_color
def speak(self):
print("喵"*self.age)
def think(self,content):
print(f"小猫在想{content}")
cat1=CuteCat("Jojo", 2, "orange")
cat1.speak()
cat1.think("睡觉")喵喵
小猫在想睡觉
应用实例:
# 定义一个学生类
# 要求:
# 属性包括学生姓名、学号,以及语数英三科的成绩
# 2. 能够设置学生某科目的成绩白
#3. 能够打印出该学生的所有科目成绩
class Student:
def __init__(self,name,id):
self.name=name
self.id=id
self.grades={"语文":0,"数学":0,"英语":0}
def set_grade(self,course,grade):
if course in self.grades:
self.grades[course]=grade
def print_grade(self):
print(f"学生{self.name}(学号:{self.id})的成绩为")
for course in self.grades:
print(f"{course}:{self.grades[course]}")
zeng=Student("曾","10086")
zeng.set_grade("数学",95)
zeng.set_grade("语文",94)
zeng.print_grade()学生曾(学号:10086)的成绩为
语文:94
数学:95
英语:0
python类继承
面向对象开发,有一个重要特征是继承,创建有层次的类
继承属性,继承方法
super().__init__()可以调用父类特征
小技巧:什么时候用继承呢?
什么是什么的时候,用继承
人是动物 class人(动物)
应用实例:
# 类继承练习:人力系统
#员工分为两类:全职员工 FULLTimeEmployee、兼职员工 PartTimeEmployee。
# 全职和兼职都有“姓名 name”、”工号id”属性,# 都具备“打印信息 print_info"(打印姓名、工号)方法。
#-全职有"月薪 monthly_salary"属性,
#兼职有"日薪 daily_salary"属性、“每月工作天数 work_days"的属性。
#全职和兼职都有"计算月薪 calculate_monthly_pay”的方法,但具体计算过程不一样
class FULLTimeEmployee(Employee):
def __init__(self,name,id):
super().__init__(name, id)
def salary(self,monthly_salary):
self.monthly_salary=monthly_salary
print(f"月工资:{ self.monthly_salary}")
class PARTTimeEmployee(Employee):
def __init__(self,name,id):
super().__init__(name, id)
def salary(self,daily_salary,days):
self.monthly_salary=daily_salary*days
print(f"月工资:{self.monthly_salary}")
zhao=FULLTimeEmployee("xiaozhao","1001")
zhao.print_info()
zhao.salary(3000)
li=PARTTimeEmployee("xiaoli","1002")
li.print_info()
li.salary(200,15)员工姓名:xiaozhao,工号:1001
月工资:3000
员工姓名:xiaoli,工号:1002
月工资:3000
官方程序如下 文件
class Employee:
def __init__(self,name,id):
self.name=name
self.id=id
def print_info(self):
print(f"员工名字:{self.name},工号:{self.id}")
class FULLTimeEmployee(Employee):
def __init__(self,name,id,monthly_salary):
super().__init__(name, id)
self.monthly_salary=monthly_salary
def calculate_monthly_pay(self):
return self.monthly_salary
class PARTTimeEmployee(Employee):
def __init__(self,name,id,daily_salary,work_days):
super().__init__(name, id)
self.daily_salary=daily_salary
self.work_days=work_days
def calculate_monthly_pay(self):
return self.daily_salary*self.work_days
zhao=FULLTimeEmployee("zhao","1001",6000)
li=PARTTimeEmployee("li","1002",230,25)
zhao.print_info()
li.print_info()
print(zhao.calculate_monthly_pay())
print(li.calculate_monthly_pay())文件读取和写
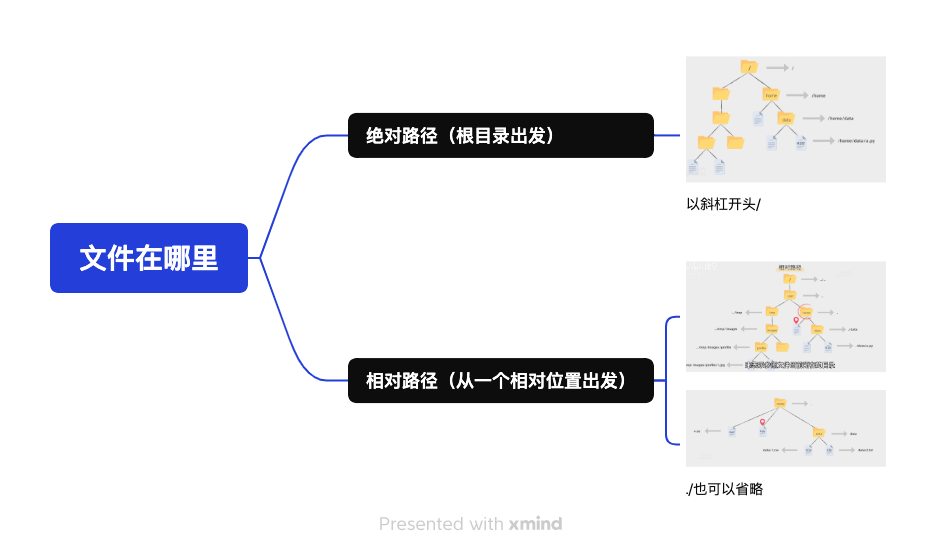
读取文件
有三种读取文件的方法
read
f = open("./data.txt", "r", encoding="utf-8")
#"r"是read的意思,没写也默认是read, encoding="utf-8"是文件编码格式
print(f. read())
# 会读全部的文件内容,并打印
print(f. read))
# 因为上次已经读到最后一行了,所以会读空字符串,并打印
print(f.read(10))
# 会读第1-10个字节的文件内容
print(f.read(10))
# 会读第11-20个字节的文件内容readline
f = open("./data.txt", "r", encoding="utf-8")
print(f.readline())# 会读一行文件内容,并打印为了让文件读到最后,可以和for、while结合
f = open("./date.txt", "r", encoding="utf-8")
line =f.readline()
while line !="": #文件不为空的话
print(line)
line =f.readline() #顺势读取下一行readlines
f = open("./date.txt", "r", encoding="utf-8")
#"r"是read的意思,没写也默认是read, encoding="utf-8"是格式
print(f. readlines())
输出结果,带上了\n
['朝辞白帝彩云间\n', '横看成岭侧成峰\n', '但使龙城飞将在']
readlines经常和for循环结合
f = open("./date.txt", "r", encoding="utf-8")
#"r"是read的意思,没写也默认是read, encoding="utf-8"是格式
lines=f.readlines()
for line in lines:
print(line)
#这里的line是在for循环中自动定义的循环变量。每次循环迭代时,line会自动被赋值为lines列表中的当前元素(即文件的一行内容)。
朝辞白帝彩云间
横看成岭侧成峰
但使龙城飞将在
打开文件之后记得关闭文件以释放资源
f = open("./date.txt", "r", encoding="utf-8")
lines=f.readlines()
for line in lines:
print(line) #对文件的操作
f.close() #关闭文件,释放资源还可以更简单一些,直接with open as f,用完自动释放
with open("./data.txt") as f:
print(f.read()) 写文件
还是用熟悉的with open ("./datatxt","w" ) as f:
with open ("./datatxt","w" ) as f:
#as 后的变量名,就对应着open函数返回的文件对象的名字w只写,会把原来的内容清空
如果不存在一个文件,不会报错,会新建一个文件
with open("./date.txt", "w", encoding="utf-8") as f:
f.write("Hello!")
f.write("yoooo")Hello!yoooo
如果想转行,必须加个转行符号
with open("./date.txt", "w", encoding="utf-8") as f:
f.write("Hello!\n")
f.write("yoooo")Hello! yoooo
如果不想把原来的内容清空,而是在后面附加内容,就用"a"
with open("./date.txt", "a", encoding="utf-8") as f:
f.write("Hello!\n")
f.write("yoooo")a和w一样,如果文件名字不存在,会帮我直接创建一个
⚠️但是a和w都没办法对文件内容进行直接读出,如果想读需要用"r+"
with open("./date.txt", "r+", encoding="utf-8") as f:
print(f.read())
f.write("yoooo")会以追加的形式在后面加上yoooo
课堂小练习
#任务1:在一个新的名字为“poem.txt"的文件里,写人以下内容:
#我欲乘风归去,
#又恐琼楼玉宇
#高处不胜寒。
#任务2:在上面的“poem.txt"文件结尾处,添加以下两句:
#起舞弄清影,
#何似在人间。I
with open("./poem.txt", "w", encoding="utf-8") as f:
f.write("我欲乘风归去,\n又恐琼楼玉宇\n高处不胜寒\n")
with open("./poem.txt", "a", encoding="utf-8") as f:
f.write("起舞弄清影,\n何似在人间。\n")一开始有个问题,如果任务2用a+,使用"r+"模式时,文件指针默认在文件开头,所以添加的内容会覆盖原有内容。建议使用追加模式"a"来在文件末尾添加内容。
程序异常之前,预测一下并解决
在日常编写过程中,存在很多的异常情况
比如:打开文件不存在:FileNotFoundError找不到文件错误;
两个字符串做除法"yoo"*"hi" TypeError类型错误等等
将可能出现错误的代码放到try内,其他的在except
try:
user_weight = float(input("请输入您的体重(单位:kg):")) #在try里面填写有可能产生错误的代码
user_height = float(input("请输入您的身高(单位:m):"))
user_BMI = user_weight / user_height ** 2
except ValueError:
print("输入不为合理数字,请重新运行程序,并输入正确的数字。") #产生值错误时会运行
except ZeroDivisionError:
print("身高不能为零,请重新运行程序,并输入正确的数字。") #产生除零错误时会运行
except:
print("发生了未知错误,请重新运行程序。") #产生未知误时会运行
else:
print("您的BMI值为:"+ str(user_BMI)) #没有错误时会运行
finally:
print("程序运行结束") #不管有没有错误都运行except按顺序进行,第一个except出现之后剩下的就不执行了
对程序进行测试
测试的意义在于检查原来程序的正确,并且在改动时不会牵一发而动全身
assert语句登场
assert 后面跟布尔语句,如果正确就无事发生,如果为假,就会弹出AssertionError(断言错误)程序终止,不出现问题
所以导入测试库也很重要,unittest,python自带,需要用import导入
另外,我们将测试代码放入独立文件里,划分实现代码和测试代码
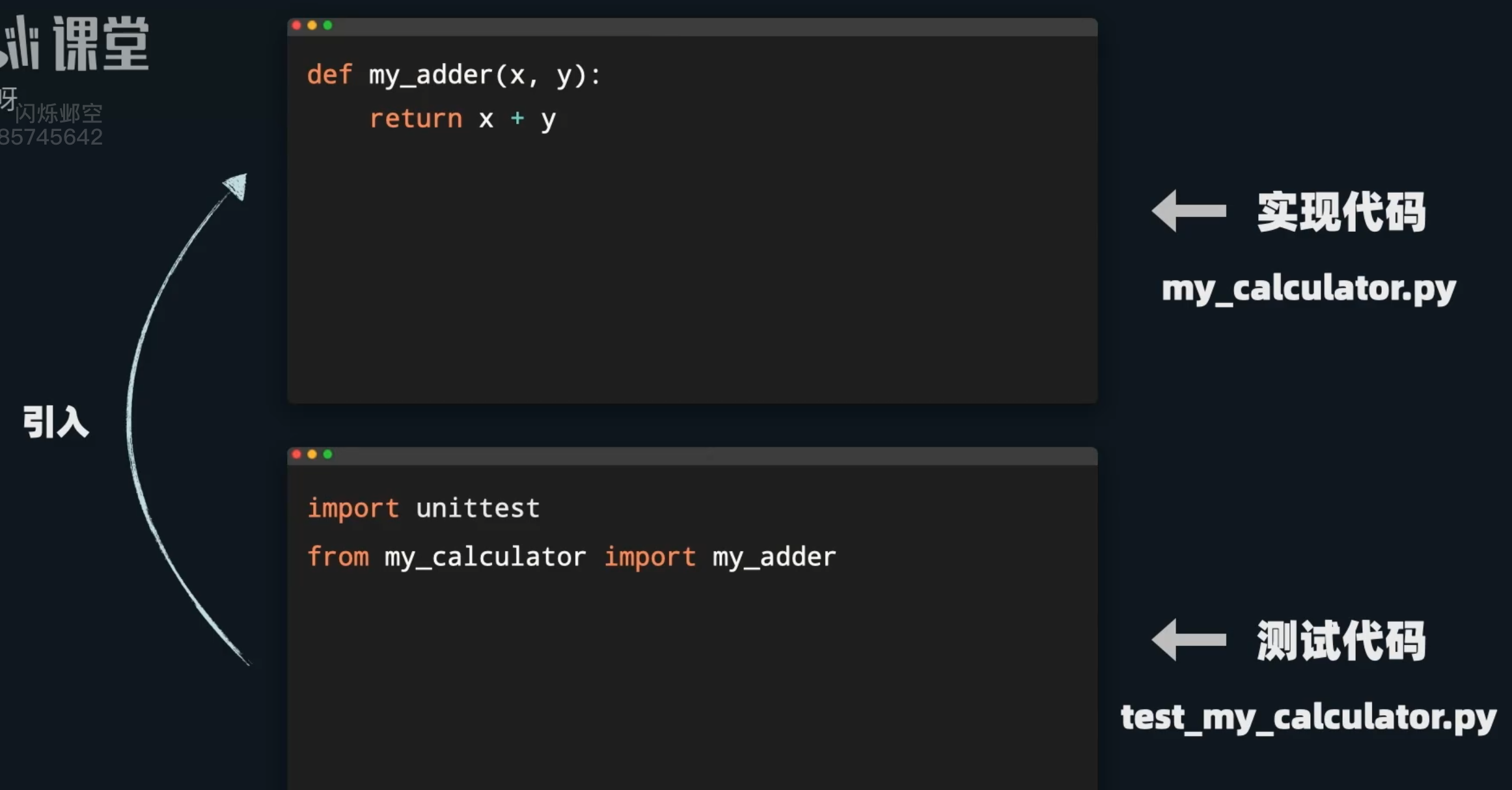
实现代码和测试代码放到同一个文件夹里,测试代码中 ,就是from 文件名 import 函数名(或类名)
实现函数:
def my_adder(x,y):
return x + y测试函数
import unittest
from my_calculator import my_adder
class TestMyAdder(unittest.TestCase): #创建一个类,以test开头,表明是用来测试的类,他要当unittest.TestCase的子类,继承其所有的测试功能
# 在这个TestMyAdder类下面,定义不同的测试用例,每一个用例都是类下面的一种方法,名字必须以test_开头
# 因为unittest库会自动搜索以test_开头的方法,并且只把此当成测试用例
def test_positive_with_positive(self): #如果用assert, assert my_adder(5,3)==8,但是这样的话就会不执行下面的句子
self.assertEqual(my_adder(5,3),8) #直接用self调用父类方法
def test_negative_with_positive(self):
self.assertEqual(my_adder(-5,3), -2)在终端中输入python -m unittest,就可以得到下面的结果
(.venv) (base) zhaodanfeng@localhost pythonProject1 % python -m unittest
..
----------------------------------------------------------------------
Ran 2 tests in 0.000sOK
两个点表示通过了两个测试,如果没有通过,比如:
import unittest
from my_calculator import my_adder
class TestMyAdder(unittest.TestCase):
def test_positive_with_positive(self):
self.assertEqual(my_adder(5,3),7)
def test_negative_with_positive(self):
self.assertEqual(my_adder(-5,3), -2)就会得到:.F(从后往前的)
(.venv) (base) zhaodanfeng@localhost pythonProject1 % python -m unittest
.F
======================================================================
FAIL: test_positive_with_positive (test_my_calculator.TestMyAdder.test_positive_with_positive)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/zhaodanfeng/Documents/python_learn/pythonProject1/test_my_calculator.py", line 8, in test_positive_with_positive
self.assertEqual(my_adder(5,3),7) #直接用self调用父类方法
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: 8 != 7----------------------------------------------------------------------
Ran 2 tests in 0.075s
unittest.TestCase类的常见测试方法
| 方法 | 类似于 |
|---|---|
| assertEqual(A,B) |
assert A==B |
| assertTrue(A) | assert A is True |
| assertIn(A,B) | assert A in B |
| assertNotEqual(A,B) | assert A!=B |
| assertFalse(A) | assert A is False |
| assertNotIn(A,B) | assert A not in B |
理论上说,assertTrue适用于所有方法,但是更推荐有针对性的,这样失败的可以给出具体的原因
assertTrue(2 not in[-1,-2,3] ). 和assertNotIn(2 ,[-1,-2,3] )
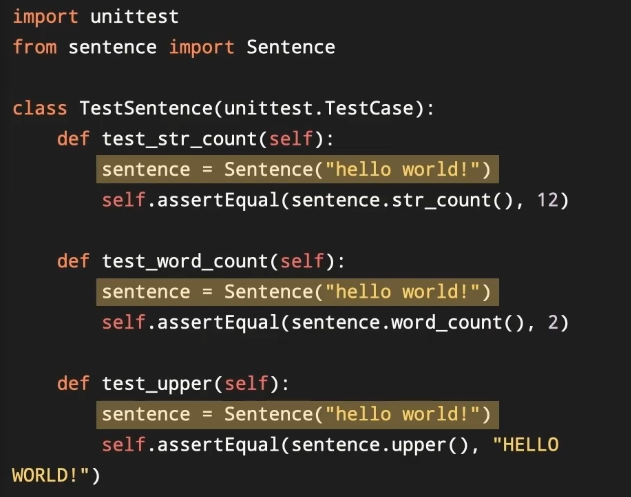
setUp方法
 |
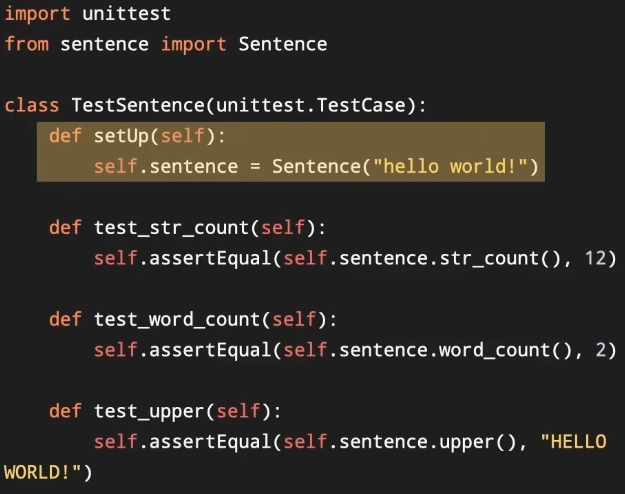 |
因为测试用例是独立的,所以测试不同方法时需要不停的创造新的对象
为了减少不必要的重复,用TestCase类里面的setUp方,在运行test_之前,setUp都会被运行一次,只需要在setUp创建好属性,然后在各个方法里,通过属性(self.sentence)获取已创建好的对象。
举个例子:
class ShoppingList:
#初始化购物清单,shopping_list是字典类型,包含商品名和对应价格例子:{"牙刷":5,"沐浴露":15,"电池":7}
def __init__(self, shopping_list):
self.shopping_list = shopping_list
"""返回购物清单上有多少项商品"""
def get_item_count(self):
return len(self. shopping_list)
"""返回购物清单商品价格总额数字"""
def get_total_price(self):
total_price = 0
for price in self.shopping_list.values():
total_price += price
return total_price方法1️⃣
import unittest
from shopping_list import ShoppingList
class TestShoppingList(unittest.TestCase):
def test_get_item_count(self):
shopping_list =ShoppingList({"牙刷":5, "沐浴露":15,"电池":7})
self.assertEqual(shopping_list.get_item_count(),3)
def test_get_total_price(self):
shopping_list = ShoppingList({"牙刷": 5, "沐浴露": 15, "电池": 7})
self.assertEqual(shopping_list.get_total_price(),27)但是这种方法就会不断的重复shopping_list =ShoppingList({"牙刷":5, "沐浴露":15,"电池":7}),所以选用setUp方法
方法2️⃣
import unittest
from shopping_list import ShoppingList
class TestShoppingList(unittest.TestCase):
def setUp(self):
self.shopping_list=ShoppingList({"牙刷":5, "沐浴露":15,"电池":7})
def test_get_item_count(self):
self.assertEqual(self.shopping_list.get_item_count(),3) #没有定义shopping_list,所以用self.shopping_list
def test_get_total_price(self):
self.assertEqual(self.shopping_list.get_total_price(),27)python高阶和匿名函数
高阶函数
把计算或者其他的过程逻辑保留在原函数里,解决方法就是把计算的函数作为参数去计算
例如:
def calculate_and_print(num,calculator):
result=calculator(num)
print(f"""
|数字参数|{num}|
|计算结果|{result}|""")
def calculate_square(num):
return num*num
def calculate_cube(num):
return num*num*num
def calculate_plus_10(num):
return num+10
calculate_and_print(3,calculate_cube) #计算3的3次方,需要什么函数就传入什么函数|数字参数|3|
|计算结果|27|
先把平方、三次方、加10的函数独立出来,在做计算和打印的函数里,直接调用传入的函数
函数传入函数:把函数作为参数的函数,称之为高阶函数,比如这个里面的calculate_and_print
⚠️calculate_and_print(3,calculate_cube),calculate_cube不需要加()和参数,因为一旦有括号,就调用了这个函数调用后返回的结果了,就不是函数本身了
也可以将格式化函数也作为高阶函数的参数进行传入,例如:
def calculate_and_print(num,calculator,formatter):
result = calculator(num)
formatter(num,result)
def print_with_vertical_bar(num,result):
print(f"""
|数字参数|{num}|
|计算结果|{result}|""")
def calculate_square(num):
return num*num
def calculate_cube(num):
return num*num*num
def calculate_plus_10(num):
return num+10
calculate_and_print(4,calculate_cube,print_with_vertical_bar)其中:print_with_vertical_bar就是格式化函数

主机就是作为高阶函数,其他具体的计算就是作为参数的函数,是配件
匿名函数
只用一次的函数,不用专门的def起名字
直接在调用高阶函数的括号里,放入关键字lambda
例如:
def calculate_and_print(num,calculator,formatter):
result = calculator(num)
formatter(num,result)
def print_with_vertical_bar(num,result):
print(f"""
|数字参数|{num}|
|计算结果|{result}|""")
def calculate_square(num):
return num*num
def calculate_cube(num):
return num*num*num
def calculate_plus_10(num):
return num+10
calculate_and_print(4,lambda num:num*5,print_with_vertical_bar)|数字参数|4|
|计算结果|20|
lambda后面的参数,就是专门传给匿名函数的参数,不需要专门写return的,直接放上要返回的结果
如果有多个函数:
def calculate_and_print(num1,num2,calculator,formatter):
result = calculator(num1,num2)
formatter(num1,num2,result)
def print_with_vertical_bar(num1,num2,result):
print(f"""
|数字参数|{num1,num2}|
|计算结果|{result}|""")
def calculate_square(num):
return num*num
def calculate_cube(num):
return num*num*num
def calculate_plus_10(num):
return num+10
calculate_and_print(4,5,lambda num1,num2:num1*5+num2,print_with_vertical_bar)|数字参数|(4, 5)|
|计算结果|25|
匿名函数除了做高阶函数的参数,也可以定义好之后直接被调用
(lambda num1,num2:num1+num2)(2,3)也有局限:1️⃣只能表示一个语句,不能用于循环递归2️⃣复杂的表示出来可读性也很差。
UTF-8编码

由前缀信息,让计算机辨别各字符在内存里的总长度,解决分割不明的现状
优势:兼容ascii,节约空间,比UTF-32一视同仁更节省空间
主流UTF-8已经是主流,默认选择。但是在老版本的python2可能还是ascii,在python2中len("你好")就会显示是6(在python3中显示为2)
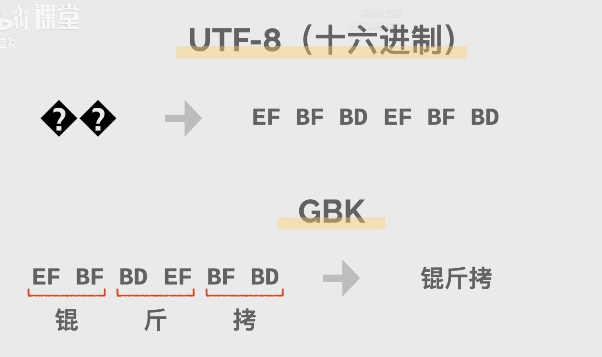
经典乱码锟斤拷是如何形成的?

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)