C# .NET:抓取动态(JS)网站
·
问题:C# .NET:抓取动态(JS)网站
经过几个小时的失败,我来到了这里。我需要抓取一个动态生成的网页(使用 Vue.JS 制作,但我不想分享链接)。
我尝试了多种方法(1,2,3)。他们都没有在这个网页上工作。
最有希望的解决方案是使用 Selenium 和 PhantomJS。我这样尝试过,但我不确定为什么它甚至不适用于 Google:
private void button1_Click(object sender, EventArgs e) {
PhantomJSDriverService service = PhantomJSDriverService.CreateDefaultService();
service.IgnoreSslErrors = true;
service.LoadImages = false;
service.ProxyType = "none";
var driver = new PhantomJSDriver(service); // I also tried: new PhantomJSDriver();
driver.Manage().Timeouts().PageLoad = TimeSpan.FromSeconds(10);
driver.Url = "https://google.com";
driver.Navigate();
var source = driver.PageSource;
textBox1.AppendText(source);
}
不工作:
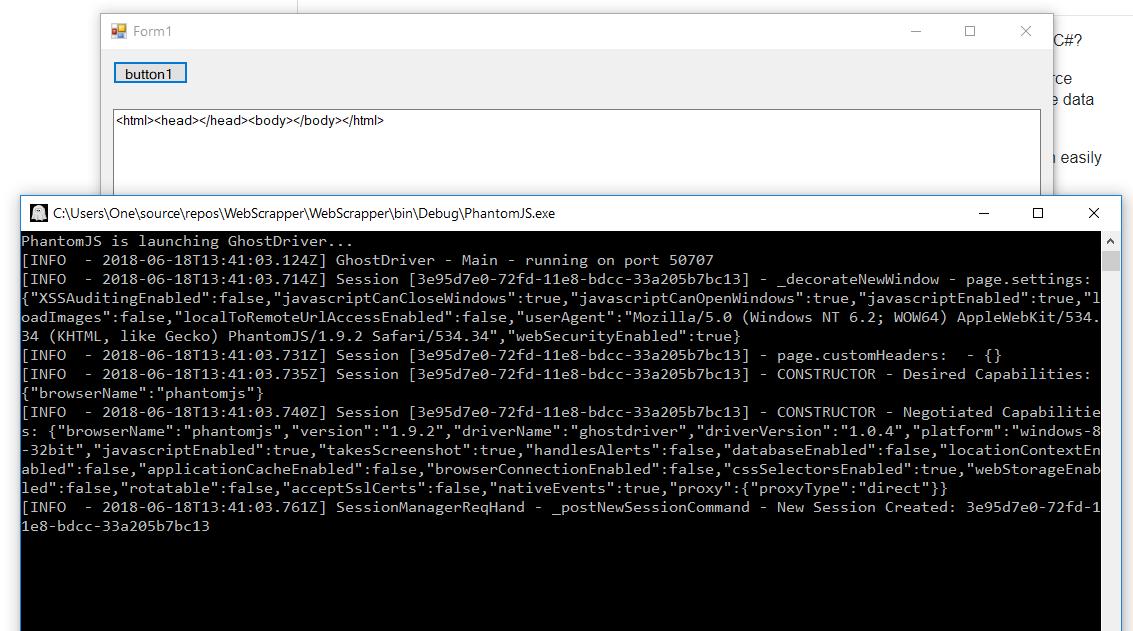
我也尝试使用 WebBrowser 控件,但页面从未完全加载:
(**编辑:**我发现 WebBrowser 只是实例化 IE,在尝试在独立的 IE 浏览器中打开目标网站后,网页也永远不会完全加载,所以在 WebView 中看到相同的行为是有意义的。我想我由于这个事实,我绑定到 Selenium&PhantomJS。)
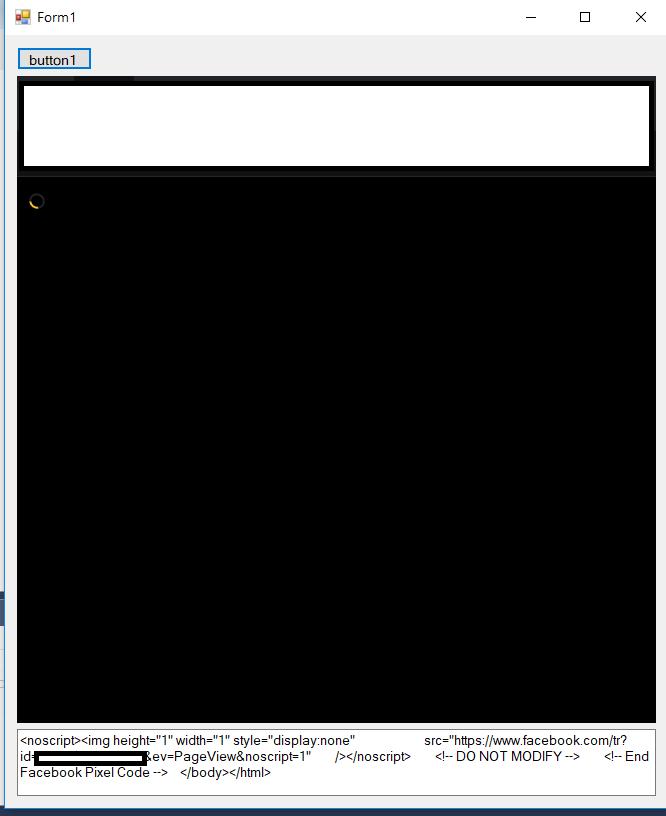
当然,这不应该那么复杂。如何正确地做到这一点?
解答
如果你需要抓取一个网站,你可以使用 ScrapySharp 抓取框架。您可以将其作为 nuget 添加到项目中。https://www.nuget.org/packages/ScrapySharp/
安装包 ScrapySharp -版本 2.6.2
它具有许多有用的属性来访问页面上的不同元素。例如,要访问页面的整个 HTML,您可以使用以下内容:
ScrapingBrowser Browser = new ScrapingBrowser();
WebPage PageResult = Browser.NavigateToPage(new Uri("http://www.example-site.com"));
HtmlNode rawHTML = PageResult.Html;
Console.WriteLine(rawHTML.InnerHtml);
Console.ReadLine();

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)