

I am trying to get the text in the header on this page:

iShares FTSE MIB UCITS ETF EUR (Dist)
The tag looks like this:
<h1 class="product-title" title="iShares FTSE MIB UCITS ETF EUR (Dist)"> iShares FTSE MIB UCITS ETF EUR (Dist) </h1>
I am using this xPath:
xp_name = ".//*[@class[contains(normalize-space(.), 'product-title')]]"
Retrieving via .text in Selenium WebDriver for Python:
new_name = driver.find_element_by_xpath(xp_name).text
The driver finds the xpath, but when I print new_name, macOS Terminal only prints a blank string: ""
What could be the reason for this?
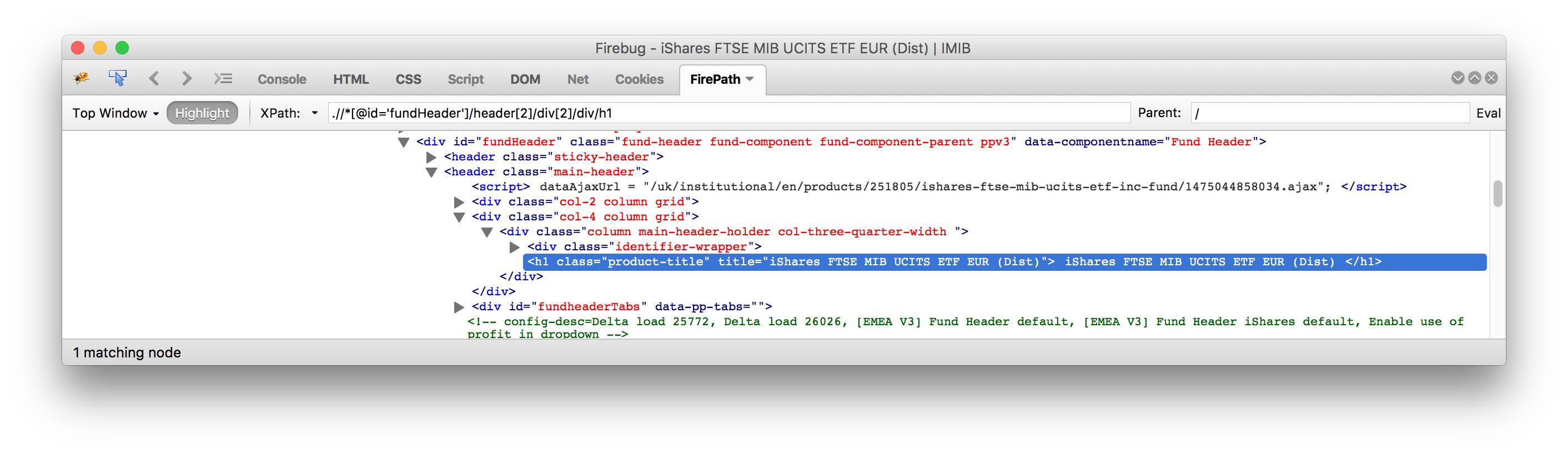
Note: I also tried some other xpath alternatives, getting the same result, for example with:
xp_name = ".//*[@id='fundHeader']//h1"





 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)