突破罕见遗传病诊断壁垒:知识图谱增强医学大模型的智能应用
摘要:本研究提出GraphRAG方法,通过构建包含6143个节点和19282条关系的面部表型知识图谱(FPKG),结合Cypher和向量两种检索方式增强大语言模型(LLM)在罕见遗传病诊断中的表现。四维评估框架测试显示,该方法显著提升了GPT-4等模型的诊断准确性(最高达98.6%一致性)和稳定性,降低温度敏感性53.94%。研究验证了结构化知识图谱在减少AI幻觉、提升医疗诊断可靠性方面的价值,为

Graph Retrieval Augmented Large Language Models for Facial Phenotype Associated Rare Genetic Disease
摘要
本文探讨了如何通过图谱检索增强生成(Graph RAG)结合大语言模型(LLM),提升罕见遗传病中面部表型相关诊断的准确性与一致性。我们构建了包含6143个节点和19282个关系的面部表型知识图谱(FPKG),并通过四维评估框架验证了八种LLM的性能。结果显示,RAG显著降低了模型幻觉,提升了诊断决策能力 。
https://github.com/zhelishisongjie/Facial-Phenotype-RAG
正文
引言:罕见遗传病的诊断挑战与新机遇
罕见遗传病通常具有独特的面部表型特征,这些特征往往是诊断的重要线索。例如,在克鲁宗综合征(Crouzon syndrome)患者家庭中,父母与子女的面部特征高度相似,包括下颌前突、眼眶浅、眼球突出及外斜视等 。然而,由于临床数据有限、表型异质性高以及医生对这些疾病的熟悉度较低,罕见遗传病的诊断常常面临延迟 。
随着人工智能技术的进步,大语言模型(LLM)如GPT-4、Claude和Gemini等因其卓越的理解、推理和生成能力,在生物医学领域展现出巨大潜力,特别是在医疗诊断、心理健康、医院管理和医学教育等领域 。然而,LLM在面部表型相关罕见遗传病领域的应用仍面临两大挑战:一是模型生成的“幻觉”(即看似合理但实际上错误的输出),二是缺乏专业领域知识 。
为了解决这些问题,检索增强生成(RAG)成为一种有效方法,通过引入外部知识减少知识密集型任务中的事实性错误 。此外,知识图谱(KG)以结构化的三元组形式([实体]-[关系]-[实体])存储信息,比传统的向量相似性检索更准确,为复杂关系的分析提供了可能 。本文提出了一种创新方法:构建面部表型知识图谱(FPKG),并结合RAG技术,增强LLM在罕见遗传病诊断中的能力 。

方法:构建面部表型知识图谱(FPKG)
我们基于人类表型本体(HPO)构建了一个专门针对面部表型相关罕见遗传病的知识图谱FPKG。该图谱包含6143个节点和19282个关系,涵盖六种实体类型:面部表型、基因型、疾病、变异、患者和文献 。具体构建过程如下:
- 数据筛选
:通过PubMed数据库检索,使用HPO生成的关键词,共检索到25568篇相关文献,经过筛选后保留509篇 。
- 实体与关系提取
:利用PhenoTagger、PubTator和Esearch等工具提取实体,并通过人工审核确定实体之间的关系,最终将结构化数据存储在Neo4j图形数据库中 。
- 图谱结构
:FPKG实体分为五类(面部表型、基因、疾病、患者、文献),关系分为七类(Affect、Cause、From、Exhibit、Have、with_FP、with_Var)。
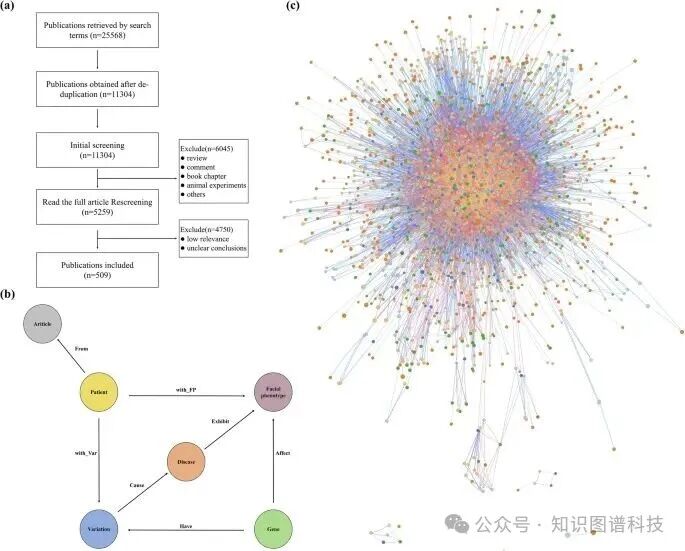
(图展示了知识图谱构建流程,包括筛选过程、FPKG结构和GraphXR可视化概览
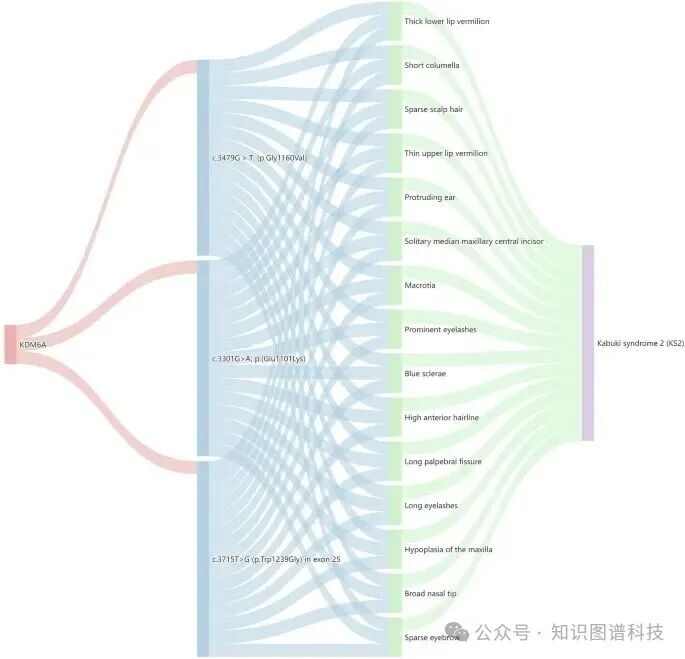
(插图位置提示:原文图5为KDM6A基因的桑基图分析,展示了基因-变异-面部表型-罕见遗传病的关联
FPKG的构建为后续的RAG提供了结构化的知识支持,其可视化结果直观呈现了实体间复杂关系,为研究者分析面部表型-基因-疾病关系提供了有力工具 。
检索增强生成(RAG)的两种实现方式
为了将FPKG与LLM结合,我们采用了两种RAG方法:图谱Cypher检索器(Graph Cypher Retriever)和图谱向量检索器(Graph Vector Retriever)。
- 图谱Cypher检索器
:基于用户查询,LLM生成Cypher查询语句,从知识图谱中精确检索相关信息作为上下文输入,确保回答的准确性和相关性 。
- 图谱向量检索器
:通过命名实体识别(NER)模型识别查询中的实体,将其作为节点添加到图谱中,并嵌入向量表示,检索最相似的子图作为上下文输入 。
两种方法的优势互补:Cypher检索器能精确定位知识图谱中的上下文,但依赖LLM生成查询语句的能力;向量检索器则在查询生成能力较弱时仍能有效检索相似子图 。
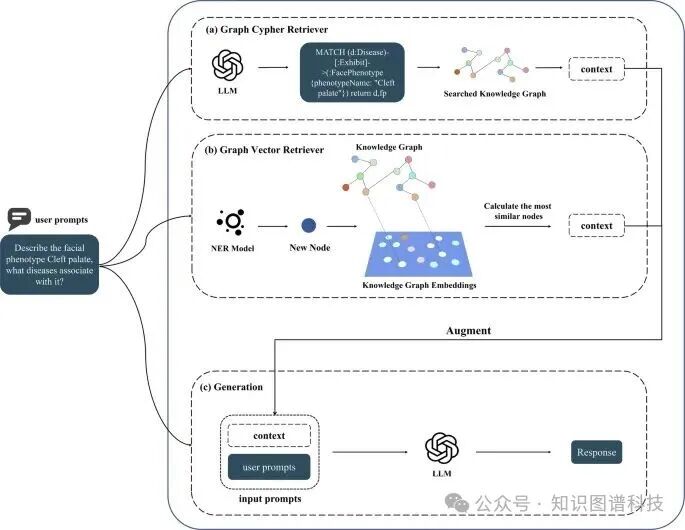
(图展示了两种Graph RAG的流程图,包括Cypher检索器和向量检索器的具体实现步骤
实验设计与结果:全面评估RAG增强LLM的性能
为了验证RAG在罕见遗传病诊断中的效果,我们设计了四维评估框架,涵盖领域知识问答、诊断测试、一致性评估和温度分析,并对八种LLM进行了测试 。同时,我们构建了三个针对面部表型相关罕见遗传病的基准数据集,用于支持实验 。以下为具体实验设计与结果:
1. 领域知识问答(Domain-specific QA)
我们向LLM提出与领域相关的具体问题,并根据HPO参考答案评估其响应质量。结果显示,结合RAG的LLM在回答准确性上显著优于未经增强的模型 。
2. 诊断测试与一致性评估
在诊断测试中,每道问题重复提问五次以计算平均准确率;在一致性评估中,同样重复提问以评估回答的一致性。结果表明,RAG增强的LLM在诊断准确率和回答一致性上均有显著提升 。
3. 温度分析
温度参数对LLM输出随机性有重要影响。我们研究了不同温度参数对模型性能的影响,发现RAG方法将温度引起的变异性降低了53.94% 。
4. 性能对比
在所有实验中,RAG增强的LLM始终优于未增强的模型。其中,GPT-4-turbo、GPT-4o和Claude-3-Opus在罕见遗传病领域的表现最为突出 。
讨论:RAG与知识图谱对罕见遗传病诊断的意义
本研究表明,LLM结合领域特定知识图谱(如FPKG)能够有效减少幻觉,提升回答一致性和准确性,尤其在低流行率、高风险的罕见遗传病领域具有重要意义 。具体而言:
- 临床视角
:RAG增强的LLM为临床医生提供了更准确的诊断支持,特别是在数据有限、医生不熟悉的罕见病领域 。
- 患者视角
:标准化的响应帮助患者及家属更好地理解疾病,提升医疗信息获取的便利性 。
- 研究视角
:RAG LLMs帮助研究者深度分析面部表型-基因-疾病之间的复杂关系,发现潜在关联和模式 。
论文评价
优点与创新
-
构建了面部表型相关的罕见遗传疾病知识图谱(FPKG),包含6143个节点和19282个关系,涵盖六种实体类型(面部表型、基因型、变异、样本、疾病、文章)。
-
结合了两种检索增强生成(RAG)方法(Cypher RAG和Vector RAG),以解决LLMs的幻觉问题和在专业领域回答问题时的能力不足。
-
开发了三个基准数据集,并建立了四维评估框架(领域知识问答、诊断测试、温度敏感性和响应一致性),以评估八种LLMs的性能。
-
实验结果表明,RAG LLMs在所有实验中均优于传统的LLMs,显著提高了诊断准确性和响应一致性。
-
RAG LLMs显著减少了温度引起的变异性,平均降低了53.94%。
-
通过结合领域特定的知识图谱,LLMs能够有效减少幻觉,提高一致性和准确性,特别是在低发病率、高风险条件下,即使是很小的准确性提升也能显著改善患者预后。
不足与反思
-
每种RAG方法都有其局限性,Cypher RAG在与生成能力较弱的LLMs(如Gemini-pro)结合时表现较差,而Vector RAG虽然不受生成Cypher查询的限制,但在查询知识图谱时的准确性不如Cypher RAG。
-
RAG LLMs严重依赖知识图谱的数据,而当前的知识图谱尚未完全覆盖该领域的知识。当图中无法查询到相关信息时,LLMs会依赖于其预训练的知识,这可能会导致幻觉,尽管提供了更广泛的覆盖范围。
-
知识图谱的大小和范围可以在未来的研究中进一步扩大,以涵盖更多的面部表型和相关遗传疾病。此外,可以探索更先进的检索机制以提高检索查询的准确性和效率。
-
未来研究可以进一步探索RAG LLMs在以下领域的应用:(1)从医生的角度来看,RAG LLMs可以帮助医生快速识别疾病,特别是在处理复杂的罕见病例时;(2)从患者的角度来看,RAG LLMs可以在特定领域提供更标准的响应,帮助患者和家庭更好地理解疾病并提高获取医疗信息的便利性;(3)从研究人员的角度来看,RAG LLMs可以协助研究人员深入分析复杂的面部表型-基因-疾病关系,揭示更多潜在的关联和模式。
关键问题及回答
问题1:在构建面部表型知识图谱(FPKG)时,研究团队采用了哪些具体的方法和工具?
-
文献搜索:首先,研究团队通过PubMed数据库进行综合搜索,使用人类表型本体(HPO)生成的搜索词,筛选出509篇与面部表型相关的罕见遗传疾病研究文献。
-
实体提取:使用PhenoTagger、PubTator和Esearch等工具从筛选后的文献中提取实体(如面部表型、基因、疾病等)和它们之间的关系。
-
手动验证:提取的结构化数据经过多次手动审核和格式化,最终存储在Neo4j图数据库中。
-
可视化:为了更直观地理解和展示知识图谱的内容和关系,研究团队还提供了知识图谱的可视化。
问题2:在检索增强生成(RAG)方法中,Cypher RAG和Vector RAG各自的优势和局限性是什么?
-
Cypher RAG:
-
优势:利用LLMs生成结构化图查询,通过Neo4j的Cypher查询精确检索相关子图。这种方法能够确保检索到的信息是准确和相关的。
-
局限性:依赖于LLMs生成正确的Cypher查询,如果LLMs的生成能力较弱,可能会影响检索效果。
-
-
Vector RAG:
-
优势:采用生物医学命名实体识别模型和图嵌入算法进行相似性检索,适用于LLMs生成能力有限的场景。向量匹配能够有效捕捉潜在的模糊关联。
-
局限性:虽然能够处理生成能力较弱的LLMs,但在检索准确性上可能不如Cypher RAG,尤其是在处理复杂查询时。
-
问题3:实验结果显示,RAG LLMs在诊断测试中的一致性表现如何?与其他LLMs相比有何改进?
-
一致性评估:研究团队对每个问题进行了五次重复查询,计算答案的一致性。一致性定义为五次响应中最常见答案的比例。
-
结果:RAG LLMs在所有数据集中均表现出较高的一致性。特别是GPT-4-turbo和Claude-3-opus在选择性测试中表现出极高的一致性,分别为96.2%(非选择性)和98.6%(选择性)。
-
改进:与vanilla LLMs相比,RAG LLMs的一致性显著提高。例如,在GMDB集的非选择性测试中,RAG LLMs的平均一致性达到了86.50%,而vanilla LLMs仅为41.80%。这表明RAG方法通过提供结构化的检索知识,显著减少了LLMs回答的不确定性。
结论与展望
通过构建FPKG并结合RAG技术,我们验证了LLM在罕见遗传病诊断中的潜力。实验结果显示,结构化知识图谱能够有效提升模型的准确性和一致性,并显著降低温度参数引起的输出变异 。未来,随着知识图谱规模的扩展和RAG方法的优化,这一技术有望在更广泛的医疗领域中发挥作用,为罕见病患者带来更快、更精准的诊断和治疗方案 。
标签
#知识图谱 #KnowledgeGraph #大语言模型 #LLM #GraphRAG #罕见遗传病
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)