C站最全的Python机器学习和深度学习库总结(内含大量实例,推荐收藏)
前言
目前,随着人工智能的普及,已经引起了很多行业对人工智能的关注。同时,也迎来了一波又一波的人工智能学习热潮。尽管人工智能背后的原理无法在一篇短文中详细介绍,但与所有学科一样,我们不需要从头开始“造轮子”。我们可以利用丰富的人工智能框架,快速构建人工智能模型,从而顺应人工智能的潮流。
人工智能是指使机器能够像人类一样处理信息的一系列技术;机器学习是使用计算机编程从历史数据中学习并预测新数据的过程;神经网络是基于生物大脑的结构和特点的机器学习的计算机模型;深度学习是机器学习的一个子集,它处理大量的非结构化数据,例如人类的语音、文本和图像。因此,这些概念在层次上是相互依存的。人工智能是最广泛的术语,而深度学习是最具体的:

为了对人工智能常用的Python库有一个初步的了解,选择能满足自己学习需求的库,本文简要全面介绍一下目前比较常见的人工智能库。
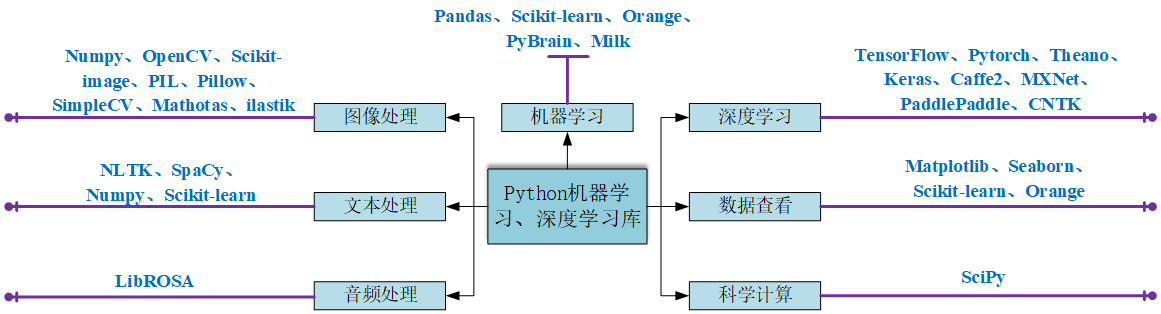
python中常用机器学习和深度学习库介绍
1、Numpy
NumPy(Numerical Python) 是 Python 的扩展库。它支持大量的维数组和矩阵运算。此外,它还提供了大量用于数组运算的数学函数库。 Numpy 底部是用 C 语言编写的。对象直接存储在数组中而不是对象指针中,因此其运行效率远高于纯Python代码。
在示例中,我们可以比较纯 Python 和 Numpy 库计算列表 sin 值的速度:
将 numpy 导入为 np
导入数学
进口随机
进口时间
开始 u003d time.time()
对于范围内的 i (10):
列表_1 u003d 列表(范围(1,10000))
对于范围内的 j (len(list_1)):
列表_1[j] u003d 数学.sin(列表_1[j])
print("使用纯 Python 时间使用{}s".format(time.time()-start))
开始 u003d time.time()
对于范围内的 i (10):
列表_1 u003d np.array(np.arange(1,10000))
列表_1 u003d np.sin(列表_1)
print("使用 Numpy Time 使用{}s".format(time.time()-start))
从下面的运行结果可以看出,使用 Numpy 库的速度比使用纯 Python 编写的代码要快:
使用纯 Python 时间 0.017444372177124023s
使用纯 Python 时间 0.001619577407836914s
2、OpenCV
OpenCV 是一个跨平台的计算机视觉库,可以在 Linux、Windows 和 Mac OS 操作系统上运行。它是轻量级和高效的——它由一系列 C 函数和少量 C++ 类组成。同时,它还提供Python接口,实现了图像处理和计算机视觉中的许多通用算法。
以下代码尝试使用一些简单的过滤器,包括图像平滑和高斯模糊:
将 numpy 导入为 np
将 cv2 导入为 cv
从 matplotlib 导入 pyplot 作为 plt
img u003d cv.imread('h89817032p0.png')
内核 u003d np.ones((5,5),np.float32)/25
dst u003d cv.filter2D(img,-1,内核)
模糊_1 u003d cv.GaussianBlur(img,(5,5),0)
模糊_2 u003d cv.bilateralFilter(img,9,75,75)
plt.figure(figsizeu003d(10,10))
plt.subplot(221),plt.imshow(img[:,:,::-1]),plt.title('原创')
plt.xticks([]), plt.yticks([])
plt.subplot(222),plt.imshow(dst[:,:,::-1]),plt.title('平均')
plt.xticks([]), plt.yticks([])
plt.subplot(223),plt.imshow(模糊_1[:,:,::-1]),plt.title('高斯')
plt.xticks([]), plt.yticks([])
plt.subplot(224),plt.imshow(模糊_1[:,:,::-1]),plt.title('双边')
plt.xticks([]), plt.yticks([])
plt.show()

可以参考Fundamentals of OpenCV image processing (transformation and denoising),了解更多OpenCV图像处理操作。
3、Scikit-image
Scikit image是一个基于scipy的图像处理库,将图片处理成numpy数组。
例如,您可以使用 scikit image 来更改图片比例。 Scikit image 提供rescale、resize、downscale_local_mean等功能。
从 skimage 导入数据、颜色、io
从 skimage.transform 导入 rescale、resize、downscale_local_mean
图像 u003d color.rgb2gray(io.imread('h89817032p0.png'))
图像_rescaled u003d 重新缩放(图像,0.25,抗_aliasingu003dFalse)
image_resized u003d resize(image, (image.shape[0] // 4, image.shape[1] // 4),
抗锯齿u003d真)
image_downscaled u003d downscale_local_mean(image, (4, 3))
plt.figure(figsizeu003d(20,20))
plt.subplot(221),plt.imshow(图像, cmapu003d'灰色'),plt.title('原始')
plt.xticks([]), plt.yticks([])
plt.subplot(222),plt.imshow(image_rescaled, cmapu003d'gray'),plt.title('Rescaled')
plt.xticks([]), plt.yticks([])
plt.subplot(223),plt.imshow(image_resized, cmapu003d'gray'),plt.title('resized')
plt.xticks([]), plt.yticks([])
plt.subplot(224),plt.imshow(image_downscaled, cmapu003d'gray'),plt.title('Downscaled')
plt.xticks([]), plt.yticks([])
plt.show()

4、Python图像库(PIL)
Python Imaging Library(PIL)已经成为Python事实上的图像处理标准库。这是因为 PIL 非常强大,但 API 非常简单易用。
但由于 PIL 只支持 Python 2.7 且年久失修,一群志愿者基于 PIL 创建了一个兼容版本,命名为 Pilot,它支持最新的 Python 3.0 x。增加了很多新功能,所以我们可以跳过PIL,直接安装使用pilot。
5、枕头
使用 Pilot 生成字母数字验证码图像:
从 PIL 导入 Image、ImageDraw、ImageFont、ImageFilter
进口随机
随机字母:
定义 rndChar():
return chr(random.randint(65, 90))
随机颜色1:
定义 rndColor():
返回(Random.Randint(64, 255), Random.Randint(64, 255), Random.Randint(64, 255))
随机颜色2:
定义 rndColor2():
返回(Random.Randint(32, 127), Random.Randint(32, 127), Random.Randint(32, 127))
240 x 60:
宽度 u003d 60 * 6
高度 u003d 60 * 6
image u003d Image.new('RGB', (width, height), (255, 255, 255))
创建一个字体对象:
font u003d ImageFont.truetype('/usr/share/fonts/wps-office/simhei.ttf', 60)
创建一个绘图对象:
绘制 u003d ImageDraw.Draw(图像)
填充每个像素:
对于范围内的 x(宽度):
对于范围内的 y(高度):
draw.point((x, y), 填充u003drndColor())
输出文本:
对于范围内的 t (6):
draw.text((60 * t + 10, 150), rndChar(), 字体u003d字体, 填充u003drndColor2())
#模糊:
图像 u003d image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg')
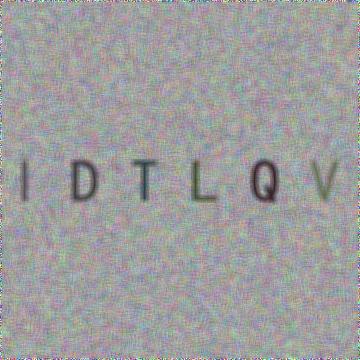
6、SimpleCV
SimpleCV 是一个用于构建计算机视觉应用程序的开源框架。有了它,您可以访问高性能计算机视觉库,例如 OpenCV,而无需先了解位深度、文件格式、色彩空间、缓冲区管理、特征值或矩阵等术语。但是它对 Python 3 的支持很差 7 中使用了以下代码:
从 SimpleCV 导入图像、颜色、显示
从 imgur 加载图像
img u003d Image('http://i.imgur.com/lfAeZ4n.png')
使用关键点检测器找到感兴趣的区域
壮举 u003d img.findKeypoints()
绘制关键点列表
壮举.draw(coloru003dColor.RED)
显示生成的图像。
img.show()
将我们找到的东西应用到图像上。
输出 u003d img.applyLayers()
保存结果。
output.save('juniperfeats.png')
会报如下错误,所以不建议在Python 3中使用:
语法错误:调用“打印”时缺少括号。你的意思是打印('单元测试')?
7,马霍塔斯
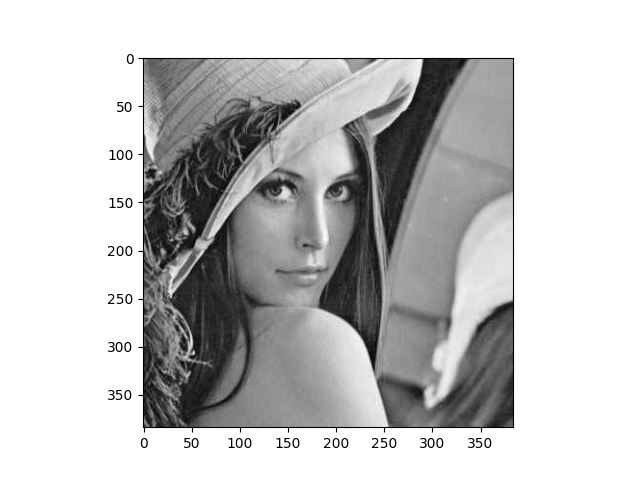
Mahotas 是一个基于 Numpy 构建的快速计算机视觉算法库。目前,它已拥有超过 100 种图像处理和计算机视觉功能,并且还在不断壮大中。
使用 Mahotas 加载图像并对像素进行操作:
将 numpy 导入为 np
进口 mahotas
导入 mahotas.demos
从 mahotas.thresholding 导入软_threshold
从 matplotlib 导入 pyplot 作为 plt
从操作系统导入路径
f u003d mahotas.demos.load('lena', as_greyu003dTrue)
f u003d f[128:,128:]
plt.gray()
显示数据:
print("原始图像中零的分数:{0}".format(np.mean(fu003du003d0)))
plt.imshow(f)
plt.show()
8、弹性
Ilastik 可以为用户提供良好的基于机器学习的生物信息图像分析服务。它可以通过使用机器学习算法轻松地对细胞或其他实验数据进行分割、分类、跟踪和计数。大多数操作都是交互式的,不需要机器学习专业知识。可以参考https://www.ilastik.org/documentation/basics/installation.html进行安装使用。
9、Scikit-learn
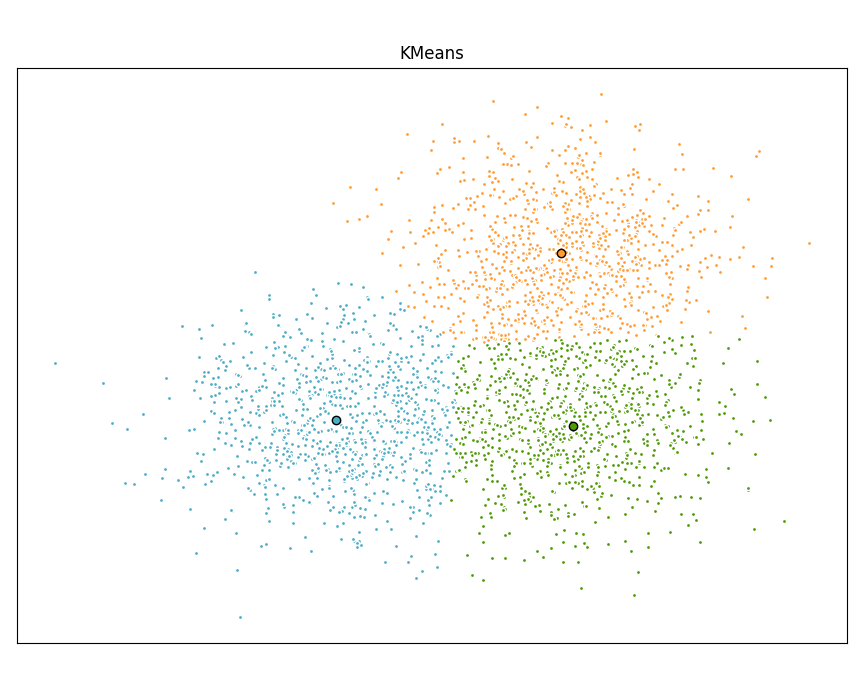
Scikit learn 是一个用于 Python 编程语言的免费软件机器学习库。它具有多种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升、k-means 和 DBSCAN。
使用 scikit learn 实现 KMeans 算法:
进口时间
将 numpy 导入为 np
导入 matplotlib.pyplot 作为 plt
从 sklearn.cluster 导入 MiniBatchKMeans、KMeans
从 sklearn.metrics.pairwise 导入 pairwise_distances_argmin
从 sklearn.datasets 导入 make_blob
生成样本数据
np.random.seed(0)
批次\大小 u003d 45
中心 u003d [[1, 1], [-1, -1], [1, -1]]
n_clusters u003d len(中心)
X,标签_true u003d make_blob(n_samplesu003d3000,centersu003dcenters,cluster_stdu003d0.7)
使用均值计算聚类
k_means u003d KMeans(initu003d'k-means++', n_clustersu003d3, n_initu003d10)
t0 u003d time.time()
k_means.fit(X)
t_batch u003d time.time() - t0
使用 MiniBatchKMeans 计算聚类
mbk u003d MiniBatchKMeans(initu003d'k-means++', n_clustersu003d3, batch_sizeu003dbatch_size,
n_initu003d10,最大_no_improvementu003d10,详细u003d0)
t0 u003d time.time()
mbk.fit(X)
t_mini_batch u003d time.time() - t0
绘制结果
fig u003d plt.figure(figsizeu003d(8, 3))
fig.subplots_adjust(leftu003d0.02, rightu003d0.98, bottomu003d0.05, topu003d0.9)
颜色 u003d ['#4EACC5', '#FF9C34', '#4E9A06']
我们希望同一个簇具有相同的颜色
MiniBatchKMeans 和 KMeans 算法。让我们将每个聚类中心配对
最接近的一个。
k_means_cluster_centers u003d k_means.cluster_centers_
order u003d pairwise_distances_argmin(k_means.cluster_centers_,
mbk.cluster_centers_)
mbk_ 表示\cluster\centers u003d mbk.cluster_centers_[order]
k_means_labels u003d 成对_distances_argmin(X, k_means_cluster_centers)
mbk_means_labels u003d 成对_distances_argmin(X, mbk_means_cluster_centers)
K 均值
for k, col in zip(range(n_clusters), colors):
我的_members u003d k_means_labels u003du003d k
cluster\center u003d k\means\cluster\centers[k]
plt.plot(X[my_members, 0], X[my_members, 1], 'w',
markerfacecoloru003dcol,markeru003d'.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecoloru003dcol,
markeredgecoloru003d'k',markersizeu003d6)
plt.title('KMeans')
plt.xticks(())
plt.yticks(())
plt.show()
10,SciPy
SciPy 库提供了许多用户友好和高效的数值计算,例如数值积分、插值、优化、线性代数等。
SciPy库定义了许多数学物理的特殊函数,包括椭圆函数、贝塞尔函数、伽马函数、贝塔函数、超几何函数、抛物柱函数等。
from scipy import special
导入 matplotlib.pyplot 作为 plt
将 numpy 导入为 np
def 鼓面_height(n, k, 距离, 角度, t):
kth_zero u003d special.jn_zeros(n, k)[-1]
return np.cos(t) * np.cos(in*angle) * special.in(n, distance*kth_zero)
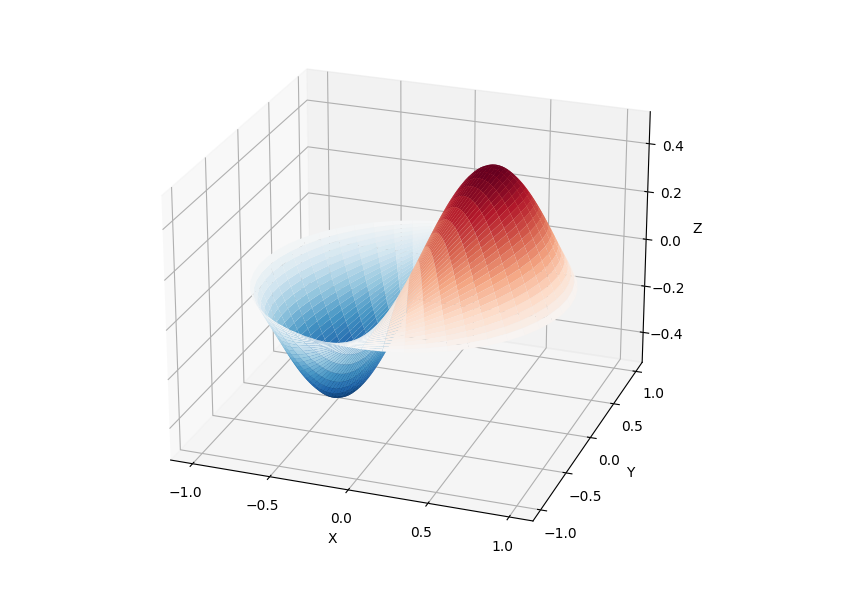
theta u003d np.r_[0:2*np.pi:50j]
半径 u003d np.r_[0:1:50j]
x u003d np.array([r * np.cos(theta) for r in radius])
y u003d np.array([r * np.sin(theta) for r in radius])
z u003d np.array([drumhead_height(1, 1, r, theta, 0.5) for r in radius])
无花果 u003d plt.figure()
ax u003d fig.add_axes(rectu003d(0, 0.05, 0.95, 0.95), 投影u003d'3d')
ax.plot_surface(x, y, z, rstrideu003d1, cstrideu003d1, cmapu003d'RdBu_r', vminu003d-0.5, vmaxu003d0.5)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_xticks(np.arange(-1, 1.1, 0.5))
ax.set_yticks(np.arange(-1, 1.1, 0.5))
ax.set_zlabel('Z')
plt.show()
11,NLTK
NLTK 是一个用于构建 Python 程序以处理自然语言的库。它为 50 多个语料库和词汇资源(如 WordNet)提供了一个易于使用的界面,以及一套用于文本处理库和工业自然语言处理 (NLP) 库的包装器,用于分类、分词、词干、标记、解析和语义推理。
NLTK 被称为“使用 Python 进行计算语言学教学和工作的绝佳工具”。
导入 nltk
从 nltk.corpus 导入树库
首次使用需要下载
nltk.download('点')
nltk.download('平均_perceptron_tagger')
nulltak.download(通过选择'msent_ne_')
nltk.download('单词')
nltk.download('treebank')
sentence u003d """星期四早上八点,亚瑟感觉不太好。"""
标记化
标记 u003d nltk.word_tokenize(句子)
标记 u003d nltk.pos_tag(令牌)
识别命名实体
实体 u003d nltk.chunk.ne_chunk(标记)
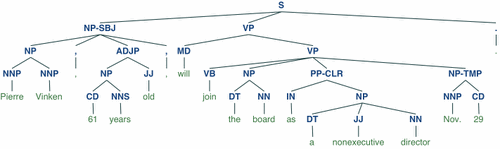
显示解析树
t u003d treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()
12,斯帕西
spaCy 是 Python 中用于高级 NLP 的免费开源库。它可用于构建处理大量文本的应用程序;它还可用于构建信息提取或自然语言理解系统,或预处理文本以进行深度学习。
进口斯派西
文本 u003d [
“净收入为 940 万美元,而上一年为 270 万美元。”,
“收入超过 120 亿美元,亏损 1b 美元。”,
]
nlp u003d spacy.load("en_core_web_sm")
对于 nlp.pipe 中的文档(文本,禁用u003d[“tok2vec”,“tagger”,“parser”,“attribute_ruler”,“lemmatizer”]):
在这里对文档做一些事情
print([(ent.text, ent.label_) for ent in doc.ents])
nlp.pipe 生成 Doc 对象,因此我们可以遍历它们并访问命名实体预测:
[('$940万', 'MONEY'), ('上一年', 'DATE'), ('$270万', 'MONEY')]
[('120 亿美元', 'MONEY'), ('1b', 'MONEY')]
13、LibROSA
librosa 是一个用于音乐和音频分析的 Python 库。它提供了创建音乐信息检索系统所需的功能和功能。
# 节拍跟踪示例
进口图书a
1. 获取包含音频示例的文件路径
文件名 u003d librosa.example('胡桃夹子')
2. 将音频加载为波形 `y`
将采样率存储为 `sr`
y, sr u003d bookeller.load(文件名)
3. 运行默认节拍器
节奏,节拍_frames u003d bookkeeper.beat.beat_track(yu003dy, sru003dsr);
print('估计速度:{:.2f} 每分钟节拍'.format(tempo))
4. 将节拍事件的帧索引转换为时间戳
beat_times u003d librosa.frames\to\time(beat\frames, sru003dsr)
14、熊猫
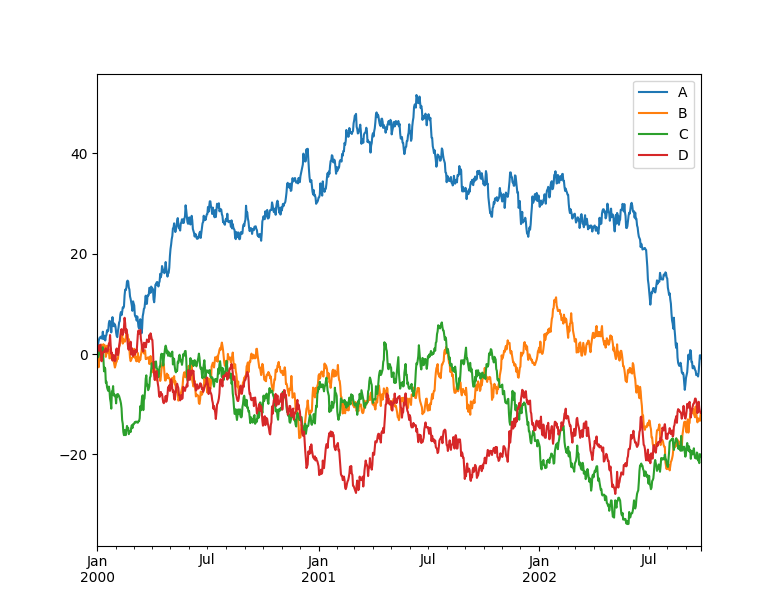
Pandas 是一款快速、强大、灵活、易用的开源数据分析和操作工具。 Pandas 可以从各种文件格式导入数据,例如 CSV、JSON、SQL 和 Microsoft Excel。它可以对各种数据进行操作,如合并、整形和选择,以及数据清洗和数据处理。 Pandas 广泛应用于学术、金融、统计等数据分析领域。
导入 matplotlib.pyplot 作为 plt
将熊猫导入为 pd
将 numpy 导入为 np
ts u003d pd.Series(np.random.randn(1000), indexu003dpd.date_range("1/1/2000", periodu003d1000))
ts u003d ts.cumsum()
df u003d pd.DataFrame(np.random.randn(1000, 4), indexu003dts.index, columnsu003dlist("ABCD"))
df u003d df.cumsum()
df.plot()
plt.show()
15,Matplotlib
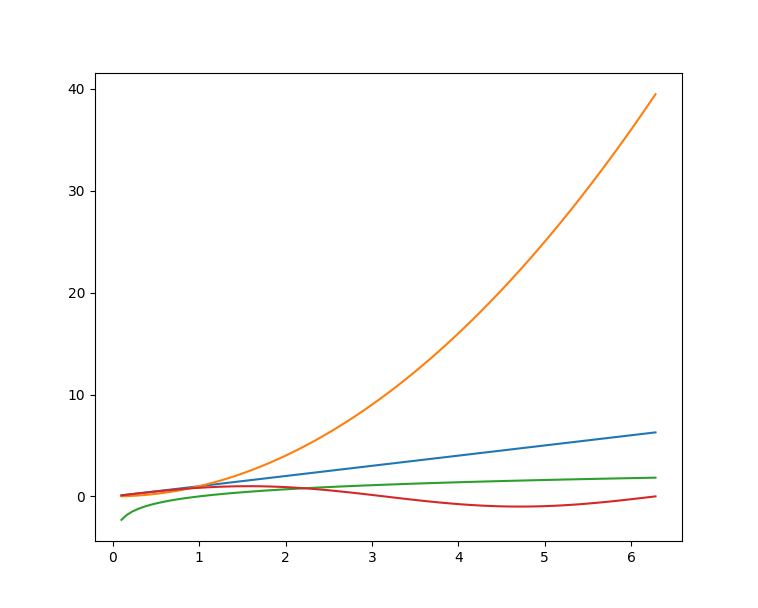
Matplotlib 是 Python 的绘图库。提供了一套完整的类似matlab的命令API,可以生成精美的出版质量级别的图形。 Matplotlib 使绘图变得非常简单,并在易用性和性能之间取得了极好的平衡。
使用 Matplotlib 绘制多条曲线:
# plot_multi_curve.py
将 numpy 导入为 np
导入 matplotlib.pyplot 作为 plt
x u003d np.linspace(0.1, 2 * np.pi, 100)
y_1 u003d x
y_2 u003d np.square(x)
y_3 u003d np.log(x)
y_4 u003d np.sin(x)
plt.plot(x,y_1)
plt.plot(x,y_2)
plt.plot(x,y_3)
plt.plot(x,y_4)
plt.show()
 有关Matplotlib绘图的更多信息,请参考上一篇博文——Python Matplotlib可视化。
有关Matplotlib绘图的更多信息,请参考上一篇博文——Python Matplotlib可视化。
16, 希伯恩
Seaborn 是一个 Python 数据可视化库,基于 Matplotlib 进行了更高级的 API 封装,让绘图变得更简单。 Seaborn 应该被视为对 Matplotlib 的补充,而不是替代品。
将 seaborn 导入为 sns
导入 matplotlib.pyplot 作为 plt
sns.set_theme(styleu003d"ticks")
df u003d sns.load_dataset("企鹅")
sns.pairplot(df,色调u003d“物种”)
plt.show()
! zoz100078](https://programming.vip/images/doc/c1d71187fc9f311d31af1908660dda99.jpg)
17、橙
Orange 是一款开源数据挖掘和机器学习软件,提供了一系列数据探索、可视化、预处理和建模组件。 Orange具有美观直观的交互用户界面,非常适合新手进行探索性数据分析和可视化展示;同时,高级用户也可以将其作为 Python 的编程模块,进行数据操作和组件开发。
使用pip安装Orange,好评~
$ pip install orange3
安装完成后,在命令行输入Orange canvas命令启动Orange图形界面:
$ 橙色画布
启动后可以看到Orange图形界面进行各种操作。
18,PyBrain
PyBrain 是 Python 的模块化机器学习库。其目标是为机器学习任务和各种预定义环境提供灵活、易用和强大的算法来测试和比较算法。 PyBrain 是基于 Python 的强化学习、艺术智能和神经网络库的缩写。
我们将使用一个简单的示例来展示 PyBrain 的用法并构建一个多层感知器(MLP)。
首先,我们创建一个新的前馈网络对象:
从 pybrain.structure 导入 FeedForwardNetwork
in u003d 前馈网络()
接下来,构建输入、隐藏和输出层:
从 pybrain.structure 导入 LinearLayer、SigmoidLayer
inLayer u003d 线性层(2)
hiddenLayer u003d SigmoidLayer(3)
外层 u003d 线性层(1)
为了使用您构建的层,您必须将它们添加到网络中:
n.addInputModule(inLayer)
n.addModule(hiddenLayer)
n.addOutputModule(outLayer)
可以添加多个输入和输出模块。为了计算前向误差和向后传播误差,网络必须知道哪些层是输入,哪些层是输出。
这需要明确确定它们应如何连接。为此,我们使用最常见的连接类型,全连接层,由 FullConnection 类实现:
从 pybrain.structure 导入 FullConnection
in_ to_ hidden u003d FullConnection(in Layer, hidden Layer)
hidden_to_out u003d FullConnection(hiddenLayer, outLayer)
像层一样,我们必须明确地将它们添加到网络中:
n.addConnection(in_to_hidden)
n.addConnection(隐藏_to_out)
现在所有元素都已就位,最后,我们需要调用 sortModules() 方法使 MLP 可用:
n.sortModules()
此调用执行一些内部初始化,这在使用网络之前是必需的。
19、牛奶
MILK(MACHINE LEARNING TOOLKIT) 是 Python 语言的机器学习工具包。它主要包括许多分类器,如SVMS、K-NN、随机森林和决策树中的监督分类。它还可以进行特征选择,形成不同的分类系统,例如 MILK 支持的无监督学习、亲和传播和 K-means 聚类。
用 MILK 训练分类器:
将 numpy 导入为 np
进口牛奶
特征 u003d np.random.rand(100,10)
标签 u003d np.zeros(100)
特征[50:] +u003d .5
标签[50:] u003d 1
学习者 u003d milk.defaultclassifier()
模型 u003d learner.train(特征、标签)
现在您可以在新示例中使用该模型:
示例 u003d np.random.rand(10)
打印(模型。应用(示例))
示例 2 u003d np.random.rand(10)
示例 2 +u003d .5
打印(模型。应用(示例 2))
20,TensorFlow
Tensorflow 是一个端到端的开源机器学习平台。它有一个全面而灵活的生态系统,一般可以分为 tensorflow 1 X 和 tensorflow2 x,TensorFlow1.x 和 tensorflow2 X 的主要区别在于 TF1 X 使用静态图而不是 TF2 X 使用 Eager Mode 动态图。
这里主要以Tensorflow2为例,在tensorflow2中展示了一个在X中构建的卷积神经网络(CNN)。
将张量流导入为 tf
从 tensorflow.keras 导入数据集、层、模型
数据加载
(train_images, train_labels), (test_images, test_labels) u003d datasets.cifar10.load_data()
数据预处理
训练_images,测试_images u003d 训练_images / 255.0,测试_images / 255.0
模型构建
模型 u003d 模型.Sequential()
model.add(layers.Conv2D(32, (3, 3), activationu003d'relu', input_shapeu003d(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activationu003d'relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activationu003d'relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activationu003d'relu'))
模型.add(layers.Dense(10))
模型编译和训练
model.compile(优化器u003d'亚当',
损失u003dtf.keras.losses.SparseCategoricalCrossentropy(来自_logitsu003dTrue),
指标u003d['准确度'])
历史 u003d model.fit(train_images, train_labels, epochsu003d10,
验证\数据u003d(测试_图像,测试\标签))
想了解更多关于tensorflow2的X示例,请参考TensorFlow专栏。
21,PyTorch
PyTorch 的前身是 Torch。它的底层与 Torch 框架相同,但它使用 Python 重写了很多内容。它不仅更灵活,支持动态图表,还提供了python接口。
# 导入库
进口火炬
从火炬进口 nn
从 torch.utils.data 导入 DataLoader
从 torchvision 导入数据集
从 torchvision.transforms 导入 ToTensor、Lambda、Compose
导入 matplotlib.pyplot 作为 plt
模型构建
设备 u003d “cuda” 如果 torch.cuda.is_available() 否则 “cpu”
print("使用 {} 设备".format(device))
定义模型
类神经网络(nn.Module):
定义__init__(自我):
超级(神经网络,自我)。__init__()
self.flatten u003d nn.Flatten()
self.linear_relu_stack u003d nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def 前向(自我,x):
x u003d self.flatten(x)
logits u003d self.linear_relu_stack(x)
返回日志
模型 u003d 神经网络().to(设备)
损失函数和优化器
损失_fn u003d nn.CrossEntropyLoss()
优化器 u003d torch.optim.SGD(model.parameters(), lru003d1e-3)
模型训练
def train(数据加载器,模型,损失_fn,优化器):
大小 u003d len(dataloader.dataset)
对于批处理,枚举(数据加载器)中的(X,y):
X, y u003d X.to(设备), y.to(设备)
计算预测误差
pred u003d 模型(X)
损失 u003d 损失_fn(pred, y)
反向传播
优化器.zero_grad()
loss.backward()
优化器.step()
如果批次 % 100 u003du003d 0:
损失,当前 u003d loss.item(),批处理 * len(X)
打印(f“损失:{损失:>7f} [{当前:>5d}/{大小:>5d}]”)
zoz100025 22, Theano
Theano 是一个 Python 库,可让您定义、优化和有效评估涉及多维数组的数学表达式,构建在 NumPy 之上。
在 Theano 中计算雅可比矩阵:
导入我看到了
导入 theano.tensor 作为 T
x u003d T.dvector('x')
y u003d x ** 2
J , 更新 u003d theano .scan ( lambda i , y , x : T . grad ( y \ [ i \ ] , x ) , 序列 u003d T . range ( y . shape \ [ 0 \ ] ), 非 _sequences u003d [y,x])
f u003d theano.function([x], J, 更新u003d更新)
f([4, 4])
23, 大声
Keras 是用 Python 编写的高级神经网络 API,可以以 TensorFlow、CNTK 或 Theano 作为后端运行。 Keras 的开发重点是支持快速实验,并能够以最小的延迟将想法转化为实验结果。
从 keras.models 导入顺序
从 keras.layers 导入密集
模型构建
模型 u003d 顺序()
model.add(密集(单位u003d64,激活u003d'relu',输入_dimu003d100))
model.add(密集(单位u003d10,激活u003d'softmax'))
模型编译和训练
model.compile(lossu003d'categorical_crossentropy',
优化器u003d'sgd',
指标u003d['准确度'])
model.fit(x_train, y_train, epochsu003d5, batch_sizeu003d32)
24, 咖啡厅
在Caffe2官网上写着: Caffe2 现在是 PyTorch 的一部分。尽管这些 API 将继续工作,但鼓励使用 PyTorch api。
25, MXNet
MXNet 是一个专为提高效率和灵活性而设计的深度学习框架。它允许混合符号编程和命令式编程,以最大限度地提高效率和生产力。
使用 MXNet 构建手写数字识别模型:
将 mxnet 导入为 mx
从 mxnet 导入胶子
从 mxnet.gluon 导入 nn
从 mxnet 导入 autograd 作为 ag
将 mxnet.ndarray 导入为 F
数据加载
mnist u003d mx.test_utils.get_mnist()
批次_size u003d 100
train_data u003d mx.io.NDArrayIter(mnist['train_data'], mnist['train_label'], batch_size, shuffleu003dTrue)
val_data u003d mx.io.NDArrayIter(mnist['test_data'], mnist['test_label'], batch_size)
CNN模型
类网络(gluon.Block):
def __init__(自我,**kwargs):
super(Net, self).__init__(**kwargs)
self.conv1 u003d nn.Conv2D(20, kernel_sizeu003d(5,5))
self.pool1 u003d nn.MaxPool2D(pool_sizeu003d(2,2), strides u003d (2,2))
self.conv2 u003d nn.Conv2D(50, kernel_sizeu003d(5,5))
self.pool2 u003d nn.MaxPool2D(pool_sizeu003d(2,2), strides u003d (2,2))
self.fc1 u003d nn.Dense(500)
self.fc2 u003d nn.Dense(10)
def 前向(自我,x):
x u003d self.pool1(F.tanh(self.conv1(x)))
x u003d self.pool2(F.tanh(self.conv2(x)))
0 表示从相应维度复制大小。
-1 表示从其余维度推断大小。
x u003d x.reshape((0, -1))
x u003d F.tanh(self.fc1(x))
x u003d F.tanh(self.fc2(x))
返回 x
净 u003d 净()
初始化和优化器定义
在 GPU 上设置上下文可用,否则 CPU
ctx u003d [mx.gpu() 如果 mx.test_utils.list_gpus() 否则 mx.cpu()]
net.initialize(mx.init.Xavier(幅度u003d2.24),ctxu003dctx)
培训师 u003d gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.03})
模型训练
使用准确度作为评估指标。
公制 u003d mx.metric.Accuracy()
softmax_cross_entropy_loss u003d gluon.loss.SoftmaxCrossEntropyLoss()
对于我在范围内(纪元):
重置训练数据迭代器。
训练_data.reset()
对于 train_data 中的批处理:
数据 u003d gluon.utils.split_and_load(batch.data[0], ctx_listu003dctx, batch_axisu003d0)
标签 u003d gluon.utils.split_and_load(batch.label[0], ctx_listu003dctx, batch_axisu003d0)
输出 u003d []
训练范围内
使用 ag.record():
对于 zip 中的 x、y(数据、标签):
z u003d 净(x)
计算 softmax 交叉熵损失。
损失 u003d softmax_cross_entropy_loss(z, y)
反向传播一次迭代的错误。
loss.backward()
输出.append(z)
metric.update(标签,输出)
trainer.step(batch.data[0].shape[0])
获取评估结果。
名称,acc u003d metric.get()
将评估结果重置为初始状态。
metric.reset()
print('在 epoch %d 训练 acc: %su003d%f'%(i, name, acc))
26,桨桨
基于百度多年的深度学习技术研究和业务应用,paddepaddele集成了深度学习核心训练和推理框架、基础模型库、端到端开发包和丰富的工具组件。是国内首个自主研发、功能齐全、开源开放的工业级深度学习平台。
使用 PaddlePaddle 实现 LeNtet5:
# 导入需要的包
进口桨
将 numpy 导入为 np
从 paddle.nn 导入 Conv2D、MaxPool2D、线性
网络
导入 paddle.nn.functional 作为 F
定义LeNet网络结构
类 LeNet(paddle.nn.Layer):
def __init__(self, num_classesu003d1):
超级(LeNet,自我)。__init__()
创建卷积和池化层
创建第一个体积层
self.conv1 u003d Conv2D(in_channelsu003d1, out_channelsu003d6, kernel_sizeu003d5)
self.max_pool1 u003d MaxPool2D(内核_sizeu003d2, strideu003d2)
大小逻辑:池层中通道数不变;当前通道数为6
创建第二个体积层
self.conv2 u003d Conv2D(in_channelsu003d6, out_channelsu003d16, kernel_sizeu003d5)
self.max_pool2 u003d MaxPool2D(内核_sizeu003d2, strideu003d2)
创建第三卷层
self.conv3 u003d Conv2D(in_channelsu003d16, out_channelsu003d120, kernel_sizeu003d4)
大小逻辑:输入层将数据展平 [b, C, h, w] - [b, c * h * w]
输入大小为[28,28]。经过三个卷积和两个池化,C*H*W等于120
self.fc1 u003d 线性(in_featuresu003d120,out_featuresu003d64)
创建全连接层。第一个全连接层的输出神经元个数为64个,第二个全连接层的输出神经元个数为分类标签的类别个数
self.fc2 u003d 线性(in_featuresu003d64,out_featuresu003dnum_classes)
网络的正向计算过程
def 前向(自我,x):
x u003d self.conv1(x)
每个卷积层使用一个 Sigmoid 激活函数,后跟一个 2x2 池
x u003d F.sigmoid(x)
x u003d self.max_pool1(x)
x u003d F.sigmoid(x)
x u003d self.conv2(x)
x u003d self.max_pool2(x)
x u003d self.conv3(x)
大小逻辑:输入层将数据展平 [b, C, h, w] - [b, c * h * w]
x u003d paddle.reshape(x, [x.shape[0], -1])
x u003d self.fc1(x)
x u003d F.sigmoid(x)
x u003d self.fc2(x)
返回 x
27, CNTK
CNTK(Cognitive Toolkit)是一个深度学习工具包,它将神经网络描述为通过有向图的一系列计算步骤。在这个有向图中,叶节点表示输入值或网络参数,而其他节点表示对其输入的矩阵运算。 CNTK 可以轻松实现和组合流行的模型类型,例如 CNN。
CNTK 使用网络描述语言 (NDL) 来描述神经网络。简而言之,需要描述输入特征,输入标签,一些参数,参数与输入的计算关系,目标节点是什么。
NDLNetworkBuilderu003d[
运行u003dndlLR
ndlLRu003d[
样品和标签尺寸
SDimu003d$维度$
LDimu003d1
特征u003d输入(SDim,1)
标签u003d输入(LDim,1)
要学习的参数
B0 u003d 参数(4)
W0 u003d 参数(4, SDim)
B u003d 参数(LDim)
W u003d 参数(LDim,4)
操作
t0 u003d 时间(W0,特征)
z0 u003d 加(t0, B0)
s0 u003d Sigmoid(z0)
t u003d 时间(W, s0)
z u003d 加(t, B)
s u003d Sigmoid(z)
LR u003d 物流(标签,s)
EP u003d SquareError(标签,s)
根节点
FeatureNodesu003d(特征)
标签节点u003d(标签)
CriteriaNodesu003d(LR)
EvalNodesu003d(EP)
输出节点u003d(s,t,z,s0,W0)
]
]
总结与分类
python中常用机器学习和深度学习库总结
图书馆名称
官方网站
简单的介绍
数字货币
http://www.numpy.org/
NumPy 提供对大型多维数组的支持,是计算机视觉中的关键库,因为图像可以表示为多维数组。将图像表示为 NumPy 数组有很多优点
开放式CV
https://opencv.org/
开源计算机视觉库
Scikit 图像
https://scikit-image.org/
图像处理算法的集合。 scikit image 操作的图像只能是 NumPy 数组
Python 图像库(PIL)
http://www.pythonware.com/products/pil/
图像处理库提供强大的图像处理和图形功能
枕头
https://pillow.readthedocs.io/
PIL的一个分支
简单CV
http://simplecv.org/
计算机视觉框架提供了图像处理的关键功能
马霍塔斯
https://mahotas.readthedocs.io/
提供一组图像处理和计算机视觉功能,最初是为生物图像信息学设计的;但是,现在它在其他领域也发挥着重要作用。它完全基于numpy数组作为它的数据类型
松紧带
http://ilastik.org/
用户友好且简单的交互式图像分割、分类和分析工具
Scikit-学习
http://scikit-learn.org/
机器学习库,具有各种分类、回归和聚类算法
科学派
https://www.scipy.org/
科技计算图书馆
NLTK
https://www.nltk.org/
用于处理自然语言数据的库和程序
斯帕西
https://spacy.io/
用于 Python 中高级自然语言处理的开源软件库
书玫瑰
https://librosa.github.io/librosa/
音乐和音频处理库
熊猫
https://pandas.pydata.org/
基于 NumPy 构建的库提供了先进的数据计算工具和易于使用的数据结构
Matplotlib
https://matplotlib.org
绘图库,提供了一套类似于matlab的命令API,可以生成所需出版质量等级的图形
海博恩
https://seaborn.pydata.org/
它是一个基于 Matplotlib 的绘图库
橙子
https://orange.biolab.si/
面向新手和专家的开源机器学习和数据可视化工具包
PyBrain
http://pybrain.org/
机器学习库,提供最新易用的机器学习算法
牛奶
http://luispedro.org/software/milk/
机器学习工具箱主要用于监督学习中的多分类问题
TensorFlow
https://www.tensorflow.org/
开源机器学习和深度学习库
PyTorch
https://pytorch.org/
开源机器学习和深度学习库
西阿诺
http://deeplearning.net/software/theano/
用于快速数学表达式、评估和计算的库已编译为在 CPU 和 GPU 架构上运行
难的
https://keras.io/
高级深度学习库,可在 TensorFlow、CNTK、Theano 或 Microsoft Cognitive Toolkit 上运行
咖啡2
https://caffe2.ai/
Caffe2 是一个具有表现力、速度和模块化的深度学习框架。它是对 Caffe 的实验性重构,可以以更灵活的方式组织计算
MXNet
https://mxnet.apache.org/
设计为高效灵活的深度学习框架,它允许混合符号编程和命令式编程
桨桨
https://www.paddlepaddle.org.cn
基于百度多年的深度学习技术研究和业务应用,集成深度学习核心训练和推理框架、基础模型库、端到端开发包和丰富的工具组件
CNTK
https://centk.ie/
深度学习工具包将神经网络描述为通过有向图的一系列计算步骤。在这个有向图中,叶节点表示输入值或网络参数,而其他节点表示对其输入的矩阵运算
分类
这些库可以根据其主要用途分类:
类别
图书馆
图像处理
NumPy、OpenCV、scikit 图像、PIL、Pillow、SimpleCV、Mahotas、ilastic
文本处理
NLTK、spaCy、NumPy、scikit 学习、PyTorch
音频处理
书玫瑰
机器学习
熊猫,scikit-learn,橙色,PyBrain,牛奶
数据视图
Matplotlib,Seaborn,scikit-learn,Orange
深度学习
TensorFlow、Pytorch、Theano、Keras、Caffe2、MXNet、PaddlePaddle、CNTK
科学计算
科学派
更多
其他用于 AI 和机器学习的 Python 库和包可以访问https://python.libhunt.com/packages/artificial-intelligence。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)