There are so many posts like this about how to extract sklearn decision tree rules but I could not find any about using pandas.
Take this data and model for example, as below
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
The result:
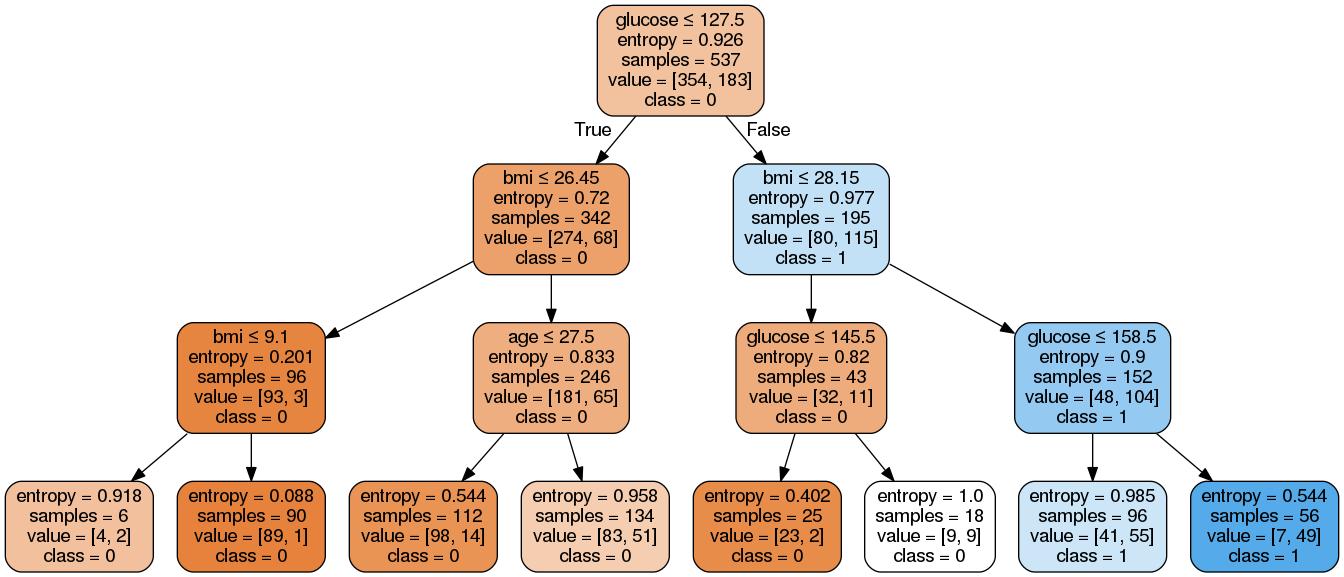
Expected:
There're 8 rules about this example.
From left to right,notice that dataframe is df
r1 = (df['glucose']<=127.5) & (df['bmi']<=26.45) & (df['bmi']<=9.1)
……
r8 = (df['glucose']>127.5) & (df['bmi']>28.15) & (df['glucose']>158.5)
I'm not a master of extracting sklearn decision tree rules. Getting the pandas boolean conditions will help me calculate samples and other metrics for each rule. So I want to extract each rule to a pandas boolean condition.
First of all let's use the scikit documentation on decision tree structure to get information about the tree that was constructed :
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
feature = clf.tree_.feature
threshold = clf.tree_.threshold
We then define two recursive functions. The first one will find the path from the tree's root to create a specific node (all the leaves in our case). The second one will write the specific rules used to create a node using its creation path :
def find_path(node_numb, path, x):
path.append(node_numb)
if node_numb == x:
return True
left = False
right = False
if (children_left[node_numb] !=-1):
left = find_path(children_left[node_numb], path, x)
if (children_right[node_numb] !=-1):
right = find_path(children_right[node_numb], path, x)
if left or right :
return True
path.remove(node_numb)
return False
def get_rule(path, column_names):
mask = ''
for index, node in enumerate(path):
#We check if we are not in the leaf
if index!=len(path)-1:
# Do we go under or over the threshold ?
if (children_left[node] == path[index+1]):
mask += "(df['{}']<= {}) \t ".format(column_names[feature[node]], threshold[node])
else:
mask += "(df['{}']> {}) \t ".format(column_names[feature[node]], threshold[node])
# We insert the & at the right places
mask = mask.replace("\t", "&", mask.count("\t") - 1)
mask = mask.replace("\t", "")
return mask
Finally, we use those two functions to first store the creation path of each leaf. And then to store the rules used to create each leaf :
# Leaves
leave_id = clf.apply(X_test)
paths ={}
for leaf in np.unique(leave_id):
path_leaf = []
find_path(0, path_leaf, leaf)
paths[leaf] = np.unique(np.sort(path_leaf))
rules = {}
for key in paths:
rules[key] = get_rule(paths[key], pima.columns)
With the data you gave the output is :
rules =
{3: "(df['insulin']<= 127.5) & (df['bp']<= 26.450000762939453) & (df['bp']<= 9.100000381469727) ",
4: "(df['insulin']<= 127.5) & (df['bp']<= 26.450000762939453) & (df['bp']> 9.100000381469727) ",
6: "(df['insulin']<= 127.5) & (df['bp']> 26.450000762939453) & (df['skin']<= 27.5) ",
7: "(df['insulin']<= 127.5) & (df['bp']> 26.450000762939453) & (df['skin']> 27.5) ",
10: "(df['insulin']> 127.5) & (df['bp']<= 28.149999618530273) & (df['insulin']<= 145.5) ",
11: "(df['insulin']> 127.5) & (df['bp']<= 28.149999618530273) & (df['insulin']> 145.5) ",
13: "(df['insulin']> 127.5) & (df['bp']> 28.149999618530273) & (df['insulin']<= 158.5) ",
14: "(df['insulin']> 127.5) & (df['bp']> 28.149999618530273) & (df['insulin']> 158.5) "}
Since the rules are strings, you can't directly call them using df[rules[3]], you have to use the eval function like so df[eval(rules[3])]








 已为社区贡献126450条内容
已为社区贡献126450条内容

所有评论(0)