从 GDPR 到 ROI:一次评透海外影音数据抓取的合规与性价比
海外影音数据已成为数字时代的关键战略资产,其价值主要体现在三大核心领域:对于投资机构而言,通过分析平台片单动态及用户行为数据,可精准预测票房趋势与订阅增长曲线,为决策提供量化支撑;品牌方则能借助竞品广告投放监测和爆款内容特征挖掘,优化自身营销策略;而在内容出海场景中,从选品评估、语言翻译到文化适配的全链路数据洞察,能显著降低市场进入风险。然而,数据价值释放面临四大挑战:技术层面需应对反爬机制升级(
前言
海外影音数据已成为数字时代的关键战略资产,其价值主要体现在三大核心领域:对于投资机构而言,通过分析平台片单动态及用户行为数据,可精准预测票房趋势与订阅增长曲线,为决策提供量化支撑;品牌方则能借助竞品广告投放监测和爆款内容特征挖掘,优化自身营销策略;而在内容出海场景中,从选品评估、语言翻译到文化适配的全链路数据洞察,能显著降低市场进入风险。
然而,数据价值释放面临四大挑战:技术层面需应对反爬机制升级(如TLS指纹识别、行为特征检测和突发性访问限速);合规领域需严格遵循GDPR六大法律基础及CCPA/CPRA等数据出售定义;数据质量方面,官方API常存在字段缺失(如播放量统计)和更新滞后问题;此外,隐性成本(包括代理服务费、验证码破解、账号维护及法务公关支出)进一步增加了实施复杂度。这些因素共同构成了从数据采集到商业转化的完整决策链路中的关键屏障。
克服这些困难的方案有很多,本文将以爬取YouTube的数据为例,详细对比最热门的三个解决方案。
方案一:自建爬虫 + 商业代理池
构建YouTube数据爬取系统需综合动态反爬对抗、分布式架构设计及合规性管理,以下是分阶段实施方案:
一、技术架构设计
整个系统由四个核心模块组成:
- 商业代理池管理模块
- YouTube 爬虫核心模块
- 数据存储与处理模块
- 任务调度与监控模块
二、商业代理池实现
选择支持高匿、多地区、稳定的商业代理服务,并构建代理池管理系统:
import requests
from collections import deque
import time
import random
class ProxyPool:
def __init__(self, api_endpoint, auth, country_codes=None):
self.api_endpoint = api_endpoint
self.auth = auth
self.country_codes = country_codes or ['us', 'uk', 'ca']
self.pool = deque()
self.valid_proxies = deque()
self.refresh_interval = 300 # 5分钟刷新一次
self.last_refresh = 0
def refresh_proxies(self):
"""从商业代理API获取新代理"""
if time.time() - self.last_refresh < self.refresh_interval:
return
try:
params = {'countries': ','.join(self.country_codes), 'limit': 50}
response = requests.get(
self.api_endpoint,
params=params,
auth=self.auth,
timeout=10
)
if response.status_code == 200:
proxies = response.json()
self.pool.clear()
for proxy in proxies:
proxy_url = f"http://{proxy['ip']}:{proxy['port']}"
self.pool.append(proxy_url)
self.last_refresh = time.time()
print(f"刷新代理池,获取{len(proxies)}个代理")
except Exception as e:
print(f"刷新代理池失败: {str(e)}")
def get_proxy(self):
"""获取一个可用代理"""
self.refresh_proxies()
# 先检查可用代理队列
while self.valid_proxies:
proxy = self.valid_proxies.popleft()
if self.check_proxy(proxy):
self.valid_proxies.append(proxy) # 放回队列
return proxy
# 检查主代理池
while self.pool:
proxy = self.pool.popleft()
if self.check_proxy(proxy):
self.valid_proxies.append(proxy)
return proxy
return None
def check_proxy(self, proxy):
"""验证代理是否有效"""
try:
proxies = {'http': proxy, 'https': proxy}
response = requests.get(
'https://www.youtube.com/',
proxies=proxies,
timeout=10
)
return response.status_code == 200
except:
return False
def release_proxy(self, proxy, is_valid=True):
"""释放代理回池"""
if is_valid and proxy not in self.valid_proxies:
self.valid_proxies.append(proxy)
三、YouTube 爬虫实现
使用 Selenium 结合代理池进行数据爬取,处理 JavaScript 渲染内容:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, WebDriverException
import time
import random
class YouTubeCrawler:
def __init__(self, proxy_pool):
self.proxy_pool = proxy_pool
self.chrome_options = self._setup_chrome_options()
self.driver = None
self.current_proxy = None
def _setup_chrome_options(self):
"""配置Chrome浏览器选项"""
options = Options()
options.add_argument("--headless=new") # 无头模式
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
return options
def _init_driver(self):
"""初始化WebDriver,使用随机代理"""
# 如果已有driver,先关闭
if self.driver:
self.close_driver()
# 获取代理
self.current_proxy = self.proxy_pool.get_proxy()
if not self.current_proxy:
raise Exception("没有可用代理")
# 设置代理
proxy_addr = self.current_proxy.split('://')[1]
self.chrome_options.add_argument(f'--proxy-server={self.current_proxy}')
# 初始化driver
self.driver = webdriver.Chrome(options=self.chrome_options)
self.driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
# 设置随机窗口大小
self.driver.set_window_size(
random.randint(1024, 1280),
random.randint(768, 900)
)
return self.driver
def close_driver(self):
"""关闭WebDriver"""
if self.driver:
try:
self.driver.quit()
except:
pass
self.driver = None
# 清除代理设置
if '--proxy-server' in self.chrome_options.arguments:
self.chrome_options.arguments.remove(f'--proxy-server={self.current_proxy}')
def search_videos(self, query, max_results=50):
"""搜索视频并获取结果"""
videos = []
success = False
try:
driver = self._init_driver()
# 访问YouTube搜索页面
search_url = f"https://www.youtube.com/results?search_query={query}"
driver.get(search_url)
time.sleep(random.uniform(2, 4))
# 滚动加载更多内容
last_height = driver.execute_script("return document.documentElement.scrollHeight")
results_count = 0
while results_count < max_results:
# 提取视频信息
video_elements = driver.find_elements(By.CSS_SELECTOR, 'ytd-video-renderer')
for elem in video_elements[results_count:]:
try:
title = elem.find_element(By.CSS_SELECTOR, 'a#video-title').text
link = elem.find_element(By.CSS_SELECTOR, 'a#video-title').get_attribute('href')
views = elem.find_element(By.CSS_SELECTOR, '.style-scope ytd-video-meta-block').text
videos.append({
'title': title,
'link': link,
'views': views,
'search_query': query,
'timestamp': time.time()
})
results_count += 1
if results_count >= max_results:
break
except:
continue
# 滚动到页面底部
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
time.sleep(random.uniform(1, 3))
# 检查是否到达页面底部
new_height = driver.execute_script("return document.documentElement.scrollHeight")
if new_height == last_height:
break # 没有更多内容
last_height = new_height
success = True
print(f"成功获取 {len(videos)} 个视频信息")
except Exception as e:
print(f"搜索视频失败: {str(e)}")
finally:
# 释放代理(标记是否有效)
if self.current_proxy:
self.proxy_pool.release_proxy(self.current_proxy, success)
self.close_driver()
return videos
def get_video_details(self, video_url):
"""获取单个视频的详细信息"""
details = None
success = False
try:
driver = self._init_driver()
driver.get(video_url)
time.sleep(random.uniform(3, 5))
# 等待页面加载完成
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'h1.title yt-formatted-string'))
)
# 提取视频详情
title = driver.find_element(By.CSS_SELECTOR, 'h1.title yt-formatted-string').text
views = driver.find_element(By.CSS_SELECTOR, '.view-count').text
publish_date = driver.find_element(By.CSS_SELECTOR, '.date').text
likes = driver.find_element(By.CSS_SELECTOR, '.like-button-renderer-like-button').text
details = {
'url': video_url,
'title': title,
'views': views,
'publish_date': publish_date,
'likes': likes,
'scraped_at': time.time()
}
success = True
except TimeoutException:
print(f"超时: 无法加载视频 {video_url}")
except Exception as e:
print(f"获取视频详情失败: {str(e)}")
finally:
if self.current_proxy:
self.proxy_pool.release_proxy(self.current_proxy, success)
self.close_driver()
return details
四、数据存储与处理
使用 MongoDB 存储爬取的数据,便于后续分析:
from pymongo import MongoClient
from pymongo.errors import DuplicateKeyError
class DataStorage:
def __init__(self, db_name='youtube_scraper'):
self.client = MongoClient('mongodb://localhost:27017/')
self.db = self.client[db_name]
self.videos_collection = self.db['videos']
self.search_results_collection = self.db['search_results']
# 创建索引
self.videos_collection.create_index('url', unique=True)
self.search_results_collection.create_index('link', unique=True)
def save_search_results(self, results):
"""保存搜索结果"""
if not results:
return 0
saved = 0
for result in results:
try:
self.search_results_collection.insert_one(result)
saved += 1
except DuplicateKeyError:
# 已存在,更新记录
self.search_results_collection.update_one(
{'link': result['link']},
{'$set': result}
)
return saved
def save_video_details(self, details):
"""保存视频详情"""
if not details:
return False
try:
self.videos_collection.insert_one(details)
return True
except DuplicateKeyError:
# 已存在,更新记录
self.videos_collection.update_one(
{'url': details['url']},
{'$set': details}
)
return True
except Exception as e:
print(f"保存视频详情失败: {str(e)}")
return False
五、任务调度与监控
使用 Celery 进行任务调度,实现分布式爬取:
# tasks.py
from celery import Celery
from celery.utils.log import get_task_logger
from your_proxy_pool_module import ProxyPool
from your_crawler_module import YouTubeCrawler
from your_storage_module import DataStorage
# 初始化Celery
app = Celery('youtube_tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
logger = get_task_logger(__name__)
# 初始化组件
proxy_pool = ProxyPool(
api_endpoint='https://api.business-proxy.com/proxies',
auth=('your_username', 'your_password'),
country_codes=['us', 'uk', 'ca', 'de']
)
crawler = YouTubeCrawler(proxy_pool)
storage = DataStorage()
@app.task(bind=True, max_retries=3)
def search_youtube(self, query, max_results=50):
"""搜索YouTube任务"""
try:
logger.info(f"开始搜索: {query}")
results = crawler.search_videos(query, max_results)
saved = storage.save_search_results(results)
logger.info(f"搜索完成: {query}, 保存了 {saved} 条结果")
# 为每个视频创建获取详情的任务
for result in results:
get_video_details.delay(result['link'])
return {
'query': query,
'results_count': len(results),
'saved_count': saved
}
except Exception as e:
logger.error(f"搜索任务失败: {str(e)}")
self.retry(exc=e, countdown=60)
@app.task(bind=True, max_retries=3)
def get_video_details(self, video_url):
"""获取视频详情任务"""
try:
logger.info(f"获取视频详情: {video_url}")
details = crawler.get_video_details(video_url)
if details:
success = storage.save_video_details(details)
logger.info(f"视频详情保存: {success}")
return {'url': video_url, 'success': success}
return {'url': video_url, 'success': False}
except Exception as e:
logger.error(f"获取视频详情失败: {str(e)}")
self.retry(exc=e, countdown=60)
六、反爬策略应对
- 代理轮换:使用商业代理池,每次请求使用不同代理
- 请求间隔:随机设置请求间隔,模拟人类行为
- 浏览器指纹伪装:修改 User-Agent、禁用自动化特征
- IP 轮换:结合代理池实现 IP 动态切换
- 验证码处理:集成第三方验证码识别服务(如 2Captcha)
- 行为模拟:随机滚动、点击等操作,避免机械行为
七、合规性与风险提示
- 遵守 YouTube 服务条款:YouTube 禁止未经授权的爬虫,可能导致账号封禁
- 数据使用合规:确保爬取的数据符合相关法律法规(如 GDPR)
- 频率限制:控制爬取频率,避免给服务器造成负担
- 商业代理合规:使用合法的商业代理服务,遵守其使用条款
八、部署与扩展
- 容器化部署:使用 Docker 封装各组件,便于扩展
- 分布式爬取:通过 Celery 实现多节点协同工作
- 监控告警:使用 Prometheus+Grafana 监控系统状态
- 自动扩容:根据任务量自动调整爬虫节点数量
这个解决方案提供了一个完整的 YouTube 爬虫系统框架,可以根据实际需求进行调整和优化,特别是在反爬策略和代理管理方面需要持续迭代以应对网站的反爬措施升级。
方案二:官方 API
一、前期准备
- 创建 Google Cloud 项目
- 访问Google Cloud Console
- 创建新项目并启用 “YouTube Data API v3”
- 创建 API 密钥(用于身份验证)
- 了解 API 限制与配额
- 免费配额:每天 10,000 个单位(不同操作消耗不同单位)
- 搜索操作:100 单位 / 次
- 视频列表:1 单位 / 次
- 频道列表:1 单位 / 次
二、核心实现方案
下面是基于 Python 的完整实现,包含主要功能模块:
import os
import json
import pandas as pd
from datetime import datetime
from pymongo import MongoClient
from pymongo.errors import DuplicateKeyError
class DataManager:
def __init__(self, storage_type='csv', db_name='youtube_data'):
"""
初始化数据管理器
:param storage_type: 存储类型 ('csv', 'json', 'mongodb')
:param db_name: 数据库名称(仅用于MongoDB)
"""
self.storage_type = storage_type
self.data_dir = 'youtube_data'
# 创建数据目录
if not os.path.exists(self.data_dir):
os.makedirs(self.data_dir)
# 初始化数据库连接(如果使用MongoDB)
if storage_type == 'mongodb':
self.client = MongoClient('mongodb://localhost:27017/')
self.db = self.client[db_name]
# 创建集合和索引
self.videos_collection = self.db['videos']
self.channels_collection = self.db['channels']
self.comments_collection = self.db['comments']
self.searches_collection = self.db['searches']
# 创建唯一索引
self.videos_collection.create_index('video_id', unique=True)
self.channels_collection.create_index('channel_id', unique=True)
self.comments_collection.create_index('comment_id', unique=True)
def save_search_results(self, results, query):
"""保存搜索结果"""
if not results:
return 0
timestamp = datetime.now().isoformat()
saved_count = 0
# 为每条结果添加时间戳
for item in results:
item['searched_at'] = timestamp
if self.storage_type == 'csv':
filename = f"{self.data_dir}/search_results_{query.replace(' ', '_')}_{timestamp[:10]}.csv"
df = pd.DataFrame(results)
df.to_csv(filename, index=False, mode='a', header=not os.path.exists(filename))
saved_count = len(results)
elif self.storage_type == 'json':
filename = f"{self.data_dir}/search_results_{query.replace(' ', '_')}.json"
# 读取已有数据
existing_data = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
# 添加新数据(去重)
existing_ids = {item['video_id'] for item in existing_data}
new_items = [item for item in results if item['video_id'] not in existing_ids]
existing_data.extend(new_items)
# 保存数据
with open(filename, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2)
saved_count = len(new_items)
elif self.storage_type == 'mongodb':
# 先保存搜索记录
self.searches_collection.insert_one({
'query': query,
'timestamp': timestamp,
'results_count': len(results)
})
# 保存视频搜索结果
for item in results:
try:
self.videos_collection.insert_one(item)
saved_count += 1
except DuplicateKeyError:
# 已存在则更新
self.videos_collection.update_one(
{'video_id': item['video_id']},
{'$set': item}
)
return saved_count
def save_video_details(self, details):
"""保存视频详情"""
if not details:
return 0
saved_count = 0
if self.storage_type == 'csv':
filename = f"{self.data_dir}/video_details.csv"
df = pd.DataFrame(details)
df.to_csv(filename, index=False, mode='a', header=not os.path.exists(filename))
saved_count = len(details)
elif self.storage_type == 'json':
filename = f"{self.data_dir}/video_details.json"
existing_data = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
existing_ids = {item['video_id'] for item in existing_data}
new_items = [item for item in details if item['video_id'] not in existing_ids]
existing_data.extend(new_items)
with open(filename, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2)
saved_count = len(new_items)
elif self.storage_type == 'mongodb':
for item in details:
try:
self.videos_collection.insert_one(item)
saved_count += 1
except DuplicateKeyError:
self.videos_collection.update_one(
{'video_id': item['video_id']},
{'$set': item}
)
return saved_count
def save_channel_details(self, details):
"""保存频道详情"""
if not details:
return 0
saved_count = 0
if self.storage_type == 'csv':
filename = f"{self.data_dir}/channel_details.csv"
df = pd.DataFrame(details)
df.to_csv(filename, index=False, mode='a', header=not os.path.exists(filename))
saved_count = len(details)
elif self.storage_type == 'json':
filename = f"{self.data_dir}/channel_details.json"
existing_data = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
existing_ids = {item['channel_id'] for item in existing_data}
new_items = [item for item in details if item['channel_id'] not in existing_ids]
existing_data.extend(new_items)
with open(filename, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2)
saved_count = len(new_items)
elif self.storage_type == 'mongodb':
for item in details:
try:
self.channels_collection.insert_one(item)
saved_count += 1
except DuplicateKeyError:
self.channels_collection.update_one(
{'channel_id': item['channel_id']},
{'$set': item}
)
return saved_count
def save_comments(self, comments):
"""保存评论"""
if not comments:
return 0
saved_count = 0
if self.storage_type == 'csv':
# 为每个视频创建单独的评论文件
video_id = comments[0]['video_id'] if comments else ''
filename = f"{self.data_dir}/comments_{video_id}.csv"
df = pd.DataFrame(comments)
df.to_csv(filename, index=False, mode='a', header=not os.path.exists(filename))
saved_count = len(comments)
elif self.storage_type == 'json':
video_id = comments[0]['video_id'] if comments else ''
filename = f"{self.data_dir}/comments_{video_id}.json"
existing_data = []
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
existing_ids = {item['comment_id'] for item in existing_data}
new_items = [item for item in comments if item['comment_id'] not in existing_ids]
existing_data.extend(new_items)
with open(filename, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2)
saved_count = len(new_items)
elif self.storage_type == 'mongodb':
for item in comments:
try:
self.comments_collection.insert_one(item)
saved_count += 1
except DuplicateKeyError:
# 评论一般不更新,所以这里可以忽略
pass
return saved_count
import os
import json
import time
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
import pandas as pd
class YouTubeAPIClient:
def __init__(self, api_key, max_retries=3):
"""初始化YouTube API客户端"""
self.api_key = api_key
self.max_retries = max_retries
self.youtube = build('youtube', 'v3', developerKey=api_key)
self.quota_used = 0 # 跟踪已使用的配额单位
def _retry_request(self, func, *args, **kwargs):
"""带重试机制的API请求"""
for attempt in range(self.max_retries):
try:
return func(*args, **kwargs).execute()
except HttpError as e:
# 处理常见错误
error_code = e.resp.status
if error_code == 403:
print("API配额已用尽或权限不足")
return None
elif error_code == 429:
# 达到请求频率限制,等待后重试
sleep_time = (2 **attempt) * 10 # 指数退避
print(f"请求过于频繁,将在{sleep_time}秒后重试...")
time.sleep(sleep_time)
elif error_code == 500 or error_code == 503:
# 服务器错误,短暂等待后重试
time.sleep(5)
else:
print(f"HTTP错误 {error_code}: {str(e)}")
return None
except Exception as e:
print(f"请求错误: {str(e)}")
return None
print(f"达到最大重试次数({self.max_retries})")
return None
def search_videos(self, query, max_results=50, order='relevance', region_code='US'):
"""
搜索视频
:param query: 搜索关键词
:param max_results: 最大结果数(最多50)
:param order: 排序方式(date, rating, relevance, title, videoCount, viewCount)
:param region_code: 地区代码
:return: 视频列表
"""
videos = []
next_page_token = None
# 每次搜索请求消耗100个单位配额
self.quota_used += 100
while len(videos) < max_results:
# 计算本次请求的结果数量
remaining = max_results - len(videos)
request_count = min(remaining, 50) # API每次最多返回50条结果
# 构建搜索请求
search_request = self.youtube.search().list(
q=query,
part='id,snippet',
type='video',
order=order,
regionCode=region_code,
maxResults=request_count,
pageToken=next_page_token
)
# 执行请求
response = self._retry_request(search_request.execute)
if not response:
break
# 处理响应结果
for item in response.get('items', []):
video_id = item['id']['videoId']
snippet = item['snippet']
videos.append({
'video_id': video_id,
'title': snippet['title'],
'description': snippet['description'],
'channel_id': snippet['channelId'],
'channel_title': snippet['channelTitle'],
'published_at': snippet['publishedAt'],
'thumbnail_url': snippet['thumbnails']['high']['url'],
'search_query': query
})
# 检查是否有下一页
next_page_token = response.get('nextPageToken')
if not next_page_token:
break
# 避免请求过于频繁
time.sleep(1)
return videos
def get_video_details(self, video_ids):
"""
获取视频详细信息
:param video_ids: 视频ID列表(最多50个)
:return: 视频详细信息列表
"""
if not video_ids:
return []
# 每次视频详情请求消耗1个单位配额
self.quota_used += 1
# API限制每次最多请求50个视频
all_details = []
batch_size = 50
for i in range(0, len(video_ids), batch_size):
batch_ids = video_ids[i:i+batch_size]
# 构建视频详情请求
details_request = self.youtube.videos().list(
id=','.join(batch_ids),
part='statistics,snippet,contentDetails'
)
# 执行请求
response = self._retry_request(details_request.execute)
if not response:
continue
# 处理响应结果
for item in response.get('items', []):
stats = item.get('statistics', {})
content_details = item.get('contentDetails', {})
snippet = item.get('snippet', {})
all_details.append({
'video_id': item['id'],
'title': snippet.get('title'),
'description': snippet.get('description'),
'channel_id': snippet.get('channelId'),
'channel_title': snippet.get('channelTitle'),
'published_at': snippet.get('publishedAt'),
'duration': content_details.get('duration'),
'view_count': stats.get('viewCount'),
'like_count': stats.get('likeCount'),
'comment_count': stats.get('commentCount'),
'favorite_count': stats.get('favoriteCount'),
'category_id': snippet.get('categoryId')
})
# 避免请求过于频繁
time.sleep(1)
return all_details
def get_channel_details(self, channel_ids):
"""
获取频道详细信息
:param channel_ids: 频道ID列表(最多50个)
:return: 频道详细信息列表
"""
if not channel_ids:
return []
# 每次频道详情请求消耗1个单位配额
self.quota_used += 1
# API限制每次最多请求50个频道
all_details = []
batch_size = 50
for i in range(0, len(channel_ids), batch_size):
batch_ids = channel_ids[i:i+batch_size]
# 构建频道详情请求
channels_request = self.youtube.channels().list(
id=','.join(batch_ids),
part='statistics,snippet,contentDetails'
)
# 执行请求
response = self._retry_request(channels_request.execute)
if not response:
continue
# 处理响应结果
for item in response.get('items', []):
stats = item.get('statistics', {})
snippet = item.get('snippet', {})
content_details = item.get('contentDetails', {})
all_details.append({
'channel_id': item['id'],
'title': snippet.get('title'),
'description': snippet.get('description'),
'published_at': snippet.get('publishedAt'),
'view_count': stats.get('viewCount'),
'subscriber_count': stats.get('subscriberCount'),
'video_count': stats.get('videoCount'),
'country': snippet.get('country'),
'thumbnail_url': snippet.get('thumbnails', {}).get('high', {}).get('url')
})
# 避免请求过于频繁
time.sleep(1)
return all_details
def get_video_comments(self, video_id, max_comments=100):
"""
获取视频评论
:param video_id: 视频ID
:param max_comments: 最大评论数
:return: 评论列表
"""
comments = []
next_page_token = None
# 每次评论请求消耗1个单位配额
self.quota_used += 1
while len(comments) < max_comments:
# 构建评论请求
comments_request = self.youtube.commentThreads().list(
videoId=video_id,
part='snippet',
maxResults=min(100, max_comments - len(comments)),
pageToken=next_page_token,
order='relevance'
)
# 执行请求
response = self._retry_request(comments_request.execute)
if not response:
break
# 处理响应结果
for item in response.get('items', []):
comment = item['snippet']['topLevelComment']['snippet']
comments.append({
'comment_id': item['id'],
'video_id': video_id,
'author_name': comment['authorDisplayName'],
'text': comment['textDisplay'],
'published_at': comment['publishedAt'],
'updated_at': comment['updatedAt'],
'like_count': comment['likeCount']
})
# 检查是否有下一页
next_page_token = response.get('nextPageToken')
if not next_page_token:
break
# 避免请求过于频繁
time.sleep(1)
return comments
import os
import argparse
from youtube_api_client import YouTubeAPIClient
from data_manager import DataManager
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description='YouTube Data API 爬取工具')
parser.add_argument('--api-key', required=True, help='YouTube Data API v3 密钥')
parser.add_argument('--query', help='搜索关键词')
parser.add_argument('--video-id', help='单个视频ID')
parser.add_argument('--channel-id', help='单个频道ID')
parser.add_argument('--max-results', type=int, default=50, help='最大结果数')
parser.add_argument('--storage', choices=['csv', 'json', 'mongodb'], default='csv',
help='数据存储方式')
parser.add_argument('--get-comments', action='store_true', help='是否获取评论')
args = parser.parse_args()
# 初始化API客户端和数据管理器
api_client = YouTubeAPIClient(args.api_key)
data_manager = DataManager(storage_type=args.storage)
try:
# 搜索视频模式
if args.query:
print(f"正在搜索视频: {args.query},最多{args.max_results}条结果")
search_results = api_client.search_videos(
query=args.query,
max_results=args.max_results
)
if search_results:
saved = data_manager.save_search_results(search_results, args.query)
print(f"搜索完成,保存了{saved}条新结果")
# 提取视频ID并获取详细信息
video_ids = [item['video_id'] for item in search_results]
print(f"正在获取{len(video_ids)}个视频的详细信息")
video_details = api_client.get_video_details(video_ids)
if video_details:
saved_details = data_manager.save_video_details(video_details)
print(f"保存了{saved_details}条视频详细信息")
# 提取频道ID并获取详细信息
channel_ids = list({item['channel_id'] for item in search_results})
print(f"正在获取{len(channel_ids)}个频道的详细信息")
channel_details = api_client.get_channel_details(channel_ids)
if channel_details:
saved_channels = data_manager.save_channel_details(channel_details)
print(f"保存了{saved_channels}条频道详细信息")
# 如果需要,获取评论
if args.get_comments:
for video_id in video_ids[:5]: # 限制获取前5个视频的评论
print(f"正在获取视频 {video_id} 的评论")
comments = api_client.get_video_comments(video_id)
if comments:
saved_comments = data_manager.save_comments(comments)
print(f"保存了{saved_comments}条评论")
# 单个视频模式
elif args.video_id:
print(f"正在获取视频 {args.video_id} 的详细信息")
video_details = api_client.get_video_details([args.video_id])
if video_details:
saved_details = data_manager.save_video_details(video_details)
print(f"保存了{saved_details}条视频详细信息")
# 获取频道信息
channel_id = video_details[0]['channel_id']
print(f"正在获取频道 {channel_id} 的详细信息")
channel_details = api_client.get_channel_details([channel_id])
if channel_details:
saved_channels = data_manager.save_channel_details(channel_details)
print(f"保存了{saved_channels}条频道详细信息")
# 如果需要,获取评论
if args.get_comments:
print(f"正在获取视频 {args.video_id} 的评论")
comments = api_client.get_video_comments(args.video_id, args.max_results)
if comments:
saved_comments = data_manager.save_comments(comments)
print(f"保存了{saved_comments}条评论")
# 单个频道模式
elif args.channel_id:
print(f"正在获取频道 {args.channel_id} 的详细信息")
channel_details = api_client.get_channel_details([args.channel_id])
if channel_details:
saved_channels = data_manager.save_channel_details(channel_details)
print(f"保存了{saved_channels}条频道详细信息")
else:
print("请指定搜索关键词、视频ID或频道ID")
parser.print_help()
print(f"本次操作共使用 {api_client.quota_used} 个API配额单位")
except Exception as e:
print(f"发生错误: {str(e)}")
if __name__ == "__main__":
main()
三、使用方法
1.安装依赖
pip install google-api-python-client pandas pymongo
- 基本使用示例
- 搜索视频并保存结果:
python youtube_scraper.py --api-key "你的API密钥" --query "人工智能" --max-results 100 --storage mongodb
- 获取单个视频详情及评论:
python youtube_scraper.py --api-key "你的API密钥" --video-id "视频ID" --get-comments --max-results 200
- 获取单个频道详情:
python youtube_scraper.py --api-key "你的API密钥" --channel-id "频道ID"
四、功能扩展建议
1.批量任务处理 - 实现从文件读取多个搜索关键词
- 添加任务队列,实现异步处理
2.配额管理 - 实现配额监控,避免超出每日限制 - 自动在配额用尽时暂停并等待重置
3.数据分析功能 - 添加数据统计和可视化模块 - 实现热门视频分析、频道增长趋势等功能
4.定时任务 - 结合调度工具(如 cron)实现定期数据爬取 - 跟踪特定关键词或频道的变化
五、合规性注意事项
1.API 使用条款 - 遵守 YouTube Data API 的服务条款
- 数据使用需注明来源为 YouTube
2.配额限制 - 合理规划请求,避免触发配额限制 - 商业用途应考虑升级到付费配额
3.数据隐私 - 尊重用户隐私,不滥用爬取的评论等个人信息 - 遵守相关地区的数据保护法规(如 GDPR)
方案三:亮数据
一、注册亮数据账号
进入官网,点击免费试用。
填写信息注册
二、YouTube爬取API
侧边栏点击Web Scrapers,然后选择Web爬虫库
输入YouTube
根据自己的业务需要选择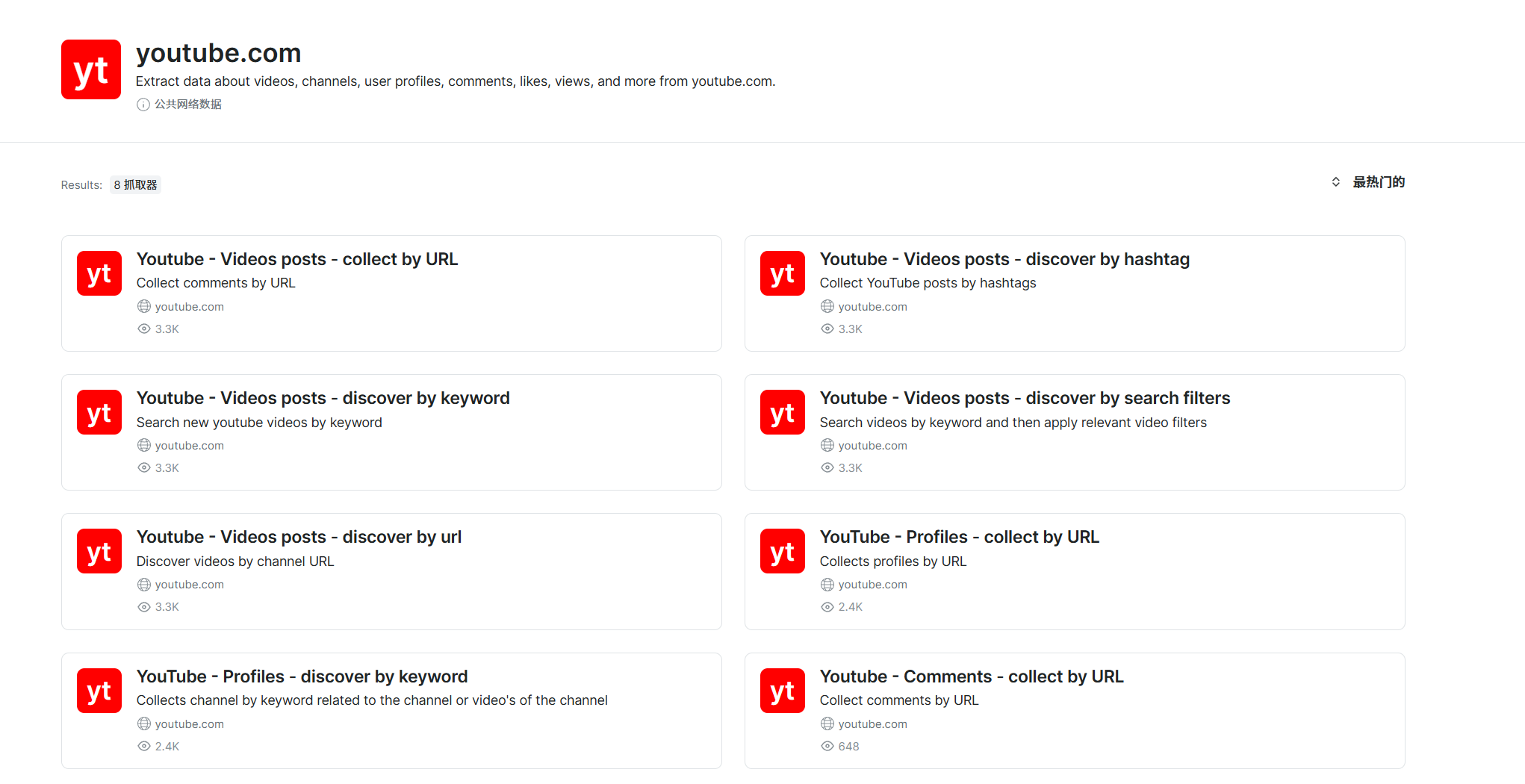
选择后有两个服务,一个是基于爬虫API,可以在我们的程序中直接调用;另一个是无代码抓取,可以直接在控制面板获取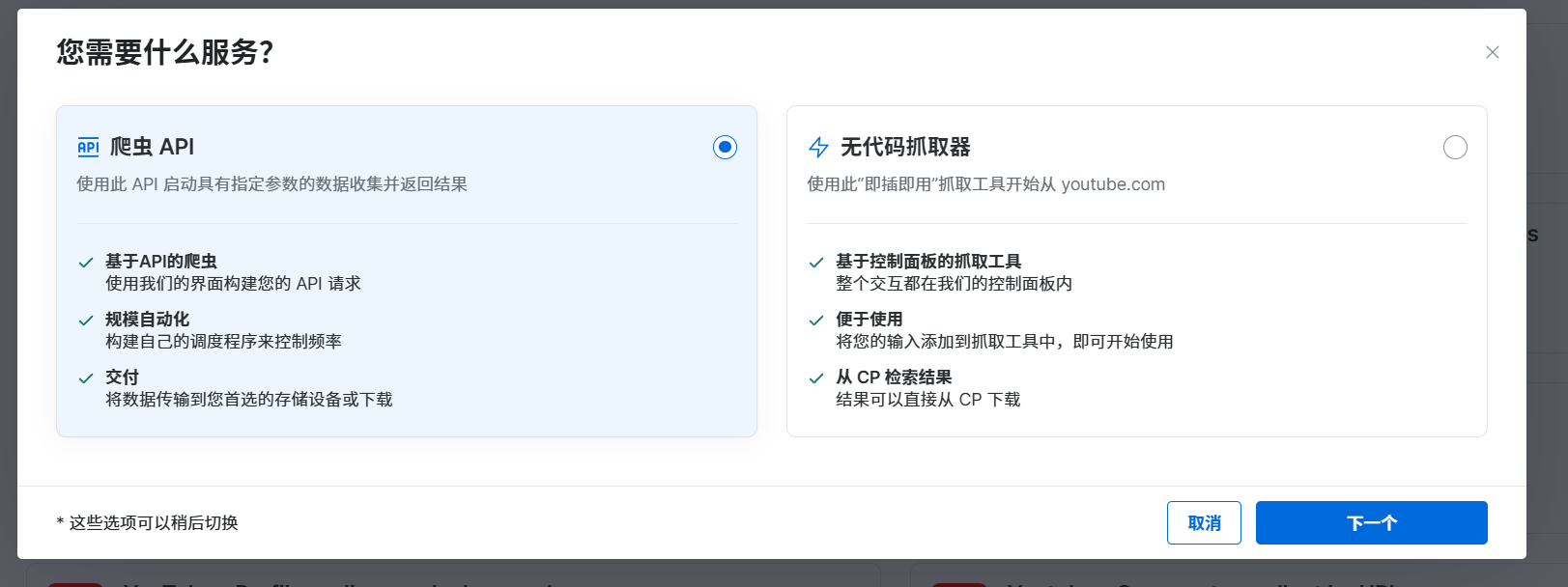
三、YouTube数据集
点击Web Datasets,然后选择数据集市场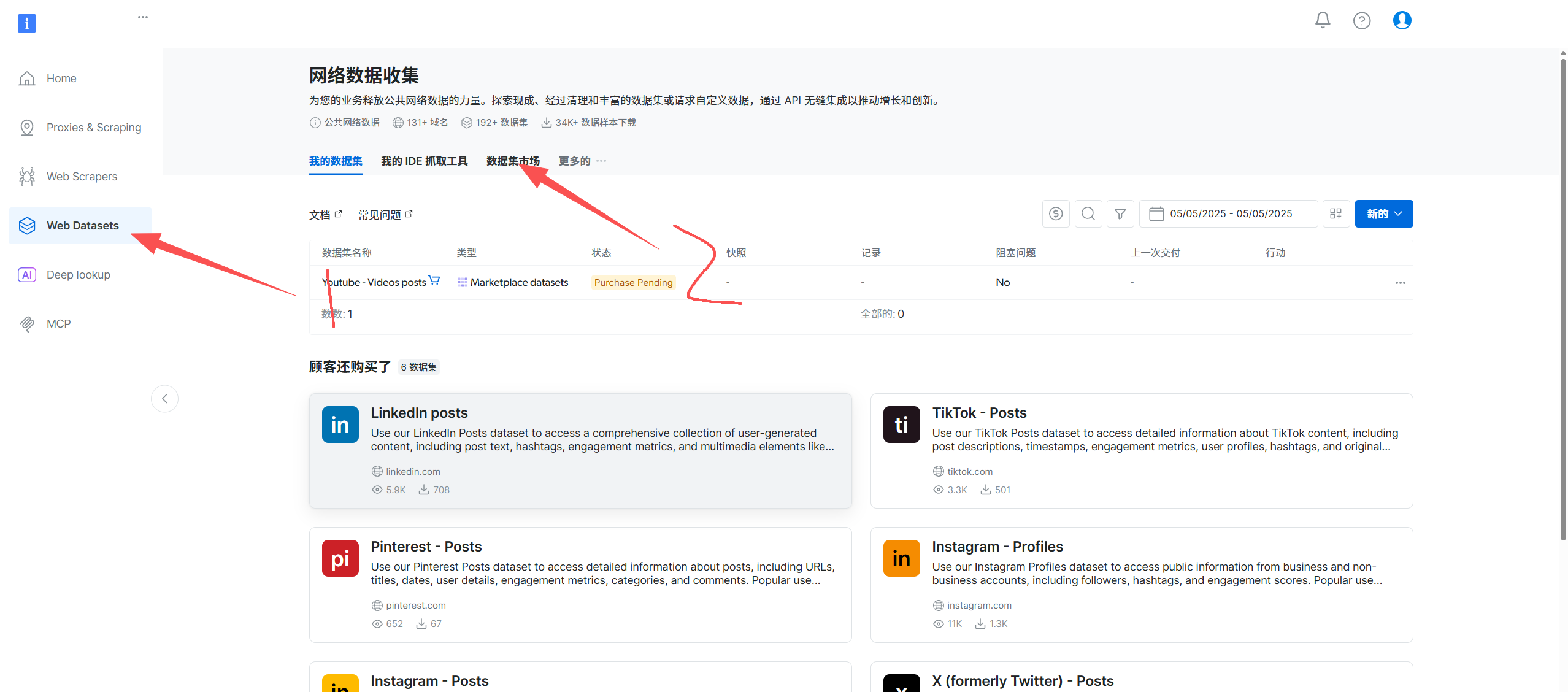
输入YouTube,选择想要的数据集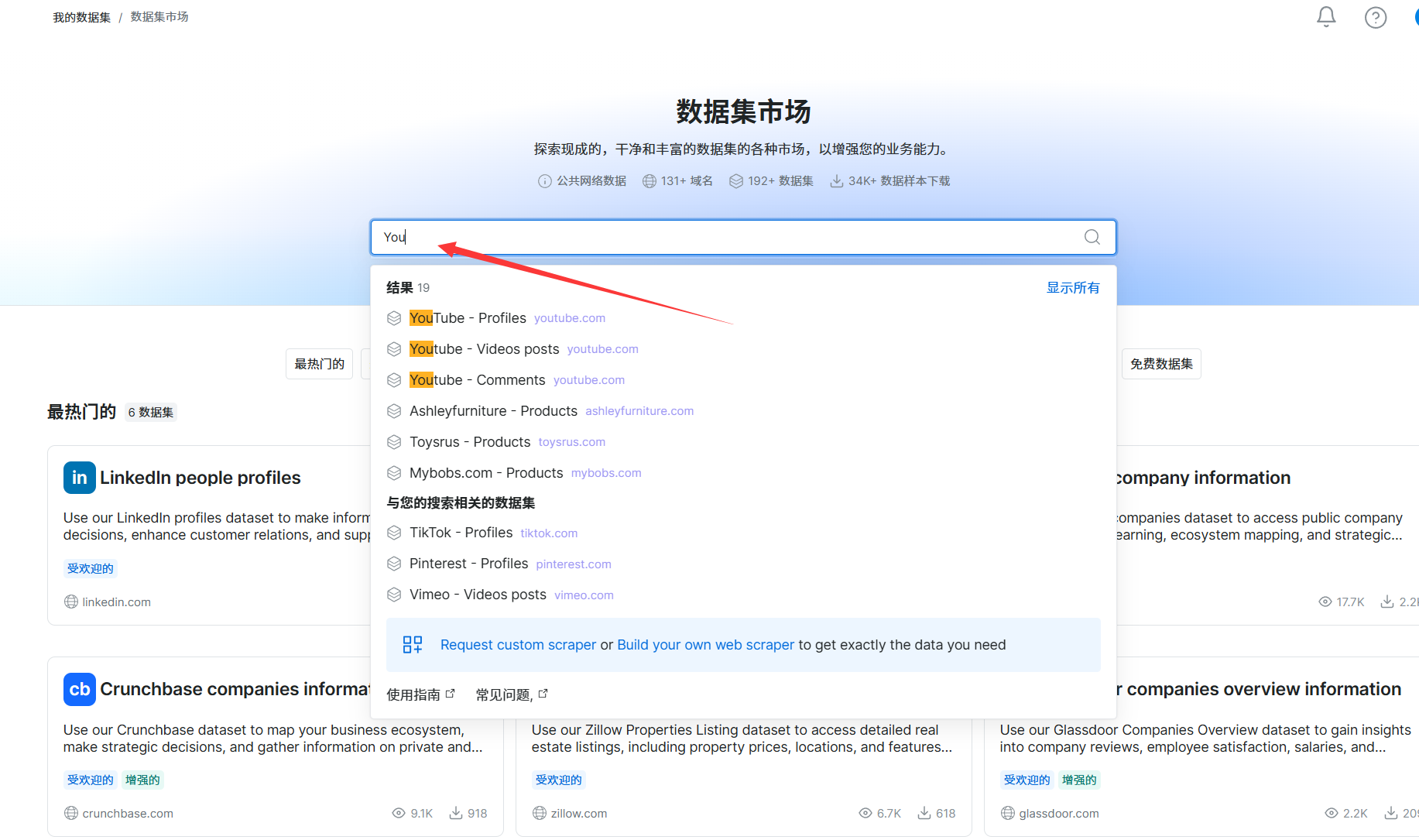
可以设置过滤器,选择自己想要的数据直接下载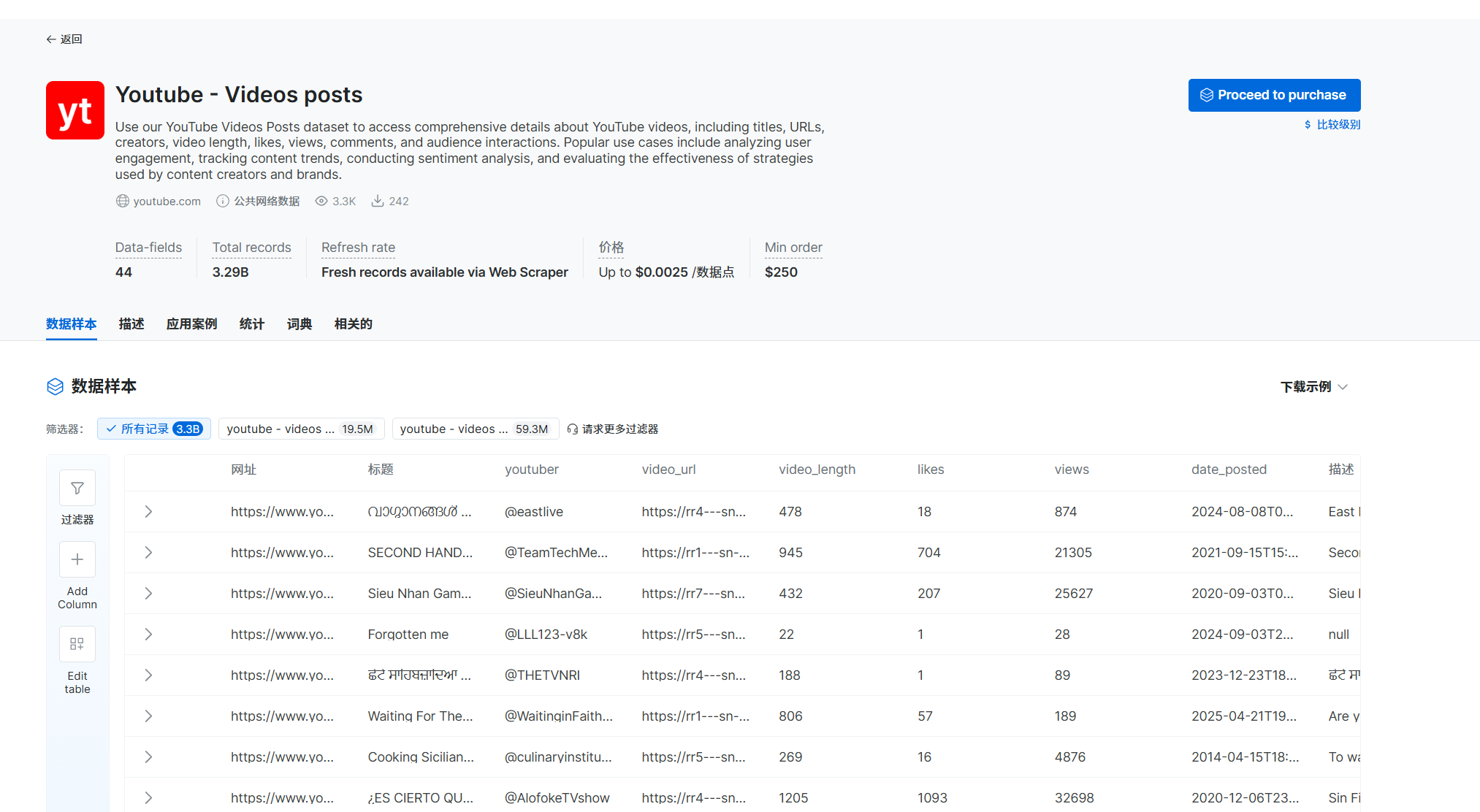
综合对比
| 对比维度 | 自建爬虫 + 商业代理池 | YouTube Data API v3 | 亮数据解决方案 |
|---|---|---|---|
| GDPR 合规性 | ❌ 高风险。可能违反 YouTube 使用条款,涉及用户数据需自行处理合规问题。 | ✅ 合规性高。官方接口,有明确数据使用规范,用户隐私保障较好。 | ✅ 合规性高。承诺遵守 GDPR/CCPA,不收集个人数据,仅索引公开匿名数据。 |
| ROI(投资回报率) | ⚠️ 初期投入高,需持续维护代理池与应对反爬,风险高,长期可能 ROI 可观但依赖技术能力。 | ✅ 成本可控,稳定性高,若需求匹配 API 功能,ROI 较好;若需求复杂,ROI 受限。 | ✅ 按需付费,降低技术门槛和运维成本,适合大规模抓取,ROI 在复杂场景下表现较好。 |
| 技术难度 | ❌ 高。需应对 IP 封锁、设备指纹、动态加载等反爬机制,维护代理池,技术门槛高。 | ✅ 中等。按官方文档调用 API,开发门槛较低,适合有基础开发者。 | ✅ 低。提供 API 和数据集,无需开发经验即可使用,技术门槛最低。 |
| 数据获取能力 | ⚠️ 理论上可获取全站数据,但受反爬限制,实际稳定性差,需持续优化策略。 | ⚠️ 仅支持 API 开放的数据类型和范围,深层数据或特定格式无法获取。 | ✅ 可获取大量公开数据(视频、评论、用户资料等),支持动态内容加载,数据获取能力强。 |
总结
综合对比下来,亮数据更加值得选择,大家如果对海外数据获取有需求可以尝试尝试。目前亮数据有活动新用户首充多少送多少,亮数据官网

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐

 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)