AI驱动测试:从辅助到自主的演进之路—— 有赞、携程、联通三大实践解析
本文整合有赞 AITest、中国联通 AI 智算网络测试平台、携程 “AI 测试员” 三大典型实践,系统梳理 AI 测试的落地路径、核心挑战、技术支撑与未来演进方向,揭示其从 “辅助工具” 向 “自主驱动” 跨越的内在逻辑。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
以下为作者观点:
随着大模型技术在自然语言理解、多模态处理领域的突破,软件测试正告别 “人工主导 + 代码辅助” 的传统模式,迈入 “AI 驱动智能测试” 的新阶段。从通用软件测试场景的效率革新,到智算网络专属领域的技术突破,再到企业级测试用例的自动化生成,AI 已成为破解测试效率低、覆盖度不足、复杂场景适配难等行业痛点的核心力量。
本文整合有赞 AITest、中国联通 AI 智算网络测试平台、携程 “AI 测试员” 三大典型实践,系统梳理 AI 测试的落地路径、核心挑战、技术支撑与未来演进方向,揭示其从 “辅助工具” 向 “自主驱动” 跨越的内在逻辑。
一、AI 测试的核心价值:效率革命与质量跃升的双重突破
AI 在测试领域的落地,本质是通过技术创新重构测试全流程,实现 “效率、质量、成本” 的三维优化。三大实践案例从不同场景出发,印证了 AI 测试的核心价值:
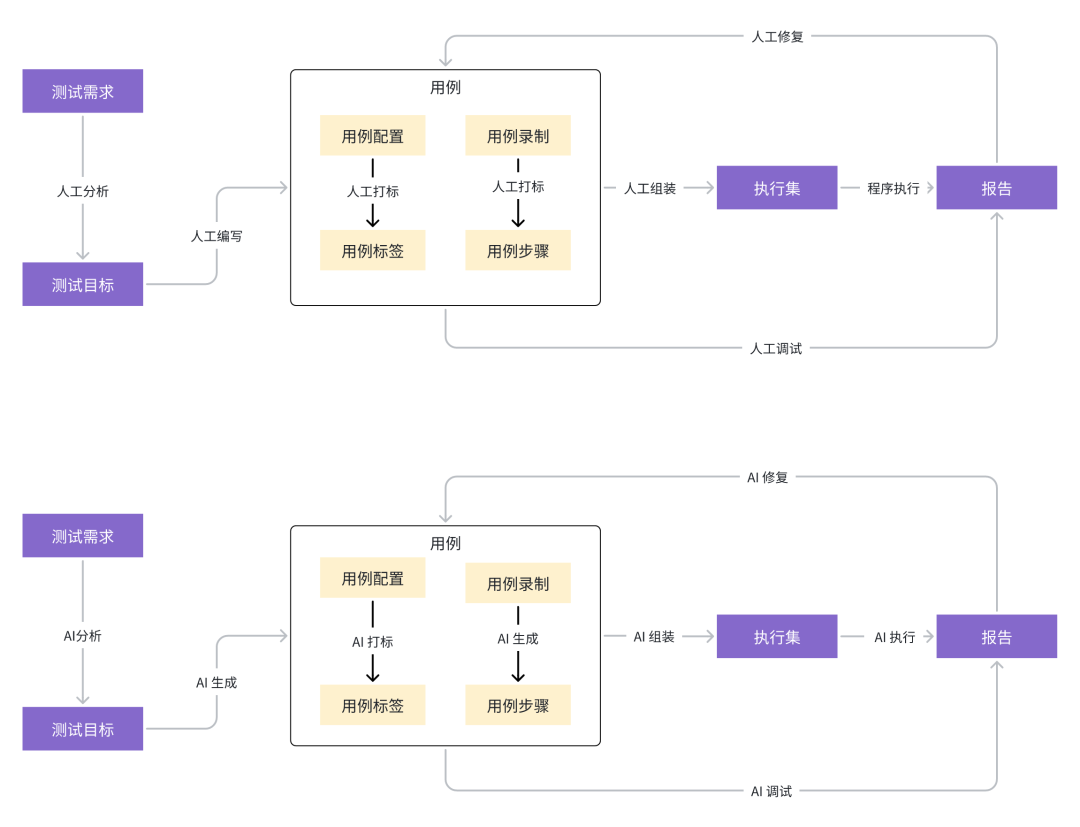
1. 通用测试场景:有赞 AITest 的 “人机协同” 范式
有赞 AITest 平台聚焦软件测试的共性痛点,推动测试从 “人 + 代码驱动” 向 “AI 智能驱动” 转型。其核心价值在于构建 “低门槛、高覆盖、强适应性” 的测试体系:对比传统 “全人工” 模式(人工编写用例、调试执行、分析报告),AI 版本通过 “需求输入→AI 分析打标→AI 生成用例→AI 组装执行集→报告自动输出” 的流程重构,仅在复杂场景保留人工干预节点,大幅减少重复性工作,同时通过 “AI 兜底异常场景” 提升测试稳定性。
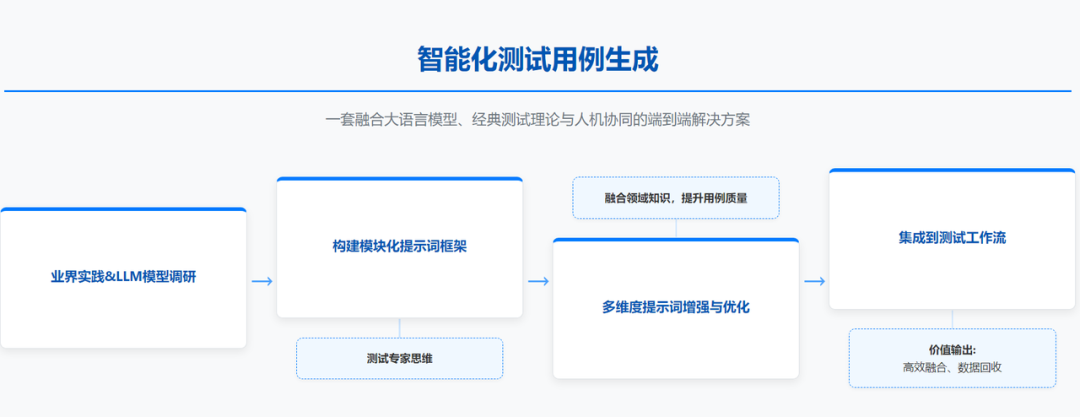
2. 企业级用例生成:携程 “AI 测试员” 的效率革命
携程针对传统测试用例 “人力密集、覆盖不足、一致性差” 的痛点,打造从 PRD(需求文档)到测试用例的一键生成系统,落地成效尤为显著:上线 2 周生成 30 + 需求、1500 + 用例,采纳率达 89.3%,覆盖率 80.6%;中小需求用例设计时间减少 70%,大需求减少 50%,不仅降低新人学习成本,更让测试人员从基础工作中解放,聚焦高价值探索性测试。
3. 垂直领域突破:联通 AI 智算网络的技术攻坚
面对智算中心 “集群规模大、网络与计算解耦难、测试难度指数级增长” 的痛点,中国联通联合信而泰打造国产 400G 智算网络测试平台。其核心价值在于攻克超大规模集群的测试效率瓶颈 —— 通过分布式测试架构、多厂商设备兼容能力,实现 “纳管 - 执行 - 分析” 全闭环,解决智算网络 “设备多、组网复杂” 的管理难题,为垂直领域 AI 测试提供定制化方案。

二、落地挑战与破局之道:从技术瓶颈到人机协同困境
AI 测试的落地并非 “一蹴而就”,三大案例均需突破模型固有局限、系统集成壁垒、人机协同信任三大核心难题,其破局思路具有行业普适性:
1. 技术瓶颈:破解 “幻觉、性能与工程化” 三重障碍
AI 模型的 “不确定性” 是落地首要障碍 —— 大型语言模型(LLM)作为概率生成模型,可能输出看似合理却错误的信息(即 “幻觉问题”),且多模态场景下响应延迟、吞吐能力不足,难以满足低延迟测试需求。同时,企业易陷入 “将 AI 等同于聊天机器人”“直接接大模型即智能化” 的工程化误区,导致 AI 测试沦为 “demo 级产品”。
破局思路:
- 模型定位 + 工程化补位:明确 LLM 核心价值为 “意图理解、模式识别、场景生成”,标准化任务(如用例执行、数据校验)仍交由传统程序处理,形成 “AI 负责模糊探索,程序保障精准执行” 的互补模式(如 AITest 的 “程序优先执行 + AI 兜底” 机制);
- 拒绝颠覆式重构,聚焦功能增强:AI 需嵌入现有测试流程(如携程将用例生成对接需求管理平台),而非推翻成熟体系;联通则通过重构仪表高层接口,兼容多厂商设备,打破 “厂商壁垒”,避免重复采购成本。
2. 人机协同:明确边界,重建信任关系
经验丰富的测试人员对确定性要求极高,AI 一次小失误就可能削弱信任;同时,“何时干预 AI”“如何修正输出” 缺乏标准,导致人机协同效率低下。有赞明确指出:“一次小失误可能摧毁资深测试人员对 AI 的信任”,这一困境在三大案例中均有体现。
破局思路:
- 差异化协同策略:简单任务(基础用例生成、日志初筛)由 AI 决策 + 人工审核;复杂任务(复杂逻辑测试、异常场景验证)由 AI 辅助 + 人工决策(AITest 核心经验);
- 低门槛交互与信心量化:携程 “AI 测试员” 支持 “一键触发生成 + 一键采纳”,通过消息通知同步进度;同时,通过 “生成准确率、误报率、修正成本” 等指标量化 AI 信心,让测试人员清晰感知能力边界,逐步重建信任;
- 闭环反馈机制:携程建立 “用例生成 - 采纳 - 数据回收” 机制,有赞 AITest 通过失败案例沉淀、提示词优化持续迭代模型,将用户反馈转化为模型优化依据。
三、核心技术支撑:从 “模型应用” 到 “工程化落地” 的关键
三大案例的成功,离不开 “技术适配场景” 的核心逻辑 —— 并非依赖通用大模型,而是通过领域知识融合、工程化创新,让 AI 真正适配测试需求:
1. LLM 与领域知识的深度融合
通用大模型难以直接满足测试场景需求,三大案例均通过 “注入领域知识” 提升准确性:携程在模型中融入 “边界值分析、等价类划分” 等测试方法论;有赞 AITest 沉淀测试用例知识库;联通则针对智算网络特性,定制化开发测试用例生成逻辑,确保 AI 输出符合行业规范。
2. 提示词工程与数据闭环
提示词是连接 AI 与业务的关键桥梁:携程通过 “结构化解析 PRD→需求提取→场景生成→结构化输出” 四步提示词流程,将模糊需求转化为标准化用例;同时,三大案例均重视 “数据闭环”—— 通过 “生成准确率、采纳率、覆盖率” 等量化指标评估效果,将失败案例、人工修正内容沉淀为训练数据,持续优化模型输出。
3. 分布式与兼容性技术创新
针对垂直场景的特殊需求,技术架构需突破传统局限:联通 AI 智算平台采用分布式测试架构,通过多设备部署节点提升并发效率;同时重构仪表接口,兼容多厂商设备,解决智算网络 “大规模、多设备” 的测试难题,为垂直领域 AI 测试提供硬件支撑。
四、未来演进:从辅助到自主的三阶段路径
从三大案例的规划与实践来看,AI 测试的未来将围绕 “能力深化、工程化升级、场景拓展” 展开,逐步实现从 “辅助” 到 “自主” 的跨越:
1. 第一阶段:AI 辅助测试(当前主流)
核心特征是 “人主导,AI 解决单点问题”—— 如携程用例生成、有赞 AITest 的异常场景兜底,AI 承担重复性工作,人类负责关键决策与质量把控。此阶段的重点是优化人机协同效率,通过低门槛交互、信心量化提升用户信任。
2. 第二阶段:AI 驱动测试(中期目标)
核心特征是 “AI 接管大部分任务,人类监督关键决策”—— 依赖大模型能力突破与工程化升级,实现 “AI 独立理解需求、生成用例、执行验证”,人类仅在复杂场景(如跨系统逻辑测试)介入。有赞 AITest 已明确此阶段目标,计划通过知识图谱、多智能体协作提升 AI 自主性。
3. 第三阶段:AI 自主测试(终极愿景)
核心特征是 “AI 全流程闭环,人类仅介入极端场景”——AI 可自主识别需求变化、生成测试方案、执行验证、修复简单缺陷,形成 “需求 - 测试 - 反馈” 的自主循环。携程计划引入 “多 Agent 架构”,推动用例生成、验证、优化全流程自动化,为这一阶段奠定基础。
结语:AI 测试的本质是 “放大人类能力”
三大实践案例共同印证:AI 测试的核心价值并非 “替代人”,而是 “放大人类能力”—— 通过 AI 处理重复性、探索性工作,让人聚焦于复杂逻辑设计、风险评估等高价值任务。其成功落地的关键,在于 “工程化思维 + 人机协同模式 + 场景化适配”:有赞的 “AI× 程序 × 人” 三角协同、携程的闭环反馈机制、联通的垂直领域定制化,均为行业提供了可借鉴的路径。
随着模型能力的迭代与工程化手段的成熟,AI 将逐步从 “测试辅助工具” 升级为 “核心驱动力量”,最终推动软件测试进入 “自主化、智能化” 的全新阶段 —— 而这一过程,需要持续打破技术瓶颈、优化人机协同、拓展场景边界,让 AI 真正成为测试人员的 “最佳搭档”。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)