使用 python 和 Scikit Learn 为 K-NN 机器学习算法实现 ROC 曲线
回答问题
我目前正在尝试为我的 kNN 分类算法实现 ROC 曲线。我知道 ROC 曲线是真阳性率与假阳性率的图,我只是在努力从我的数据集中找到这些值。我将“autoimmune.csv”导入我的 python 脚本并在其上运行 kNN 算法以输出准确度值。 Scikit-learn.org 文档显示,要生成 TPR 和 FPR,我需要传入 y_test 和 y_scores 的值,如下所示:
fpr, tpr, threshold = roc_curve(y_test, y_scores)
我只是在为这些值应该使用什么而苦苦挣扎。提前感谢您的帮助,如果我错过了什么,我们深表歉意,因为这是我在这里的第一篇文章。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('./autoimmune.csv')
X = data.drop(columns=['autoimmune'])
y = data['autoimmune'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
knn = KNeighborsClassifier(n_neighbors = 10)
knn.fit(X_train,y_train)
knn.predict(X_test)[0:10]
knn.score(X_test,y_test)
print("Test set score: {:.4f}".format(knn.score(X_test, y_test)))
knn_cv = KNeighborsClassifier(n_neighbors=10)
cv_scores = cross_val_score(knn_cv, X, y, cv=10)
print(cv_scores)
print('cv_scores mean:{}' .format(np.mean(cv_scores)))
y_scores = cross_val_score(knn_cv, X, y, cv=76)
fpr, tpr, threshold = roc_curve(y_test, y_scores)
roc_auc = auc(fpr, tpr)
print(roc_auc)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('ROC Curve of kNN')
plt.show()
Answers
如果您查看roc_curve()](http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html)的[文档,您将看到有关y_score参数的以下内容:
y_score : array, shape u003d [n_samples] 目标分数,可以是正类的概率估计、置信度值或决策的非阈值度量(由“decision\ _function”在一些分类器上)。
您可以使用 sklearn 中的KNeighborsClassifier](http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier.predict_proba)的[predict_proba()方法获得概率估计。这将返回一个 numpy 数组,其中包含两列用于二进制分类,每列用于负类和正类。对于roc_curve()函数,您想使用正类的概率估计,因此您可以替换您的:
y_scores = cross_val_score(knn_cv, X, y, cv=76)
fpr, tpr, threshold = roc_curve(y_test, y_scores)
和:
y_scores = knn.predict_proba(X_test)
fpr, tpr, threshold = roc_curve(y_test, y_scores[:, 1])
请注意,您如何需要使用[:, 1]获取第二列的所有行来仅选择正类的概率估计。这是使用威斯康星州乳腺癌数据集的最小可重复示例,因为我没有您的autoimmune.csv:
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
knn = KNeighborsClassifier(n_neighbors = 10)
knn.fit(X_train,y_train)
y_scores = knn.predict_proba(X_test)
fpr, tpr, threshold = roc_curve(y_test, y_scores[:, 1])
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('ROC Curve of kNN')
plt.show()
这将产生以下 ROC 曲线:
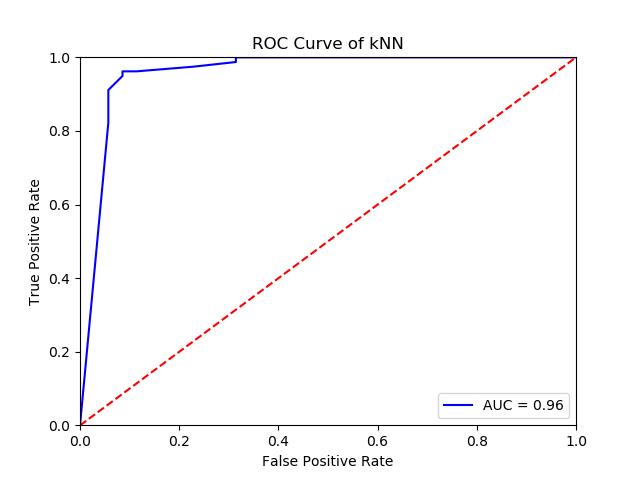

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126445条内容
已为社区贡献126445条内容

所有评论(0)