PCA降维算法应用实例——kaggle手写数字识别
前言
在上一篇博文中,我们学习了降维算法 PCA,以及PCA 的参数。本文是在对PCA有一定基础的前提下进行的。本文主要介绍PCA算法在实践中的应用。包括PCA参数的选择,PCA在训练集和测试集中的使用,从而解决PCA在实际应用中的困惑。本文使用 kaggle](https://www.kaggle.com/c/digit-recognizer/data)上的[数字识别器数据集。
话题
编程环境
-
python3.7
-
蟒蛇
-
jupyter笔记本
数据准备
可以通过官方频道数据也可以通过博主上传的数据下载。
这次使用的数据集是 kaggle 的数字识别器数据集。数据集包含三个csv文件,如下图

sample_submission.csv 是提交给 kaggle 的 csv 文件格式。 train.csv 是一个训练数据集,包括 784 个特征和一个标签列。共有42000组数据。 test.csv 是一个测试集,包含 784 个特征。该数据集中没有标签列,共有28000组数据。这次只使用了这个数据集中的训练集。 sklearn将原始训练集分为新训练集和测试集。
指南包
将熊猫导入为 pd
将 numpy 导入为 np
导入 matplotlib.pyplot 作为 plt
from sklearn.decomposition import PCA #PCA降维算法
从 sklearn.ensemble 导入 RandomForestClassifier
from sklearn.model_selection import cross_val_score #交叉测试
from sklearn.neighbors import KNeighborsClassifier #KNN分类器
from sklearn.model_selection import train_test_split #拆分训练集
%matplotlib 内联
导入数据
file u003d "../data/digit-recognizer/train.csv" # 改成自己的本地数据集路径
df u003d pd.read_csv(文件)
df.shape #(42000, 785)
可以看出数据集非常大
特征标签分离
X u003d df.loc[:, df.columns !u003d '标签']
y u003d df.loc[:, df.columns u003du003d 'label'].values.ravel()
PCA参数的选择
绘制降维后特征信息的累积和曲线
这一步PCA没有人为设置任何参数,使用PCA的默认值。通过解释_variance_ratio_属性得到的新特征的信息量与原信息的信息量的比例
# 默认返回值PCA返回特征个数为min(shape(X))
获取一次变化后特征的信息量
pca_default u003d PCA()
X_defaule u003d pca_default.fit_transform(X)
每个新特征获得的信息比例
解释_vars u003d pca_default.explained_variance_ratio_
通过 NP Cumsum 计算特征信息的累积和
var_sum u003d np.cumsum(解释_vars)
绘制特征信息的累积和曲线
plt.figure(figsizeu003d(10, 5))
plt.plot(范围(X.shape[1]), var_sum)
plt.xticks(范围(0, X.shape[1], 50))
plt.show()
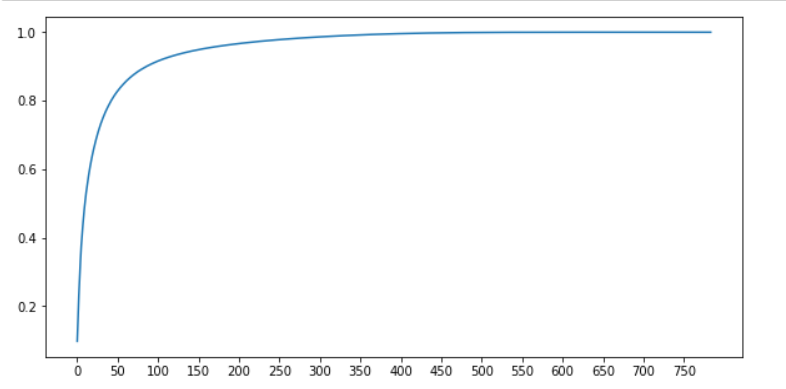
结合模型,进一步选取n_元件的值
如前所述,对 n_ 的 components 参数一般选择在曲线的转折点。
#对于n_元件的选取一般选取曲线上拐点附近的值
从图中可以看出拐点在50-100之间
50时信息量达到80%,100时信息量达到近90%
继续在线,信息量慢慢增加。继续为更多功能而奋斗
这与我们降维的目的背道而驰。索引选择特征较小的 0-100
我们可以知道一定有一个0到100之间的值是我们需要的
接下来将n_分量设置在0-100之间,由模型打分
选择更好的参数
n_components u003d 范围(1, 101, 10)
分数 u003d []
对于 n_components 中的 i :
X_new u003d PCA(n_componentsu003di).fit_transform(X)
score.append(cross_val_score(RandomForestClassifier(n_estimatorsu003d21, random_stateu003d1),
X_new, y, cvu003d5).mean())
fig u003d plt.figure(figsizeu003d(10, 5))
plt.plot(n_components, 分数)
plt.xticks(范围(0, 101, 10))
plt.show()
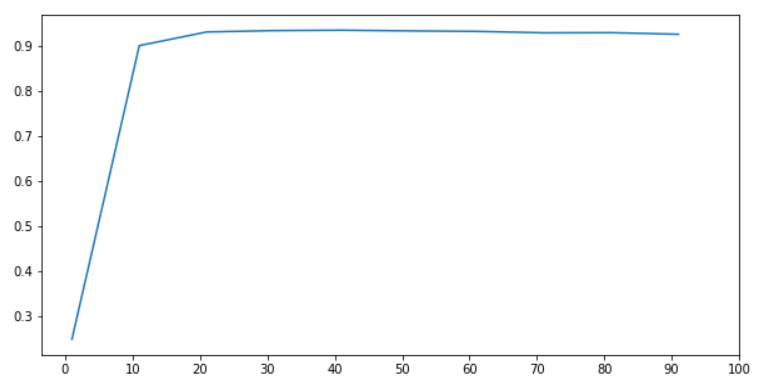
结合模型,找到最佳参数
# 从图中可以看出,我们的模型只需 10 个特征就可以表现良好
当特征个数为20时,模型的性能最好,是一条步长为10的学习曲线
下面是详细的学习曲线
控制特征数量在10-30之间,绘制学习曲线并确定最终的PCA参数
n_components u003d 范围(10, 30)
分数 u003d []
对于 n_components 中的 i :
X_new u003d PCA(n_componentsu003di).fit_transform(X)
score.append(cross_val_score(RandomForestClassifier(n_estimatorsu003d21, random_stateu003d1),
X_new, y, cvu003d5).mean())
fig u003d plt.figure(figsizeu003d(10, 5))
plt.plot(n_components, 分数)
plt.xticks(范围(9, 31))
plt.show()
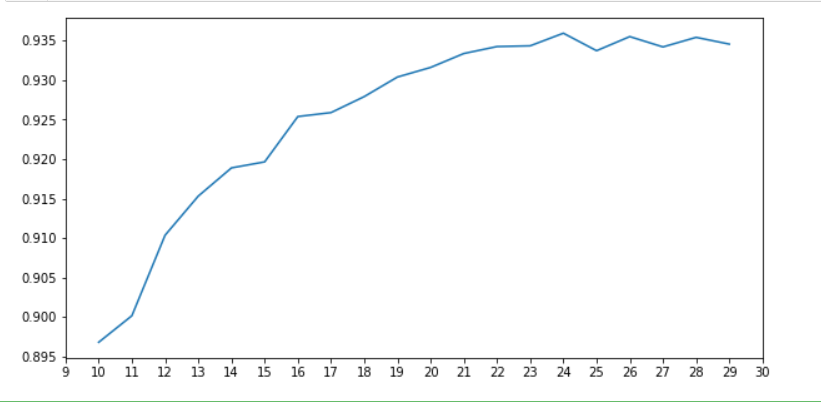
从图中可以看出,当n_components u003d 24时,模型的表选择是最好的
在确定了 PCA 的最佳参数后,我们需要对模型的参数进行调整,以将模型的性能推向最佳。关于随机森林的参数调整看我之前的博客。此处不显示参数调整。如果调整参数后模型的性能没有大幅度提升,可以考虑换一个模型。但是,改变模型可能会遇到的问题是:PCA降维可能需要再次进行。
KNN模型性能
# PCA降维后只有24个特征,与之前的784个特征相比
毫无疑问,少了很多。这里可以选择使用KNN模型来尝试
X_final u003d PCA(n_componentsu003d24).fit_transform(X)
knn u003d KNeighborsClassifier()
score u003d cross_val_score(knn, X_final, y, cvu003d10).mean()
打印(分数)# 0.971355806769633
PCA用于训练集和测试集
上面已经选择了 PCA 的参数。但是我们仍然有一个疑问。这就是如何使我的降维 PCA 适用于训练集和测试集。这里,将使用上述数据进行说明。
两种可能的想法
-
思路一:直接分别实例化PCA和重新训练妹子,在测试集上拟合_变换得到新的特征
-
思路2:实例化PCA,对训练集进行PCA训练,将训练好的PCA应用到训练集和测试集。
显然,第二种想法是正确的。这个思路可以参考模型训练应用的过程。
两种思路比较
训练集和测试集的划分
X_train, X\y_test, y_train, y_test u003d train\test\split(X, y, test_sizeu003d0.3, random_stateu003d3)
想法我结果
# pca 用于测试集而不是 fit 直接再训练集
************************ *******
pca_24 u003d PCA(n_componentsu003d24)
************************ ********
pca_X_train u003d pca_24.fit_transform(X_train)
pca_X_test u003d pca_24.fit_transform(X_test)
knn u003d KNeighborsClassifier()
knn.fit(pca_X_train, y_train)
分数 u003d knn.score(pca_X_test, y_test)
打印(分数)# 0.7936507936507936
很难想象它有 79% 的准确率。这是一个非常好的货物
之前的表现只有0.3左右。说明训练集和测试集的划分非常完美
思路二结果
# 拟合后的 pca
pca 用于测试集而不是 fit 直接再训练集
************************ ******************
pca_24 u003d PCA(n_componentsu003d24).fit(X_train)
************************ *******************
pca_X_train u003d pca_24.transform(X_train)
pca_X_test u003d pca_24.transform(X_test)
knn u003d KNeighborsClassifier()
knn.fit(pca_X_train, y_train)
分数 u003d knn.score(pca_X_test, y_test)
打印(分数)# 0.9691269841269842
对比两个结果可以看出,训练后应用pca显然是正确的方法。该模型的性能是一个质的飞跃。
总结
在这里,已经学习了 PCA 的基础知识。需要注意的是PCA参数的选择方法。使用 PCA 再训练集和测试集必须经过“训练”。使用 PCA 再训练集和测试集必须经过“训练”。使用 PCA 再训练集和测试集必须“训练”。重要的事情要重复 3 次。
欢迎在评论区和我一起讨论,互相学习

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 1
1 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)