

I have a reactor that fetches messages from a RabbitMQ broker and triggers worker methods to process these messages in a process pool, something like this:
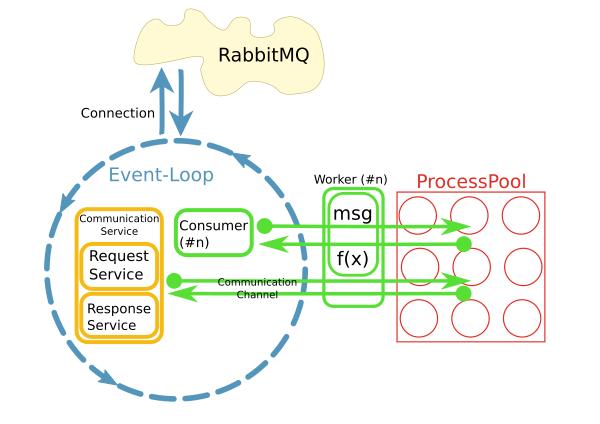
This is implemented using python asyncio, loop.run_in_executor() and concurrent.futures.ProcessPoolExecutor.
Now I want to access the database in the worker methods using SQLAlchemy. Mostly the processing will be very straightforward and quick CRUD operations.
The reactor will process 10-50 messages per second in the beginning, so it is not acceptable to open a new database connection for every request. Rather I would like to maintain one persistent connection per process.
My questions are: How can I do this? Can I just store them in a global variable? Will the SQA connection pool handle this for me? How to clean up when the reactor stops?
[Update]
- The database is MySQL with InnoDB.
Why choosing this pattern with a process pool?
The current implementation uses a different pattern where each consumer runs in its own thread. Somehow this does not work very well. There are already about 200 consumers each running in their own thread, and the system is growing quickly. To scale better, the idea was to separate concerns and to consume messages in an I/O loop and delegate the processing to a pool. Of course, the performance of the whole system is mainly I/O bound. However, CPU is an issue when processing large result sets.
The other reason was "ease of use." While the connection handling and consumption of messages is implemented asynchronously, the code in the worker can be synchronous and simple.
Soon it became evident that accessing remote systems through persistent network connections from within the worker are an issue. This is what the CommunicationChannels are for: Inside the worker, I can grant requests to the message bus through these channels.
One of my current ideas is to handle DB access in a similar way: Pass statements through a queue to the event loop where they are sent to the DB. However, I have no idea how to do this with SQLAlchemy. Where would be the entry point? Objects need to be pickled when they are passed through a queue. How do I get such an object from an SQA query? The communication with the database has to work asynchronously in order not to block the event loop. Can I use e.g. aiomysql as a database driver for SQA?





 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)