【paddedetection奶妈教程】使用自定义数据集实现吸烟识别预测
桨检测
介绍
PaddleDetection 是一款基于 PaddlePaddle 的端到端目标检测开发套件,旨在帮助开发者在训练模型的整个开发、性能和推理速度优化、模型部署等方面提供帮助。 Paddedetection 提供了模块化设计的各种目标检测架构,并提供了丰富的数据增强方法、网络组件、损失函数等。 Paddedetection支持工业质量检测、遥感影像物体检测、自动检测等实用项目,具备模型等实用功能。压缩和多平台部署。
现在 PaddleDetection 中的所有模型都需要 1.8 或更高版本的 PaddlePaddle 或相应的开发版本。
GitHub地址:https://github.com/PaddlePaddle/PaddleDetection
特征
丰富的模型:
Paddedetection 提供了丰富的模型,包括 100 多个预训练模型,例如对象检测、实例分割、人脸检测等。它涵盖了冠军模型,一种适用于云和边缘设备的实用检测模型。
生产就绪:
关键操作用C++和CUDA实现,加上PaddlePaddle的高效推理引擎,可以轻松部署在服务器环境中。
高度灵活:
这些组件被设计成模块化的。模型架构和数据预处理管道可以通过简单的配置更改轻松定制。
性能优化:
借助基本的 PaddlePaddle 框架,我们可以加快训练速度并减少 GPU 的内存占用。值得注意的是,YOLOv3 的训练速度比其他框架快得多。另一个例子是掩码 RCNN (ResNet50)。在多 GPU 训练期间,我们尝试为每个 GPU(Tesla V100 16GB)容纳最多 4 个图像。
本项目实验步骤及结果
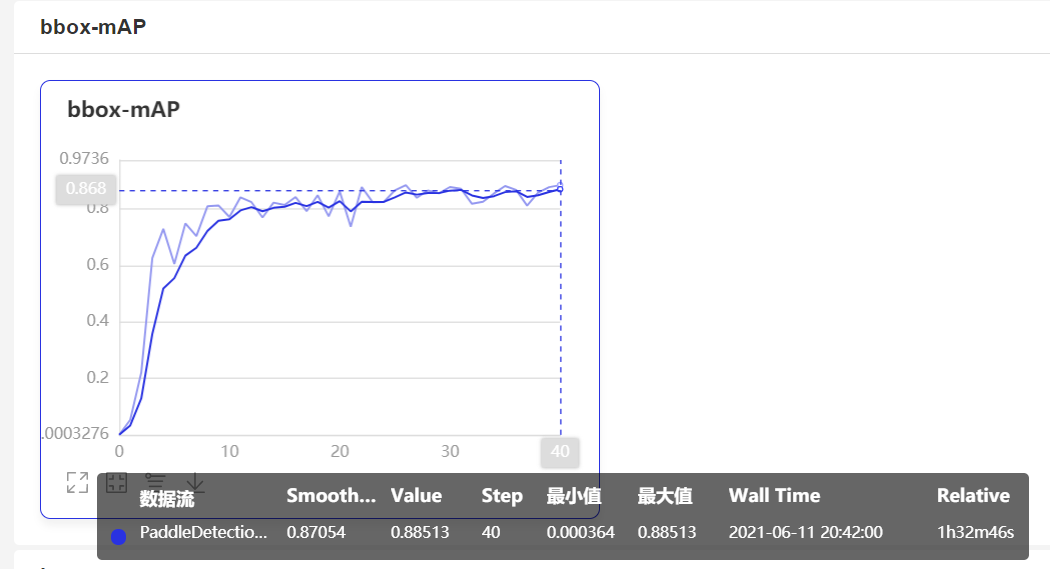
本实验在0中使用paddedetection2 Yolov3(主干网络是mobilenetv3的轻量级模型),通过几行代码就可以实现吸烟的目标检测。后期可部署监控公共场所非吸烟区,mAP值达到88.51%

实验步骤
1.解压自定义数据集;
2.下载安装paddedetection包;
3.用户定义的数据集分区;
4、选择模型(本次选择YOLO-v3)进行训练:训练配置文件说明;
5\。效果可视化:使用训练好的模型对结果进行预测和可视化;
6\。模型评估与预测:评估模型效果;
7\。预测结果
实验结果
检测效果如下图所示:


1 解压自定义数据集
标记的吸烟图片(VOC 数据集)将被解压缩。
建议上传压缩包
文件格式:
pp_somke:
——注解
1.xml
2.xml
.......
-图片:
1.jpg
2.jpg
.......
!unzip -oq 数据/data94796/pp_smoke.zip -d 工作/
2 下载安装paddedetection包
! git 克隆 https://gitee.com/paddlepaddle/PaddleDetection.git
克隆到 'PaddleDetection'...
远程:枚举对象:14575,完成。[K
远程:计数对象:100% (14575/14575),完成。[K
远程:压缩对象:100% (6264/6264),完成。[K
远程:总计 14575(增量 10732),重用 11456(增量 8175),打包重用 0[K
接收对象:100% (14575/14575), 132.71 MiB | 15.26 MiB/s,完成。
解决增量:100% (10732/10732),完成。
检查连接...完成。
3.用户定义数据集的划分
将数据集按照9:1的比例进行划分,生成训练集train Txt和验证集val.txt进行训练
进口随机
导入我们
#生成train Txt和val.txt
随机种子(2020)
xml_dir u003d '/home/aistudio/work/Annotations'#标签文件地址
img_dir u003d '/home/aistudio/work/images'#图片文件地址
路径_list u003d 列表()
对于 os.listdir(img_dir) 中的 img:
img_path u003d os.path.join(img_dir,img)
xml_path u003d os.path.join(xml_dir,img.replace('jpg', 'xml'))
path\list.append((图像路径,xml\path))
random.shuffle(路径_list)
比率 u003d 0.9
train_f u003d open('/home/aistudio/work/train.txt','w') #生成训练文件
val_f u003d open('/home/aistudio/work/val.txt' ,'w')#生成验证文件
对于 i ,枚举中的内容(路径_list):
img, xml u003d 内容
文本 u003d img + ' ' + xml + '\n'
如果 i < len(path_list) * 比率:
火车_f.write(文本)
其他:
val_f.write(文本)
火车_f.close()
val_f.close()
#生成标签文档
label u003d ['smoke']#设置你要检测的类别
with open('/home/aistudio/work/label_list.txt', 'w') as f:
对于标签中的文本:
f.write(文本+'\n')
%cd 桨检测
/home/aistudio/PaddleDetection
4.训练选择模型(本次选择YOLO-v3):训练配置文件说明
选择模型后,用户只需要更改相应的配置文件并运行train Py文件,即可实现训练。
本项目使用YOLOv3模型中的YOLOv3_mobilenet_v3_large_ssld_270e_voc。 YML培训
4.1 配置文件示例
我们使用 configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml 配置进行训练。
在 paddedetection2 0 中,模块化更好。您可以自由修改和覆盖各个模块的配置,自由组合。
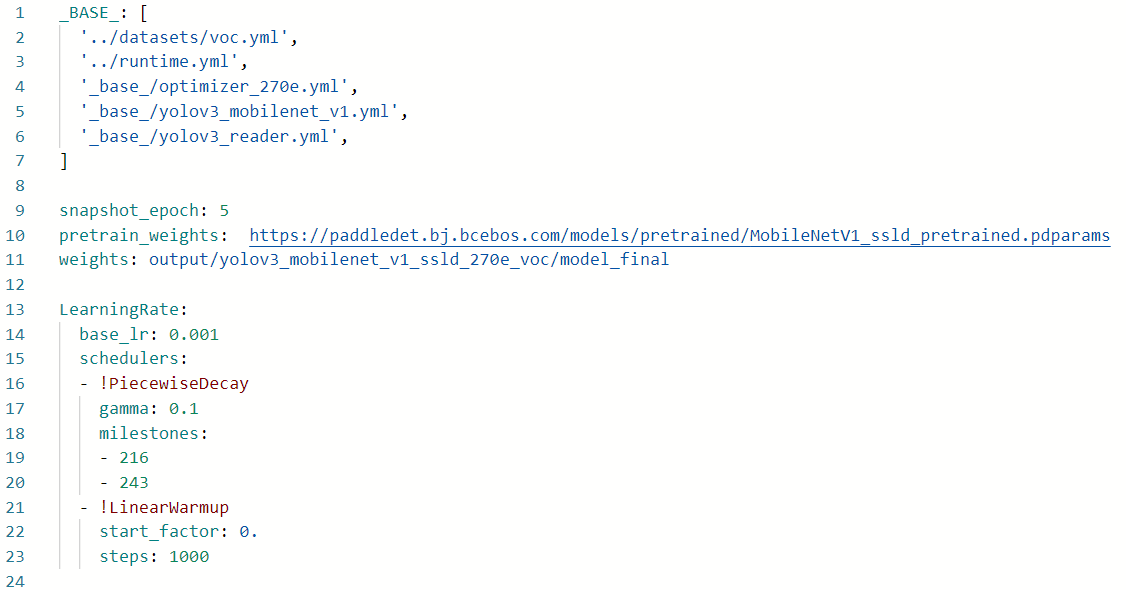
配置文件结构说明
4.2 配置文件详细说明
从上图中可以看到yolov3_mobilenet_v3_large_ssld_270e_voc。 YML 配置依赖于其他配置文件。在这个例子中,你需要依赖:

在修改文件之前,先解释一下各个依赖文件的作用:
'../datasets/voc.yml'主要说明训练数据和验证数据的路径,包括数据格式(coco,voc等)
'../runtime.yml',主要描述公众的运行状态,比如是否使用GPU,迭代轮数等
'_base_/optimizer_270e.yml',主要描述学习率和优化器epochs的配置和设置。在其他训练配置中,学习率和优化器被放置在一个新的配置文件中。
'_base_/yolov3_mobilenet_v3_large.yml',主要描述模型,骨干网络
'_base_/yolov3_reader.yml',主要描述读取后的预处理操作,如resize、数据增强等。
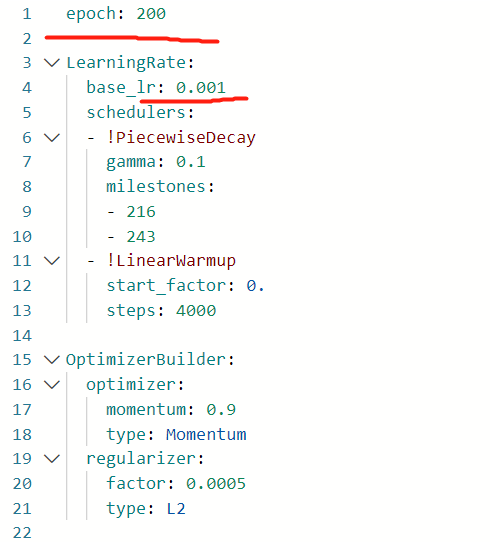
介绍几个需要修改的地方(红线处):
.../datasets/voc.yml

基础/优化器_270e.yml
配置文件结构说明
4.3 执行力训练
执行以下命令快速训练并开始vdl录制
!python 工具/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml --eval --use_vdlu003dTrue --vdl_log_diru003d"./输出”
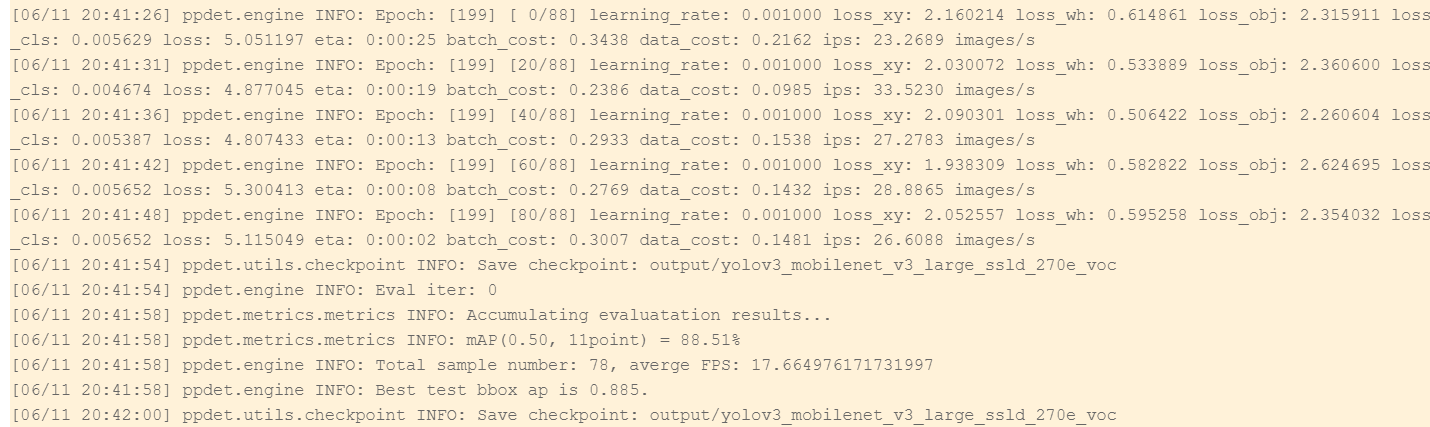
5.效果可视化:使用训练好的模型同时预测和可视化结果
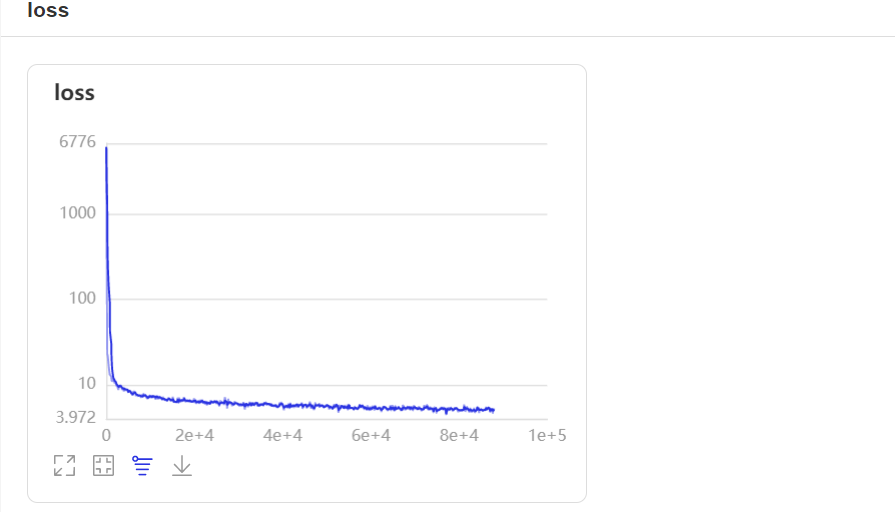
当打开使用_VDL开关后,paddedetection会将训练过程中的数据写入VisualDL文件,可以实时查看训练过程中的日志。记录的数据包括:
1.亏损趋势
2.mAP变化趋势
使用以下命令启动 VisualDL 以查看日志
# 下面的命令会在127.0.0.1上启动一个服务,支持通过前端网页查看。可以通过--host参数指定实际的ip地址
visualdl --logdir 输出/
在浏览器中输入提示的网址。效果如下:
visualdl --logdir 输出/
文件“<ipython-input-68-4b7c990a0c4d>”,第 1 行
visualdl --logdir 输出/
^
SyntaxError: 无效的语法
如果上面的代码没有执行成功,可以通过左侧界面控件查看
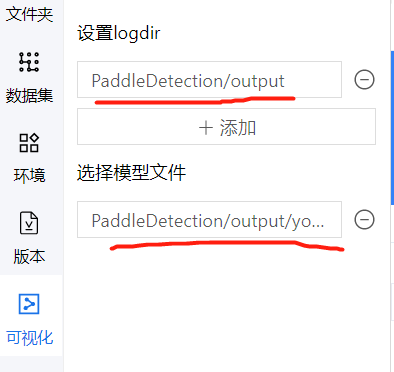
具体操作可以查看本网站:https://my.oschina.net/u/4067628/blog/4839747(第3步)
6.模型评估
python -u 工具/eval.py -c 配置/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \
-o 权重u003d输出/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
!python -u 工具/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weightsu003doutput/yolov3_mobilenet_v3_large_ssld_270e_voc /最佳_model.pdparams

7.模型预测
执行 tools/infer py 后,会在输出文件夹中生成对应的预测结果
python 工具/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml \
-o 权重u003d输出/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams \
--infer_imgu003ddataset/113.jpg(待检测图片)
!python 工具/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weightsu003doutput/yolov3_mobilenet_v3_large_ssld_270e_voc/best _model.pdparams --infer_imgu003d/home/aistudio/work/xiayan2.jpg
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object`是内置 `object`的已弃用别名。要消除此警告,请单独使用 `object`。这样做不会修改任何行为并且是安全的。
在 NumPy 1.20 中已弃用;有关更多详细信息和指导:https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
如果 data.dtype u003du003d np.object:
W0611 21:05:17.302584 21170 device_context.cc:404] 请注意:设备:0,GPU 计算能力:7.0,驱动程序 API 版本:10.1,运行时 API 版本:10.1
W0611 21:05:17.307160 21170 设备_context.cc:422] 设备:0,cuDNN 版本:7.6。
[06/11 21:05:21] ppdet.utils.checkpoint INFO:完成加载模型权重:输出/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
[06/11 21:05:21] ppdet.engine INFO: 检测 bbox 结果保存在 output/xiayan2.jpg
-结果展示
原图


预测图


总结
从上图可以看出,使用paddedetection已经完成了吸烟的目标识别和检测,mAP达到了88.51%。
优化方案
可以通过添加数据集和选择更优化的模型来增加训练次数。
逾期申请
识别后可以添加语音。如果识别到有人在吸烟,可以发出语音警告
后期可部署到非吸烟区公共场所的监控,检测吸烟等物品。
详细请看paddedetection的详细教程:
https://translate.google.com/translate?hl=en&sl=auto&tl=zh&u=https://paddledetection.readthedocs.io/tutorials/GETTING_STARTED_cn.html
关于作者
感兴趣的方向有:目标检测、分类任务等
AIstudio首页:我在AI Studio中获得白银级,点亮3个徽章相互关闭~我在AI Studio中获得黄金级,点亮7个徽章相互关闭~
https://translate.google.com/translate?hl=en&sl=auto&tl=zh&u=https://aistudio.baidu.com/aistudio/personalcenter/thirdview/474269
Github 主页:https://github.com/Niki173
欢迎大家留言提问,交流学习,共同进步,共同成长。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)