

I have the following Python code:
FONT = cv2.FONT_HERSHEY_SIMPLEX
FONT_SCALE = 1.0
FONT_THICKNESS = 2
bg_color = (255, 255, 255)
label_color = (0, 0, 0)
label = 'Propaganda'
label_width, label_height = cv2.getTextSize(label, FONT, FONT_SCALE, FONT_THICKNESS)[0]
label_patch = np.zeros((label_height, label_width, 3), np.uint8)
label_patch[:,:] = bg_color
I create a new blank image, with the size returned by getTextSize, and then, I add the text at the bottom-left point, according to the docs, which is x = 0, y = (height - 1) and with the same font, scale and thickness parameters used for getTextSize
cv2.putText(label_patch, label, (0, label_height - 1), FONT, FONT_SCALE, label_color, FONT_THICKNESS)
But when I use imshow or imwrite on the image label_patch, this is the results I get:

It can easily be seen that lowercase p and lowercase g are cut in the middle, such that g and a cannot even be distinguished. How can I make OpenCV's getTextSize return the correct size, and how can I make OpenCV's putText start drawing the text from the actual lowest point?
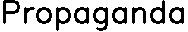





 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)